作为一款来自于学校教学数据库的开源数据库项目,在功能上以及数据库特性等方面 近似oracle,远胜MySQL。下面详细的分析一下Postgres中不甚完善的设计实现之vacuum机制。它对应于其他数据库(MySQL或oracle)的UNDO表空间。
注:undo表的主要作用:当事务回滚的时候,可以直接取到修改前的数据块(这是一个随机读的过程)。MVCC的最大特点:读写不再相互阻塞,读不会阻塞写,写也不会阻塞读。它的意义在于:在最早的数据库理论里,行上的锁有两种:读锁与写锁,当要访问一行数据的时候,如果是select,会获取读锁,读锁会阻塞写锁,但不会阻塞读锁;当有update或者delete发生的时候,如果已经有select,那么修改行为会等到前面的select执行完之后才执行,而反过来,如果有一行正在被update,那么对这一行所有的select就都会被阻塞,直到这个修改完成提交。这样一来,很明显有一个问题,就是读会阻塞写,写也会阻塞读,而且单行来看代价小,但如果视线扩展到整个数据库,假设是一个比较繁忙的数据库,这种对某一行的锁,就会带来很糟糕的问题了。
MVCC
多版本并发控制机制,其指导思想 是:与其锁定数据行,不如让写入去写这一行新的版本,而需要读的时候,在新行提交之前(假设隔离级别是Read Commited),直接去读老的行数据,这样既保证隔离性,也让读写可以不要相互锁定。当然,对同一行的写,永远是排他性的,写必然会阻塞写。
其代表实现有:Oracle的Undo机制,以及模仿其实现的MySQL InnoDB Undo等
InnoDB的undo机制
MySQL中,每个事务都会被分配到一个事务id,这个事务id是全局自增的数字,保证新事务的id必然大于旧事务id,然后这个id也会作为一个读视图id去用来读取数据。
每当发生数据写入(delete或者update),InnoDB会做一个操作:把旧行做一个删除标记,然后带着当前的事务id插入新行(由于是索引组织表,需要保证必须在同一个数据块中)。这个操作本身,一是会把修改本身写入redo;二是会让这个数据块被记录到undo,而undo表空间的写入,也会生成一个对应的redo,写入到redo。也就是说:每次数据修改,会产生两个redo记录(对于insert来说,由于数据前镜像是空,所以并没有第二个undo对应的redo生成,也就是只产生一个redo记录)。
当上面的修改期间,有读行为过来的时候,读的游标就会直接去读undo中的老数据,而不会去求正在被修改的数据的锁。而为了实现隔离级别(可重复读级别),事务id的作用在于:如果一个数据块在事务开始后才被修改并提交了,当游标读取到这里,会扫到当前数据块里面所有在这期间被修改并提交的行,读取到对应行id小于事务id的数据。
那么这么多的老数据会在什么时候被彻底删除呢?MySQL中有个purge机制,这些线程的工作就是:对于数据对应的事务id已经比当前数据库最老的事务还小,并且被标记为删除的数据进行清理。注:在MySQL的一些新版本中,这个工作是多线程并行执行的。
vacuum机制实现的mvcc
在我们PG中,是没有UNDO的。基本实现上:和MySQL是一致的,也是每个update和delete,都会对老行搞一个删除标记作为"死亡"记录,然后带着当前的事务id写入对应的行,这个过程中对数据块的修改会记录为redo。实例如下图所示:
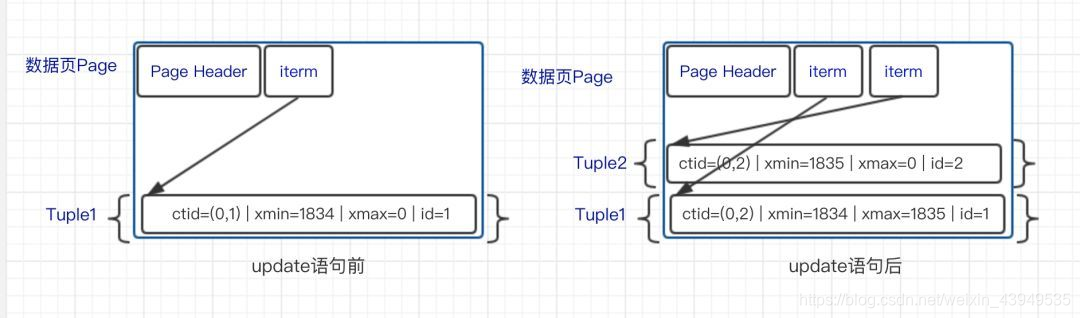
