查询处理概述
查询处理器是DBMS中的一个部件集合,它允许用户使用SQL语言在较高的层次上表达查询,其主要职责:将用户的各种命令转化成数据库上的操作序列并执行。查询处理分查询编译和查询执行两个阶段。
- 查询编译的主要任务:根据用户的查询语句生成数据库中最优执行计划,在此过程中要考虑视图、规则以及表的连接路径等问题。
- 查询执行的主要任务:主要考虑执行计划时所采用的算法等问题。
下面对整个过程做如下详述:(当PostgreSQL的后台服务进程Postgres接收到查询语句后:)
- 首先将其传递到查询分析模块, 进行词法、语法和语义分析。
- 若是简单的命令(例如建表、创建用户、备份等)则将其分配到功能性命令处理模块。
- 对于复杂的命令(查询/插入/删除/更新)则要为其构建查询树(Query结构体) ,然后交给查询重写模块。
- 查询重写模块接收到查询树后,按照该查询所涉及的规则和视图对查询树进行重写,生成新的查询树。
- 生成路径模块依据重写过的查询树,考虑关系的访问方式、连接方式和连接顺序等问题,采用动态规划算法或遗传算法,生成最优的表连接路径。
- 最后,由最优路径生成可执行的计划,并将其传递到查询执行模块去执行。
下面是整个查询处理过程的各个模块的说明:
