一、前言
长尾问题是分布式计算里最常见的问题之一,也是典型的疑难杂症。究其原因,是因为数据分布不均,导致各个节点的工作量不同,整个任务就需要等最慢的节点完成才能完成。处理这类问题的思路就是把工作分给多个Worker去执行,而不是一个Worker单独抗下最重的那份工作。
如何查看是否发生了长尾?发生在什么阶段?
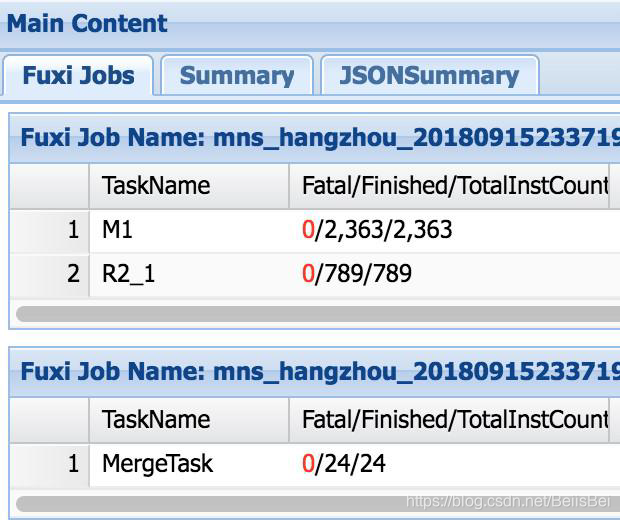
Maxcompute 任务 = 1 … N Fuxi Job
Fuxi Job = 1 … N Fuxi Task
Fuxi Task = 1 … N Fuxi Instance
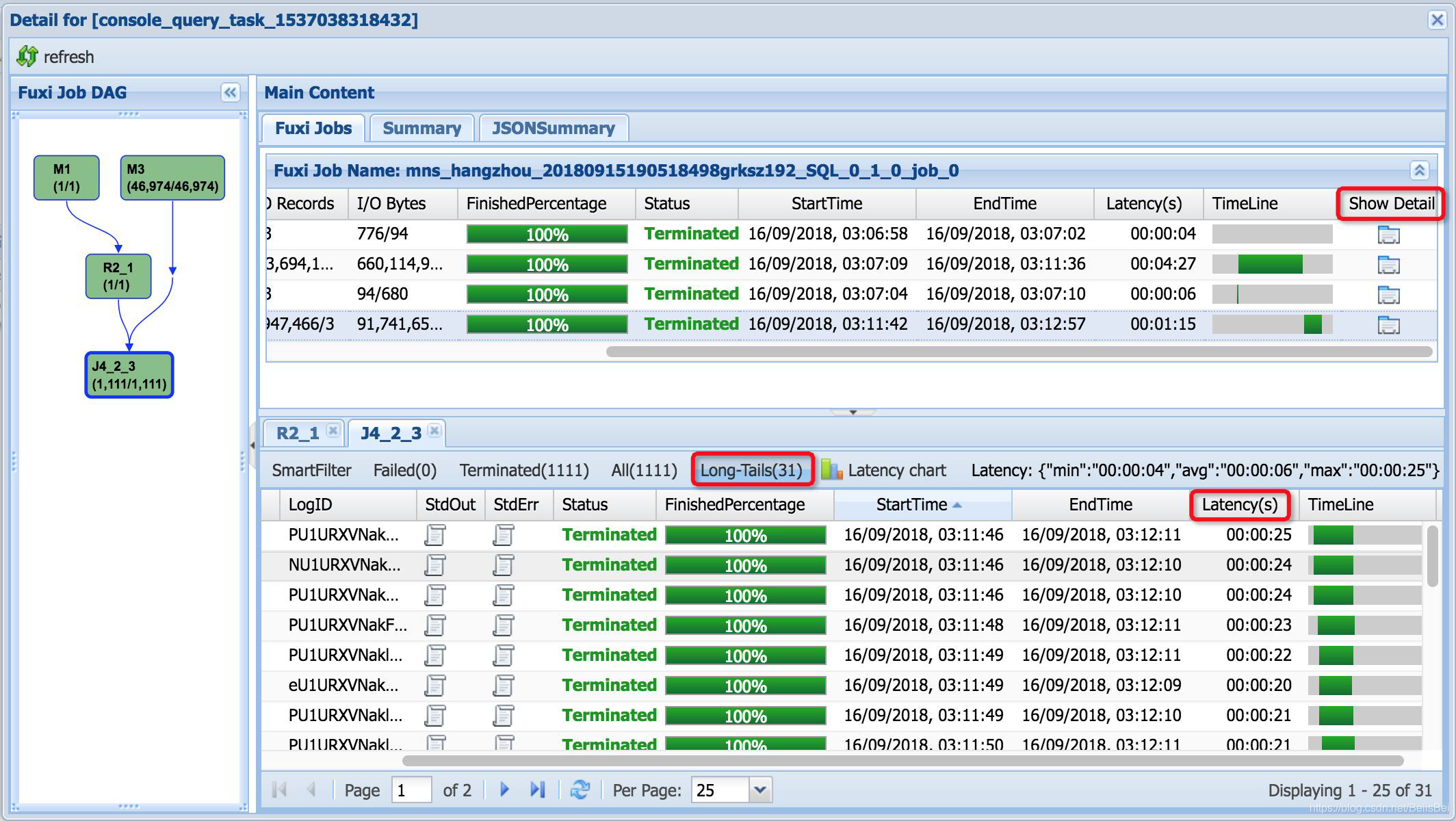
如果看到Long-Tails,就说明发生了长尾。
二、长尾的原因
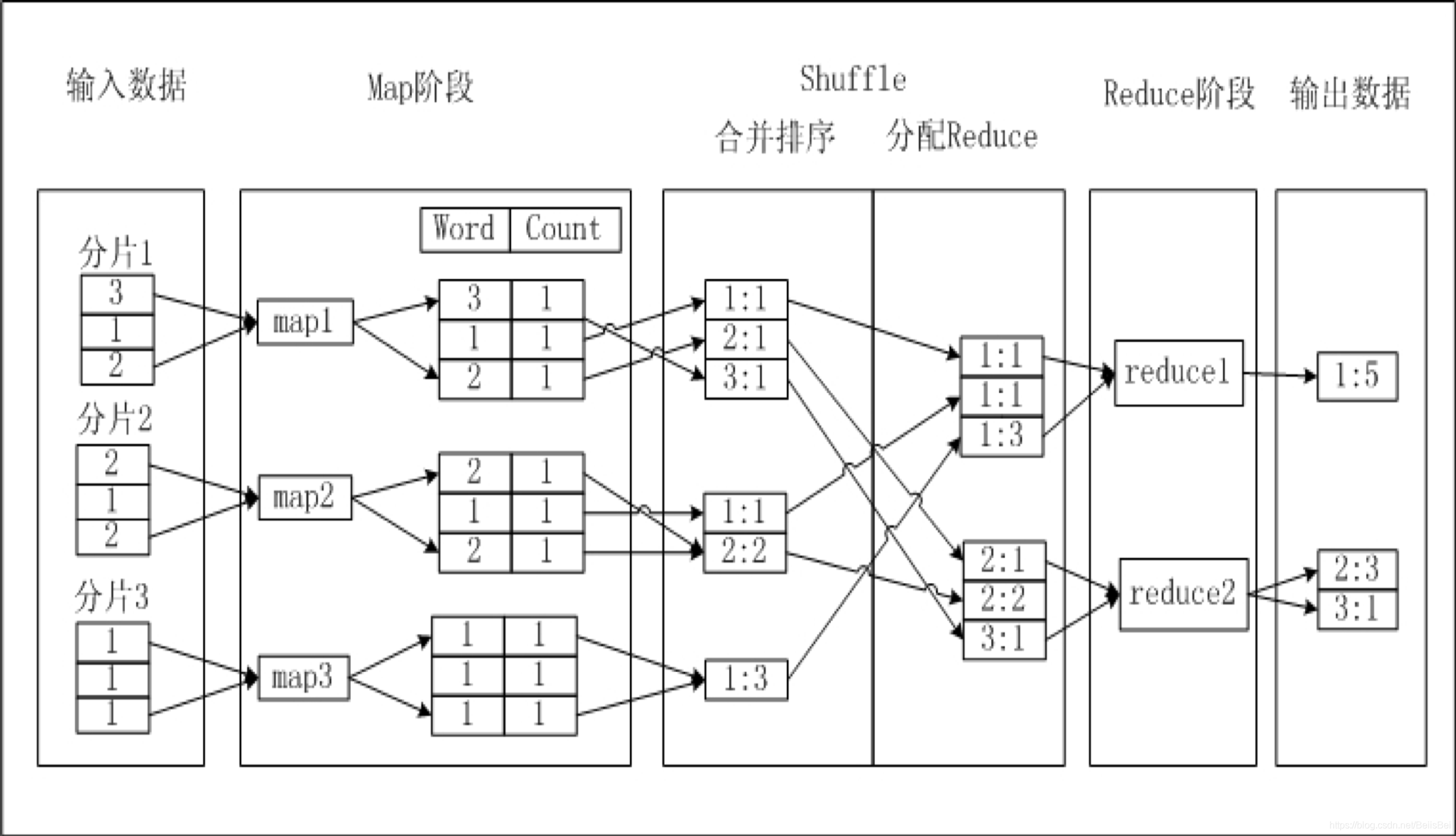
原因:某些 instance(可能是map, 也可能是reduce) 处理的数据量远远超过其他 instance 处理的数据量,这些instance的运行时长远远超过其他instance的平均运行时长,导致整个任务运行时间超长,造成任务延迟。
举例:
select
key,
count(*) as cnt
from
table
group by key;
三、优化思路与解决方案
3.1 Group By 长尾
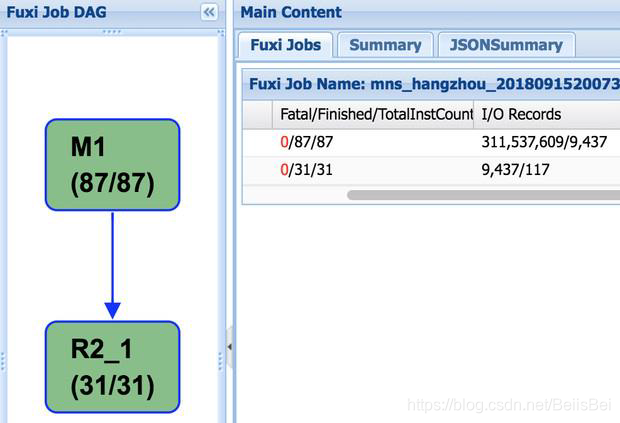
M1->R2_1
• M1 做 local combiner
• M1 输出 shuffle hash(hash(key)/N), 分发到R2_1
• R2_1 做最终汇总
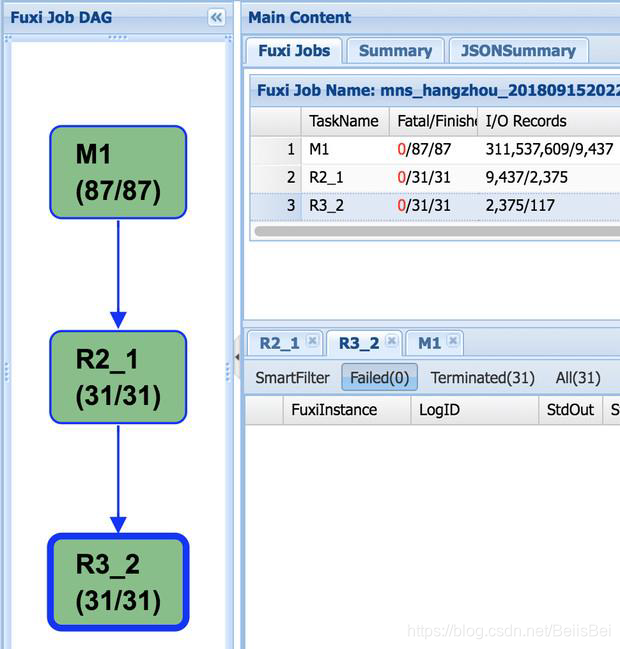
M1->R2_1->R3_2