相对应于MySQL的清理,pg是由vacuum,回收已经不需要的记录占据的空间。
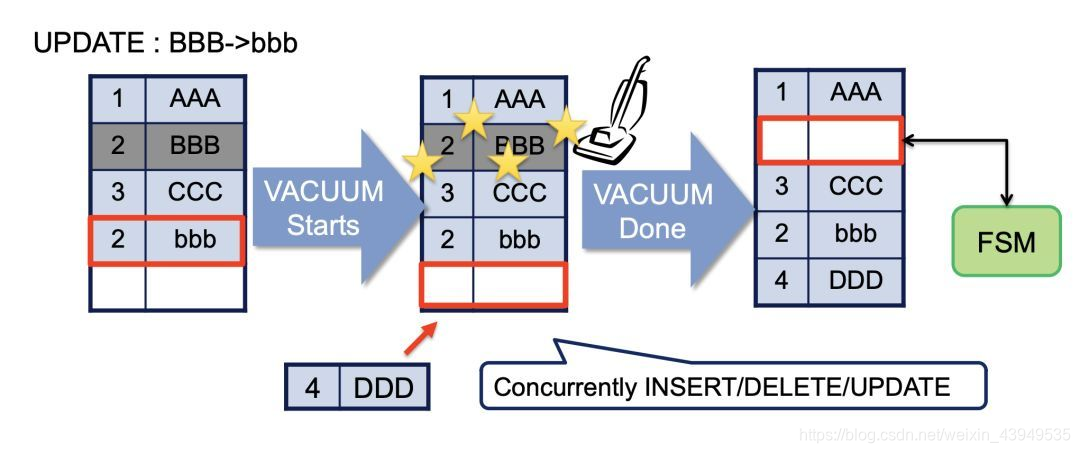
而这里需要注意的一点是:MySQL在MVCC实现机制要比PG轻松或者容易很多。
究其原因在于:32位的事务id
看一下背景:如果是一个每秒钟1000个事务的数据库,不到50天就可以耗光事务id。对于比较繁忙的库,比如平均每秒钟10000事务来说,4天就可以耗光。事实上,PG的最新事务和最老事务的差不能超过2*31也就是20亿,这个时间范围还需要减半。
其计算公式: (2的32/24/3600/1000=49天)
首先对于事务id续上,pg的方式:如果到达限制,则从头开始继续算数字。但是这么处理之后,就不能单纯通过比较数据的事务id大小来区分可见性了(重置id之后的事务id必然小于重置前)。PG在这里,引入了名为"冻结"的概念:当重置的时候,会对当前所有数据表的行进行一遍冻结标,设置其为可以对任意事务可见。这样重置事务id之后,如果新的事务访问到这个表,就直接可以访问到所有需要的数据了。

而PG另外一个问题,就是垃圾回收:在单表上只能串行地vacuum,对超大的单表处理时候,会有非常漫长的处理时间。并且期间的IO消耗以及cpu消耗,会极大地影响到所在的服务器的性能。
PG发起vacuum的启动流程
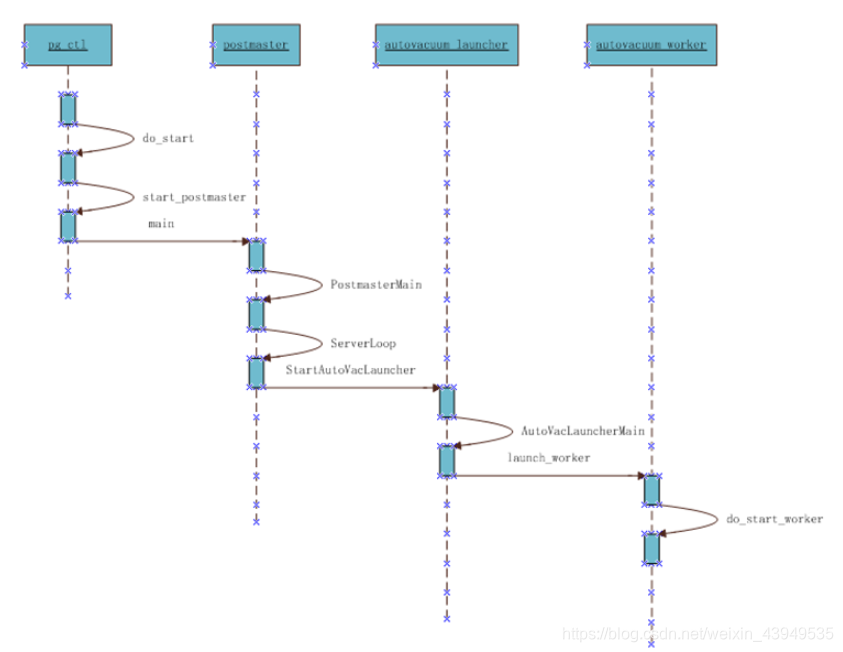
如上图所示:pg_ctl命令行起动PG实例,然后fork出postmaster Server进程,这也是PG的主进程。postmaster进程再负责fork各种其它后台进程。按以下顺序,依次起动:logger进程,checkpoint进程,writer进程,wal writer进程,autovacuum launcher进程以及stats collector进程。
然后由autovacuum launcher进程再负责fork autovacuum worker进程。我们具体的vacuum动作最后都交由worker进程来做。
其中autovacuum launcher是vacuum worker的总调度者。在起vacuum worker时,会先balance一次vacuum_cost_limit值,balance的过程就是新的worker起来时,赋予此worker后面因vacuum而消耗的最大允许IO limit。因为vacuum_cost_limit值是所有worker平摊的,我们设置的vacuum_cost_limit是所有worker的总累加值。因此新的work加入进来后,需要做两件事:一是计算新的work的cost_limit值;二是调整已经在running的worker的cost_limit值。
注:虽然可以几个worker一起运行,但是目前的做法是,在db 级别并行。也就是说worker是根据autovacuum launcher重建的db list去逐一遍历每个DB的。
vacuum 机制及实现原理
上面也说了PG并没有像Oracle那样的undo来存放旧版本;而是将旧版本直接存放于relation文件中。那么带来的问题就是dead tuple过多,导致relation文件不断增大而带来空间膨胀问题。为了解决这个问题,PG中引入了vacuum后台进程,专门来清理这些dead tuple,并回缩空间(毕竟有大量的磁盘空间浪费和导致系统性能下降的代价)。下面总结一下vacuum的功能有哪些?