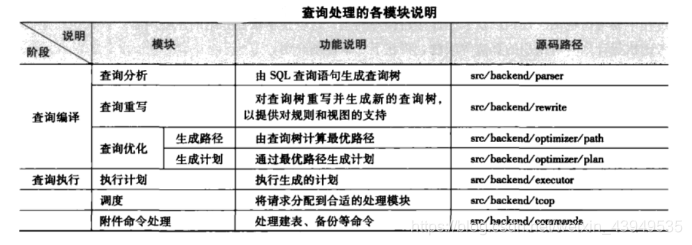
如上图所示:查询优化的核心是生成路径和生成计划两个模块。由于在整个查询执行过程中,表连接操作的开销最大,因此,查询优化要处理的问题焦点在于如何计算最优的表连接路径。
整个流程如下图所示:
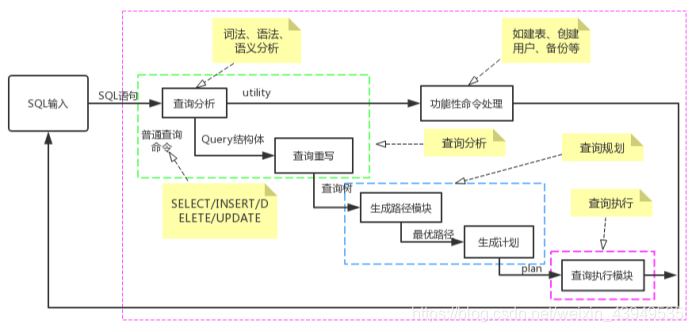
如上图,用户在较高层次上用SQL语法编写语句,由查询处理器将用户命令转化成数据库的操作系列,继而执行相应操作。
查询分析
查询分析是查询编译的第一个模块,包括词法分析,语法分析和语义分析三个部分。其中词法和语法分析分别借助于词法分析工具Lex和语法分析工具Yacc。
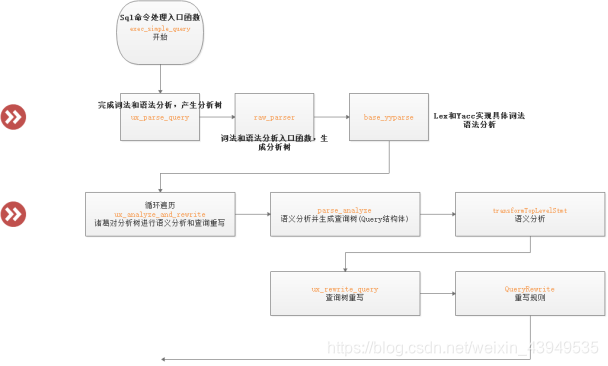
我们用户输入的SQL作为一个常量字符串传递给查询分析器,对其进行词法和语法分析生成分析树,然后进行语义分析得到查询树:其流程如下

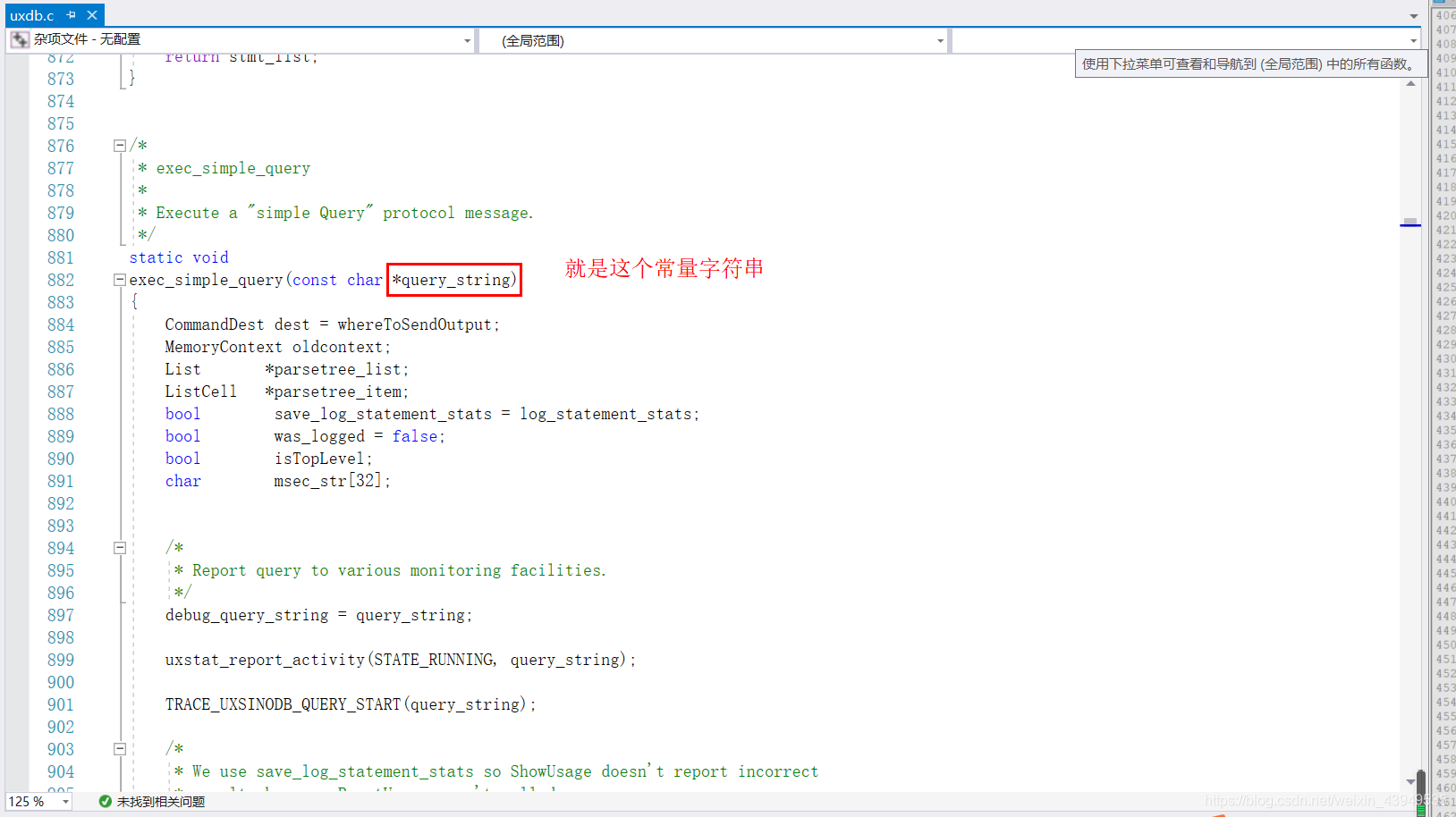
上面exec_simple_query就是SQL命令的统一处理入口函数,其主要调用和处理流程如下:
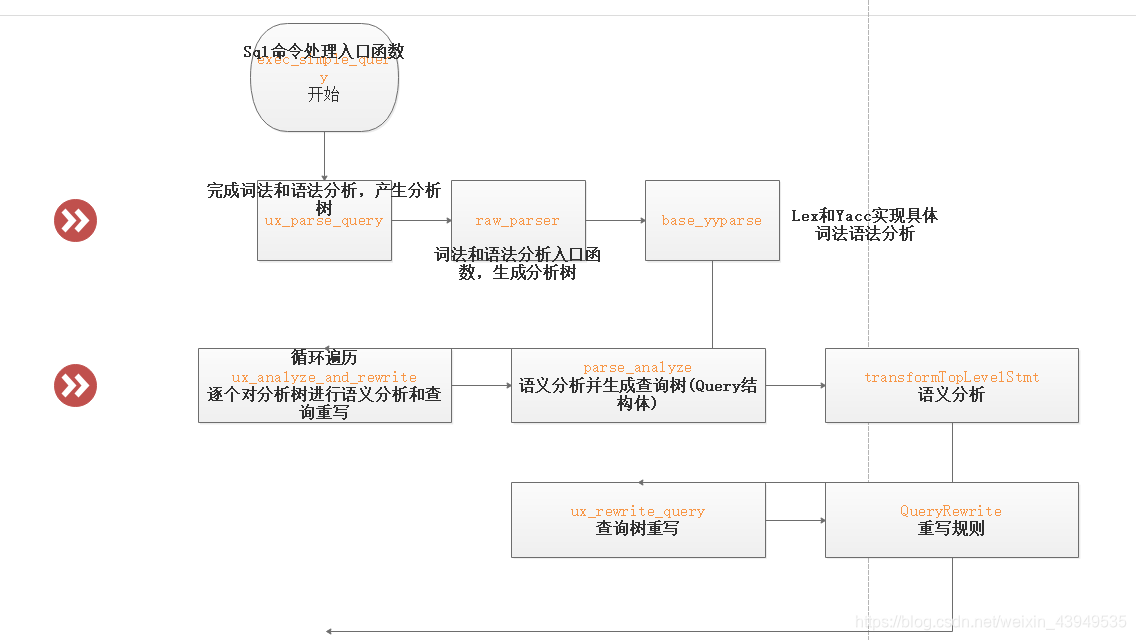
