学过爬虫的朋友知道,requests库和BeautifulSoup4库可以爬取80%多的数据,但是还有少部分数据通过这两个库无法获取,所以今天介绍另外一个爬虫工具——Scrapy框架。
1.Scrapy框架介绍
- Scrapy是用python实现的一个用于爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 用户只需要定制开发几个模块就可以轻松实现数据、图片等的爬取,非常方便。
- Scrapy采用Twisted异步网络框架来处理网络通讯,可以加块下载速度。
2.Scrapy安装
在pychram中安装Scrapy,仍然可以在命令行中输入pip install scrapy
3.项目新建
安装好Scrapy之后,我们在pycharm界面下面找到Terminal,点击之后出现如下窗口,在希望创建的目录下输入scrapy startproject mytest1:
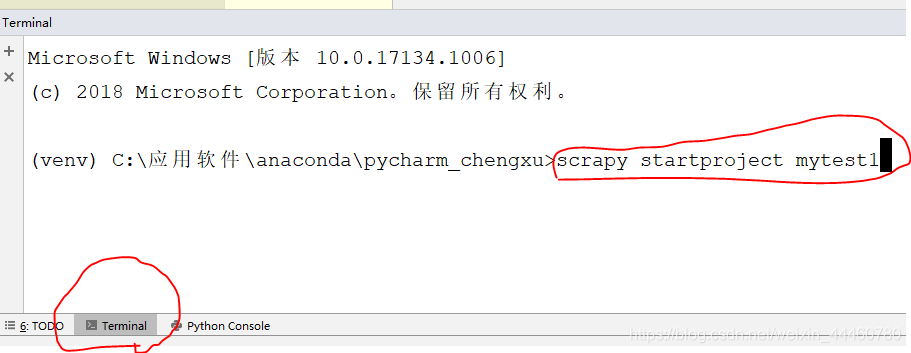
按enter键后,出现如下界面,表示项目创建成功:

项目成功创建之后,就会出现项目名为mytest1的文件(如下图),该文件下包含多个.py文件。
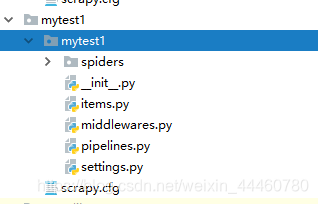
_init_py: 存放用户需要爬虫数据的属性,比如爬电影时,评分,电影名这些就在这个文件定义
items.py: 对数据进行封装
middlewares.py: 爬虫的中间健,主要用于一些反爬虫的设置
pipelines.py: 爬虫的管道,对items.py封装的数据进行处理
settings.py: 爬虫的一些设置,比如设置反爬虫、代理等
4.开始爬虫
下文以爬取慕课网下各课程网址、课程名、课程图片以及课程介绍为例进行讲解。
1. 定义爬虫数据的属性
首先打开items.py文件,一般建完项目后,Items.py中会默认有一个以项目名为类名的类,不过类名可以更改,不影响爬虫。因为要爬取各课程网址、课程名、课程图片以及课程介绍,所以需要定义四种属性。
import scrapy
#定义爬取数据的属性
class CourseItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
image_url=scrapy.Field()
introduction=scrapy.Field()
student = scrapy.Field()
image_path = scrapy.Field()
2.开始爬虫
在项目中spiders文件下新建一个python文件Myspider.py,该文件是爬虫的核心,用户需要在里面写爬虫具体代码。首先导入Scrapy模块,同时需要导入第一步中的CourseItem类,因为我们需要用到CourseItem类定义的属性。注意,之后运行程序不是使用项目名,而是使用name,然后写爬虫网址的域名,以及爬取网页的网址,这三步是固定的,必须要写。 在parse函数中,首先创建CourseItem类对象,在Scrapy框架中,使用xpath来获取标签内容。关于xpath的具体用法见博客Scrapy中Xpath选选择器的基本用法
import scrapy
from ..items import CourseItem
class MySpider(scrapy.Spider):
name="MySpider"
#所爬网址的域名
allowed_domains =['imooc.com']
#爬取的网页
start_urls=['http://www.imooc.com/course/list']
def parse(self, response):
item =CourseItem()
for box in response.xpath('//div[@class="course-card-container"]/a[@target="_blank"]'):
# 获取每个div中的课程路径
item['url'] = 'http://www.imooc.com' + box.xpath('.//@href').extract()[0]
# 获取div中的课程标题
item['title'] = box.xpath('.//h3/text()').extract()[0].strip()
# 获取div中的标题图片地址
item['image_url'] = 'http:' + box.xpath('.//@data-original').extract()[0]
# 获取div中的学生人数
item['student'] = box.xpath('.//div[@class="course-card-info"]/span[2]/text()').extract()[0].strip()
# 获取div中的课程简介
item['introduction'] = box.xpath('.//p[@class="course-card-desc"]/text()').extract()[0].strip()
# 返回信息
yield item
#url跟进
url = response.xpath("//a[contains(text(),'下一页')]/@href").extract()
print("==========",url)
if url:
page = "http://www.imooc.com"+url[0]
yield scrapy.Request(page,callback=self.parse)
3.数据的处理
我们在爬完数据之后,需要把数据保存起来,在pinelines.py中进行处理数据,需要导入相应的包,一般建议加上编码方式,防止出现乱码。
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
import json
class MyPipeLine():
def __init__(self):
self.file =open('C:\\QQ\\data.json','w',encoding='utf-8')
# 该方法用于处理数据
def process_item(self, item, spider):
# 读取item中的数据
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
# 写入文件
self.file.write(line)
# 返回item
return item
# 该方法在spider被开启时被调用。
def open_spider(self, spider):
pass
# 该方法在spider被关闭时被调用。
def close_spider(self, spider):
pass
class ImgPipeline(ImagesPipeline):
# 通过抓取的图片url获取一个Request用于下载
def get_media_requests(self, item, info):
# 返回Request根据图片图片url下载
yield scrapy.Request(item['image_url'])
# 当下载请求完成后执行该方法
def item_completed(self, results, item, info):
# 获取下载地址
image_path = [x['path'] for ok, x in results if ok]
print("==================",image_path)
# 判断是否成功
if not image_path:
raise DropItem("Item contains no images")
# 将地址存入item
item['image_path'] = image_path
return item
class ScrapytestPipeline(object):
def process_item(self, item, spider):
return item
4.设置
我们在爬虫结束之后,一定要注意对项目中的settings.py进行相应的修改设置,一方面是可以防止程序运行出错,同时通过设置代理、Robots排除协议,可以对一些不让爬虫的网站可以进行数据爬取。
ROBOTSTXT_OBEY = False #修改robots协议
CONCURRENT_ITEMS=50 #每次爬取数量
#数值越小,优先级越高,由于图片下载较慢,所以优先级最高
ITEM_PIPELINES = {
'scrapytest.pipelines.ScrapytestPipeline': 300,
'scrapytest.pipelines.MyPipeLine':2 ,
'scrapytest.pipelines.ImgPipeline': 1,
}
IMAGES_STORE = 'C:\\QQ\\'
5.运行
同样点击Terminal,cd进入所在文件项目,注意后面加的是Myspider.py中的name

运行之后,数据被保存在C盘QQ文件夹下的data.json中,数据如下面截图这样,这样就完成了一个完全的爬虫。

另外,有时候如果一直爬某个网站,该网站可能就会对该IP进行封号,所以在爬虫时可以设置爬虫间隔,就是爬一会停一会sleep()函数,同时可以在settings里面设置一下代理IP(https://www.kuaidaili.com/free/inha/,保证爬虫顺利进行。
个人感觉这个比requests和BeautifulSoup4还麻烦,不过听说这个框架是固定的,以后爬数据的时候,只需要改一下xpath中的标签,网上类似的模板也有很多,?爬虫也只是第一步,之后的数据分析处理才是头疼的事。
个人拙见,有需要改正的麻烦评论区留言,我会更新的。?