-
回收空间
回收空间,将dead tuple清理掉。但是已经分配的空间,一般不会释放掉。除非做vacuum full,但是需要exclusive lock。一般不太建议,因为如果表最终还是会涨到这个高水位上,经常做vacuum full意义不是非常大。一般通过合理设置vacuum参数,进行常规vacuum也就够了。 -
冻结tuple的xid
上面也详细说过了:PG会在每条记录(tuple)的header中,存放xmin,xmax信息(增删改事务ID)。然而transactionID的最大值为2的32次(即无符整形来表示)。当transactionID超过此最大值后,会循环使用。这会带来的一个问题:就是最新事务的transactionID会小于老事务的transactionID。如果这种情况发生后,PG就没有办法按transactionID来区分事务的先后,也没有办法实现MVCC了。因此PG用vacuum后台进程,按一定的周期和算法触发vacuum动作,将过老的tuple的header中的事务ID进行冻结。冻结事务ID,即将事务ID设置为“2”(“0”表示无效事务ID;“1”表示bootstrap,即初始化;“3”表示最小的事务ID)。PG认为被冻结的事务ID比任何事务都要老。这样就不会出现上面的这种情况了。 -
更新统计信息
vacuum analyze时,会更新统计信息,让PG的planner能够算出更准确的执行计划。autovacuum_analyze_threshold和autovacuum_analyze_scale_factor参数可以控制analyze的触发的频率。