• M1 做 local combiner
• M1 输出 shuffle hash (算法加入随机因素),更均匀分发到 R2_1
• R2_1 做 partial combiner
• R2_1 输出shuffle hash(hash(key)/N), 分发到 R3_2
• R3_2 做最终汇总
解决方案:
set odps.sql.groupby.skewindata=true;
注意:
- 此参数 仅对 group by 有效
- 由于多引入一个R,所以会有额外的资源消耗。
若长尾并不严重,用这种方法人为增加一次 R ,最终的时间消耗可能反而更大。
场景:火爆商品售卖,根据商品算pv/uv
3.2 count distinct 长尾
场景:计算商品购买uv,固定的特殊值比较多
select
count(distinct userid) as cnt
from table;
select
count(tmp) as cnt
from
(select count(*) as tmp from table group by userid) a;
解决方案:
- 避免使用distinct,使用group by改造语句,开启groupby.skewindata。注意:引入R,会有额外资源消耗。
- 先过滤特殊值,count完后,在结果上加上特殊值的个数。注意:根据具体场景进行具体分析。
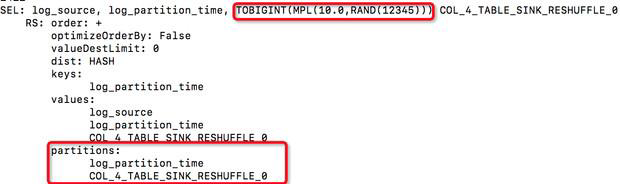
3.3 动态分区 长尾
insert into table yftest partition(log_partition_time) select log_source,log_partition_time from access;