-
更新visibility map
在PG中,有一个visibility map用来标记那些page中是没有dead tuple的。这有两个好处:一是当vacuum进行scan时,直接可以跳过这些page。二是进行index-only scan时,可以先检查下visibility map。这样减少fetch tuple时的可见性判断,从而减少IO操作,提高性能。另外visibility map相对整个relation,还是小很多,可以cache到内存中。
根据用户输入的命令的不同:
- Full VACUUM :它会对表进行完全清理
- Lazy VACUUM:它仅标记无效数据空间为可用
详细分解:
整表清理:将会使空间释放的信息表现在系统级别,其实质是将当前删除记录后面的数据进行移动,使得整体的记录连贯起来。需要获得排它锁,它通过“标记-复制”的方式将所有有效数据(非dead tuple)复制到新的磁盘文件中,并将原数据文件全部删除,并将未使用的磁盘空间还给操作系统,因此系统中其它进程可使用该空间,并且不会因此产生磁盘碎片。
标志可用:只是将删除状态的空间释放掉,转换到能够重新使用的状态。该操作并不要求获得排它锁,因此它可以和其它的读写表操作并行进行。同时它只是简单的将dead tuple对应的磁盘空间标记为可用状态,新的数据可以重用这部分磁盘空间。但是这部分磁盘并不会被真正释放,也即不会被交还给操作系统,因此不能被系统中其它程序所使用,并且可能会产生磁盘碎片。
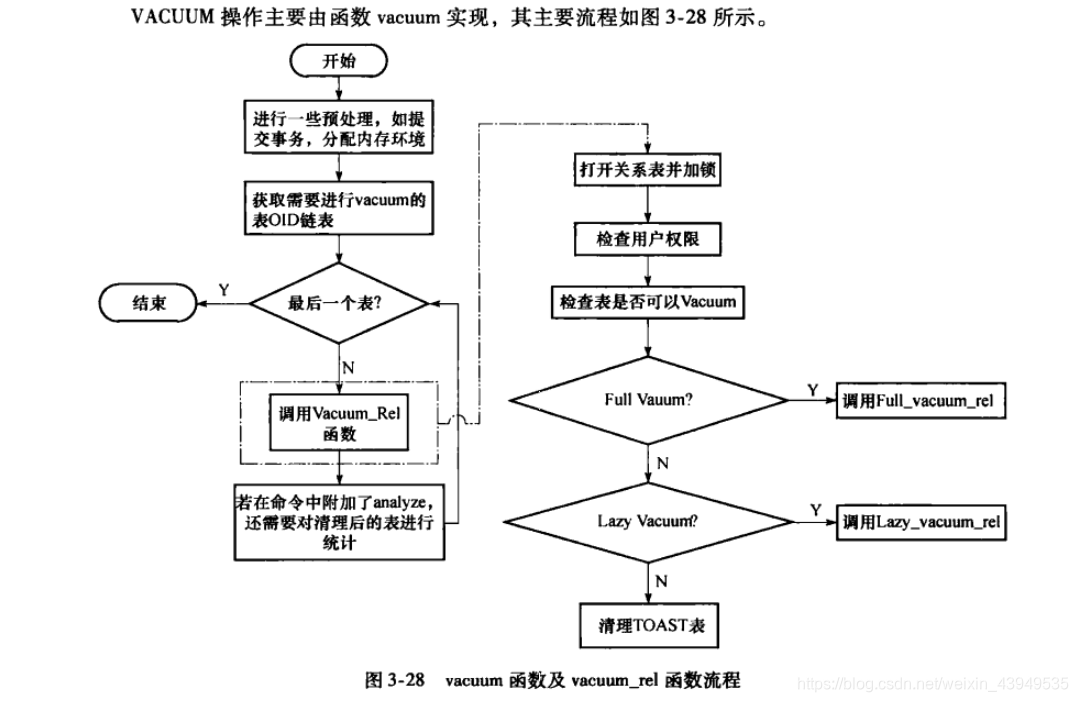
如上图所示:输入命令不同,在vacume_rel函数具体调用不同的类型处理函数。下面对两种方式做进一步分析:
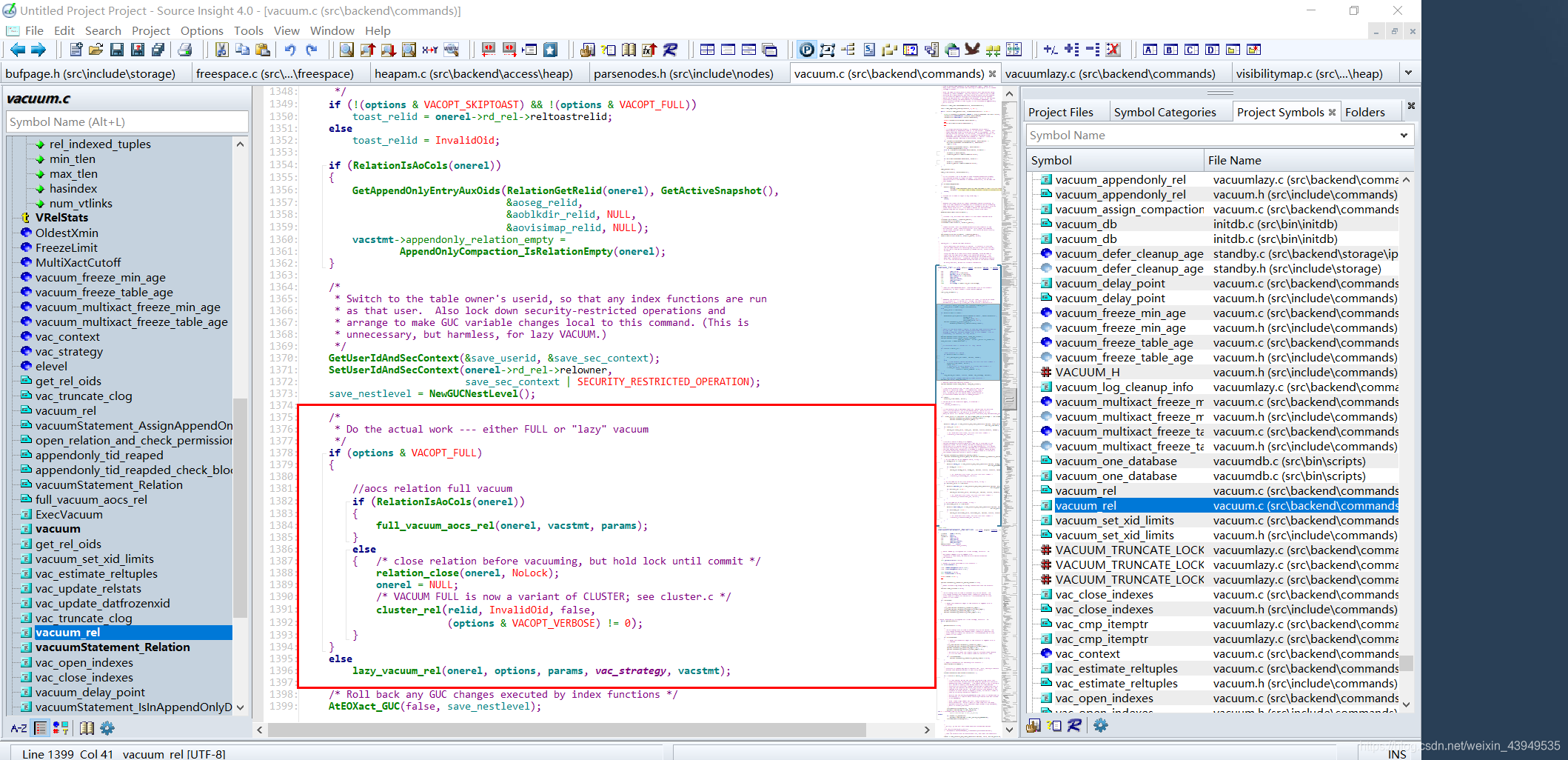
Lazy VACUUM
由上图所示:该方式是通过lazy_vacuum_rel函数实现,下面我们来看一下函数的主要流程:
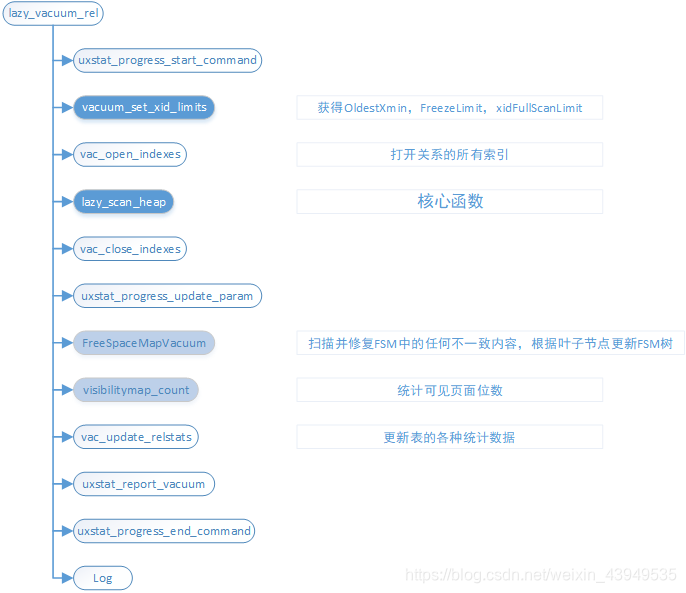
该函数在执行过程中将对单个表进行清理,并清理其索引、更新页面数和元组数的统计值。
注:上面还有一步 调用lazy_truncate_heap函数尝试截断文件末尾任何空页面
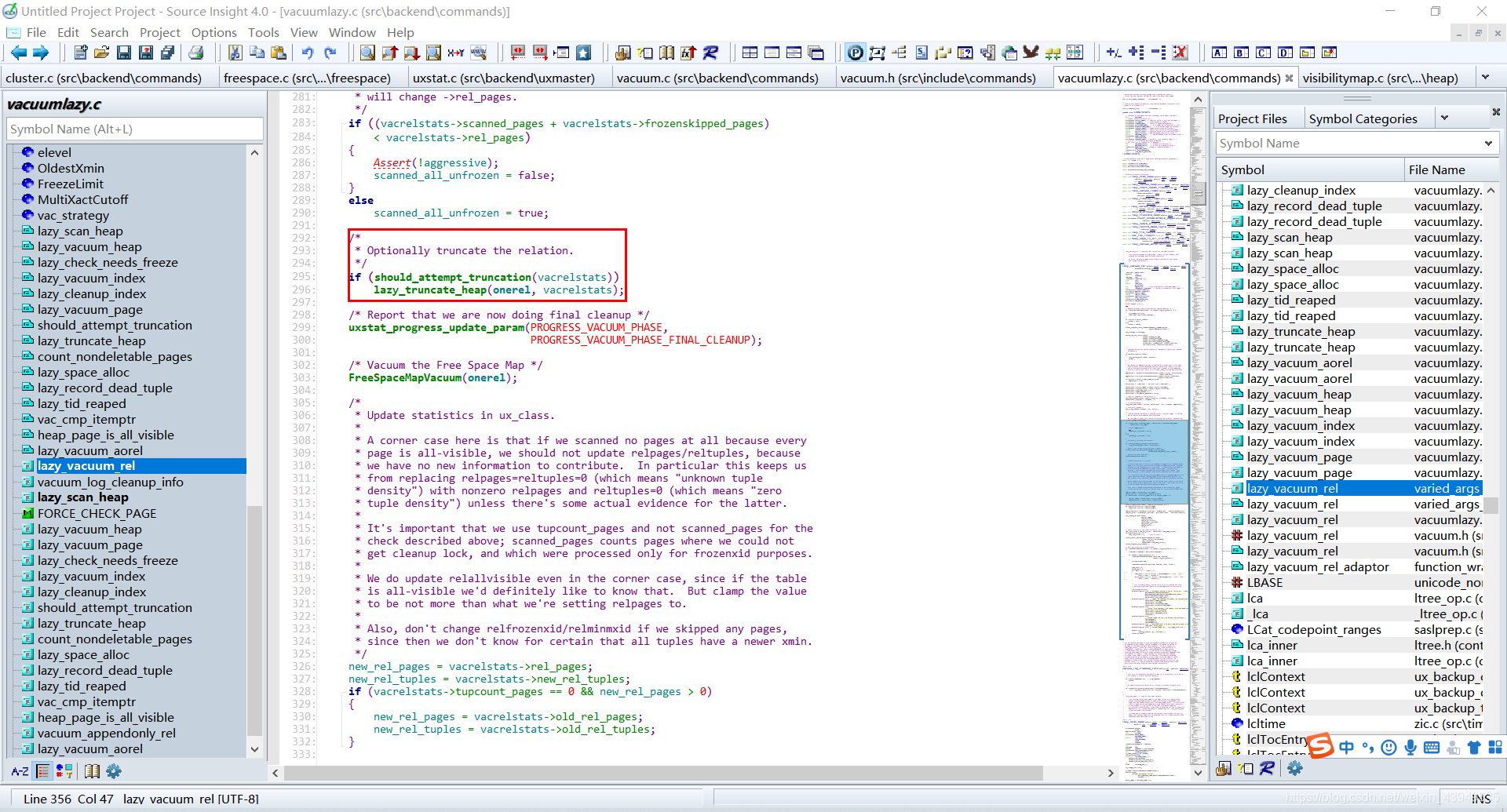
下面重点介绍lazy_scan_heap函数:
lazy_scan_heap函数是执行 VACUUM 的核心函数,该函数将首先扫描表,找到无效的元组和具有空闲空间的页面,然后计算表的有效元组数目,最后执行表和索引的清理操作。
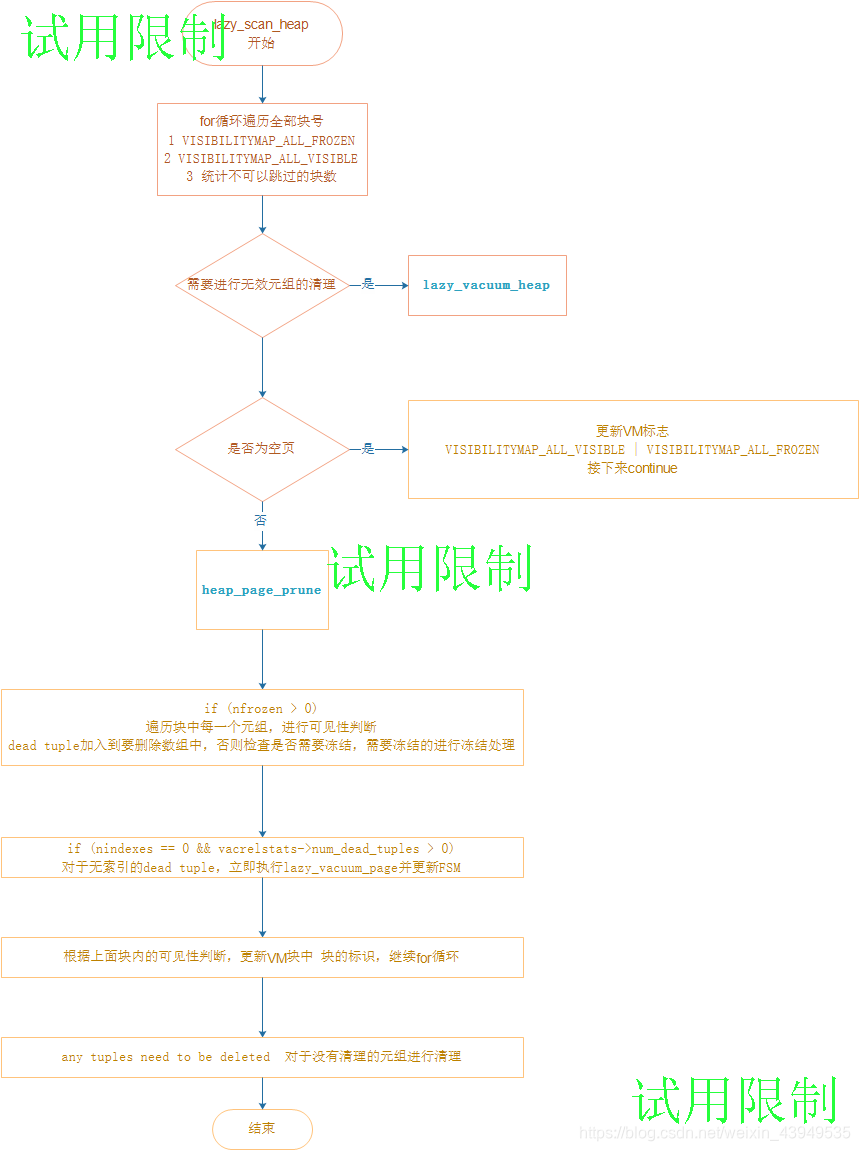
如上比较重要的几个函数说明:
- lazy_vacuum_heap: 该函数将对无效元组链上的元组按文件块为单位进行逐块清理。
- 上面的这个清理函数: lazy_vacuum_page :负责在文件块内,检查每个元组指针,如果该指针被标记为LP_DEAD则将其标记改为 LP UNUSED ,然后对文件块内的碎片进行整理,将空闲元组空间移动到文件块的空闲区域。