假设 N个 Map instance,M个分区,那么可能产生 NxM 个小文件:
Inst1 ds1
Inst2 ds2
Inst3 X …
… dsM
instN
——》
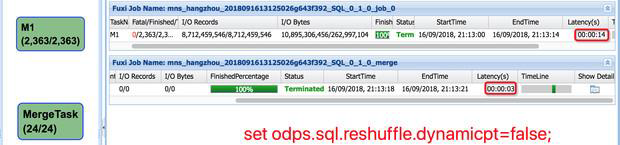
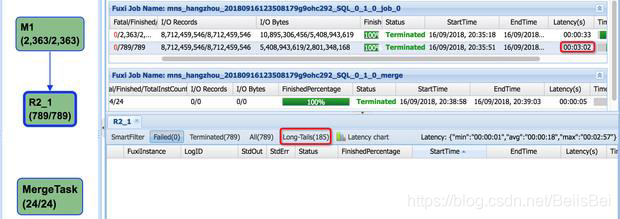
解决方案:
如果目标分区不多,建议先关闭reshuttle;
任务执行完毕后,手动执行MergeTask,
减少小文件。
3.4 Join 长尾
Join会被解释成一个MapReduce任务,Map端分别读取join两边表的数据,Reduce做Join操作。
举例:
select a.*, b.name from list a left outer join dic b on a.item_id=b.item_id;
解决方案一:使用MAPJOIN
原理:
Join在Map端做。 把小表放到每个Map中,这样每个Map都拥有小表所有记录,可以在本地进行Join。
select /*\+ MAPJOIN(b) \*/ a.*, b.name from list a left outer join dic b on a.item_id=b.item_id;
限制:
所有小表占用的内存总和不得超过512MB
Join会被解释成一个MapReduce任务,Map端分别读取join两边表的数据,Reduce做Join操作。
举例:
select a.*, b.name from list a left outer join dic b on a.item_id=b.item_id
解决方案二:分而治之
select a.*, b.name from list a join dic b on a.item_id=b.item_id;
Step 1: 找出常用item范围
create table yf_list_sub as
select a.item_id.a.cnt,b.name
from
(
select item_id,count(*) as cnt
from list a
group by item_id
order by cnt desc limit 100
) a
join
(
select name
from dic
) b
on a.item_id=b.item_id
Step 2: 常用item先关联
create table fy_result_tem as
select /*+ MAPJOIN(b) */ a.*, b.name
from dic a
left outer join
yf_list_sub b
on a.item_id = b.item_id;
create table result_part1 as
select * from yf_result_tem
where name is not null;
Step 3: 非常用item后关联
create table result_part2 as
select
a.item_id,
b.name
from
(
select *
from yf_result_tem
where name is null
) a
join
(
select *
from dic
) b
on a.item_id=b.item_id;
Step 4: union all
create table result as
select * from
(
select a.item_id,b.name
from result_part1
union all
select a.item_id,b.name
from result_part2
) t