- heap_page_prune 函数:该函数用于清理单个文件块的 Hot链,并进行块内碎片的整理。
VACUUM的工作原理:首先,它扫描表中所有可能包含过期数据的页面。一种被称为visibility map的数据结构记录了自上一个VACUUM以来哪些页面已被修改,没有记录在里面的页面会被跳过。就这样,它会从这些页面中删除过期版本,并使这些元组占用的空间可供重用。在此过程中,过期版本被替换为一种类似墓碑的记号 - 在技术上,指向过期数据行的指针会被标记为LP_DEAD。另外,它会扫描表中的每个索引,并删除指向第一阶段中标识的LP_DEAD指针的所有索引条目。一旦完成此阶段,它将返回到表并删除过期标志 - 从技术角度来说,LP_DEAD行指针标记为LP_UNUSED。完成后,这些行指针可以重用于新元组。如果在删除索引条目之前重用这些行指针,我们可能最终会得到与它们指向的行版本不匹配的索引条目,这可能导致查询返回错误。
Full VACUUM
相较于上面的Lazy VACUUM,Full VACUUM除了对文件块进行整理之外,还实现了更为复杂跨块移动元组的操作。下面看一下full_vacuum_rel函数的主要流程:
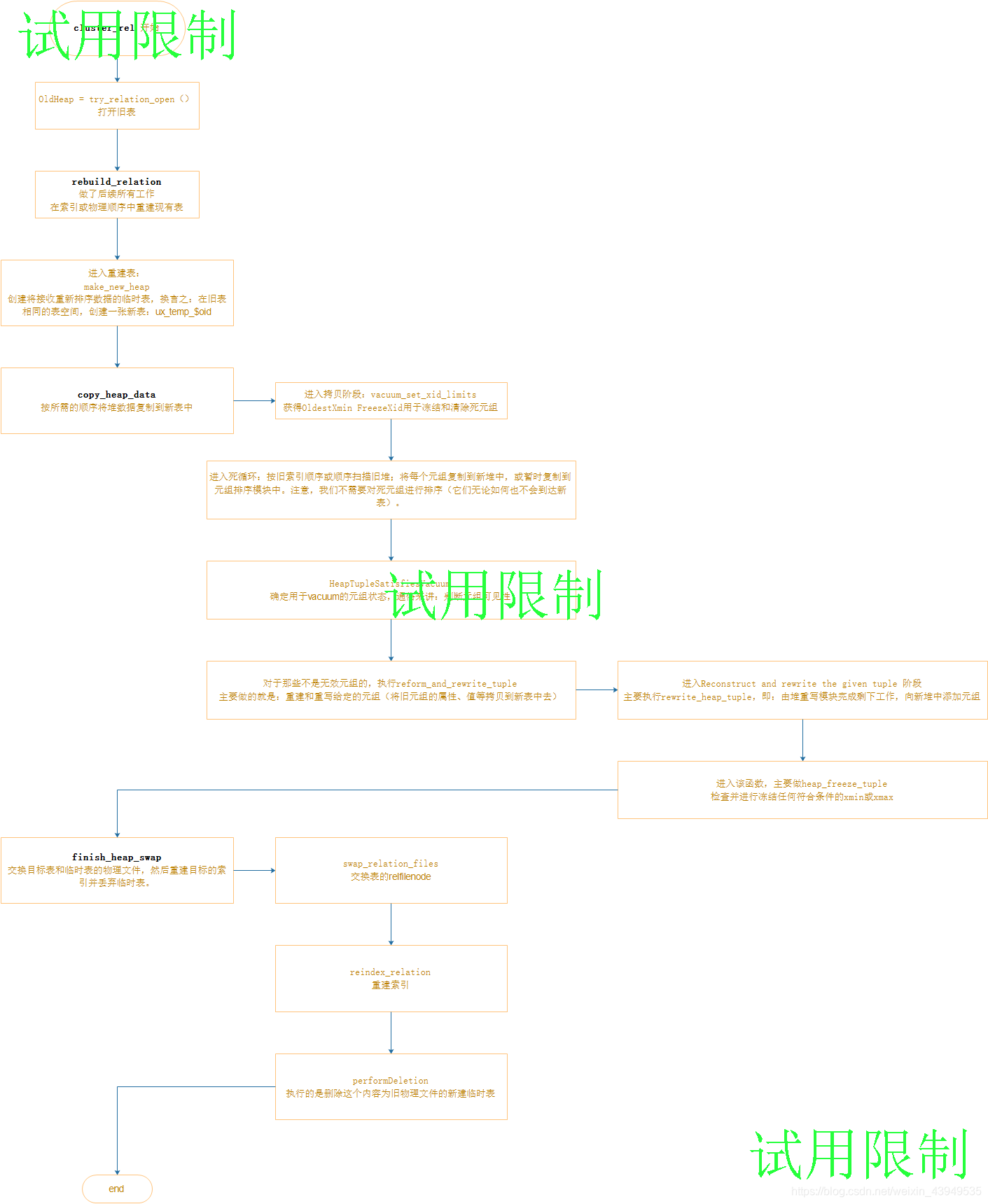
简而言之:上面执行流程大致如下
- 创建一张临时表:PG会新表一个以”pg_temp_%u”的临时表,临时表继承老表所有属性。”%u”是老表的OID。如果用户表有名字与这个临时表相同的,那么就会失败。另外临时表的OID是relfilenode。 这个阶段,会对pg_class申请“RowExclusiveLock”锁,因为需要插入条目;也会做表名检查,检查是否与现有表名冲突。
- 把旧表中的有效数据(不包括dead 元组)给拷贝到新表中去(过程中会进行相关的冻结操作):对临时表,老表以及索引都以“AccessExclusiveLock”模式打开。另外对于toast,只是lock,不打开。在这个过程中完成Dead Tuple的清理。
- 最后进行表文件交换,删除新建的临时表(在swap_relation_files会更新表的relfrozenxid)。
差异对比
上面我们已经介绍了两种方式的异同点,下面对其特性以及差异进行总结:
| 操作类型 | 无VACUUM | Lazy VACUUM | FULL VACUUM |
|---|---|---|---|
| 执行效率 | 由于只是状态置为操作,因此效率较高。 | 该命令会为指定的表或索引重新生成一个数据文件,并将原有文件中可用的数据导入到新文件中,之后再删除原来的数据文件。因此在导入过程中,要求当前磁盘有更多的空间可用于此操作。由此可见,该命令的执行效率相对较低。 | |
| 删除大量数据之后 | 只是将删除数据的状态置为已删除,该空间不能记录被重新使用。 | 如果删除的记录位于表的末端,其所占用的空间将会被物理释放并归还操作系统。如果不是末端数据,该命令会将指定表或索引中被删除数据所占用空间重新置为可用状态,那么在今后有新数据插入时,将优先使用该空间,直到所有被重用的空间用完时,再考虑使用新增的磁盘页面。 | 不论被删除的数据是否处于数据表的末端,这些数据所占用的空间都将被物理的释放并归还于操作系统。之后再有新数据插入时,将分配新的磁盘页面以供使用。 |
| 被删除的数据所占用的物理空间是否被重新规划给操作系统。 | 不会 | 不会 | 会 |
| 在执行VACUUM命令时,是否可以并发执行针对该表的其他操作 | 由于该操作是共享锁,因此可以与其他操作并行进行 | 由于该操作需要在指定的表上应用排它锁,因此在执行该操作期间,任何基于该表的操作都将被挂起,直到该操作完成 | |
| 推荐使用方式 | 在进行数据清空时,可以使用truncate操作,因为该操作将会物理的清空数据表,并将其所占用的空间直接归还于操作系统 | 为了保证数据表的磁盘页面数量能够保持在一个相对稳定值,可以定期执行该操作,如每天或每周中数据操作相对较少的时段 | 考虑到该操作的开销,以及对其他错误的排斥,推荐的方式是,定期监控数据量变化较大的表,只有确认其磁盘页面占有量接近临界值时,才考虑执行一次该操作。即便如此,也需要注意尽量选择数据操作较少的时段来完成该操作 |
| 执行后其它操作的效率 | 对于查询而言,由于存在大量的磁盘页面碎片,因此效率会逐步降低 | 相比于不执行任何VACUUM操作,其效率更高,但是插入的效率会有所降低 | 在执行完该操作后,所有基于该表的操作效率都会得到极大的提升 |