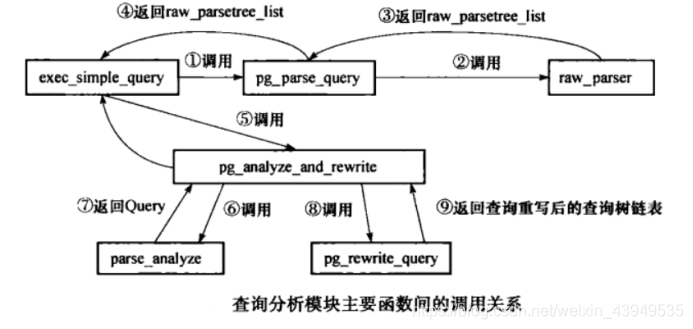
如上图所示,整个查询分析模块的处理过程如下:
- exec_simple_query调用函数 pg_parse_query进入词法和语法分析的主体处理过程。然后函数pg_parse_query调用词法和语法分析的入口函数 raw_parser生成分析树(原始分析树链表 raw_parse_tree_list 抽象的语法树:parse模块完成了 从一条select语句到内置的抽象的语法树)
- 函数pg_parse_query返回分析树给外部函数
- 然后exec_simple_query继续调用函数pg_analyze_and_rewrite进行语义分析和查询重写。其中首先调用函数 parse_analyze 进行语义分析并生成查询树(Query结构体) ,之后会将查询树传递给函数pg_rewrite_query进行查询重写
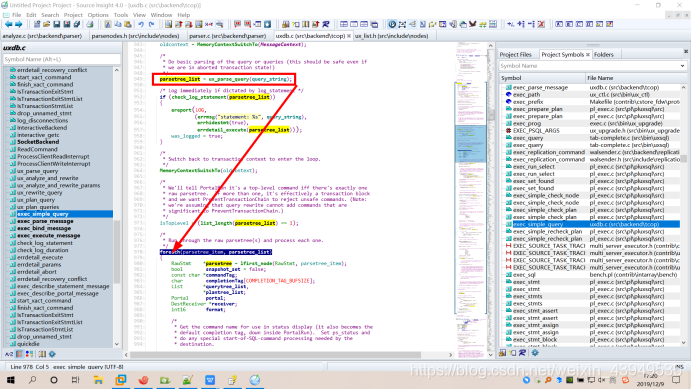
注:exec_simple_query在\src\backend\tcop\uxdb.c里面调用,然后调用函数 pg_parse_query 仅做原始解析:
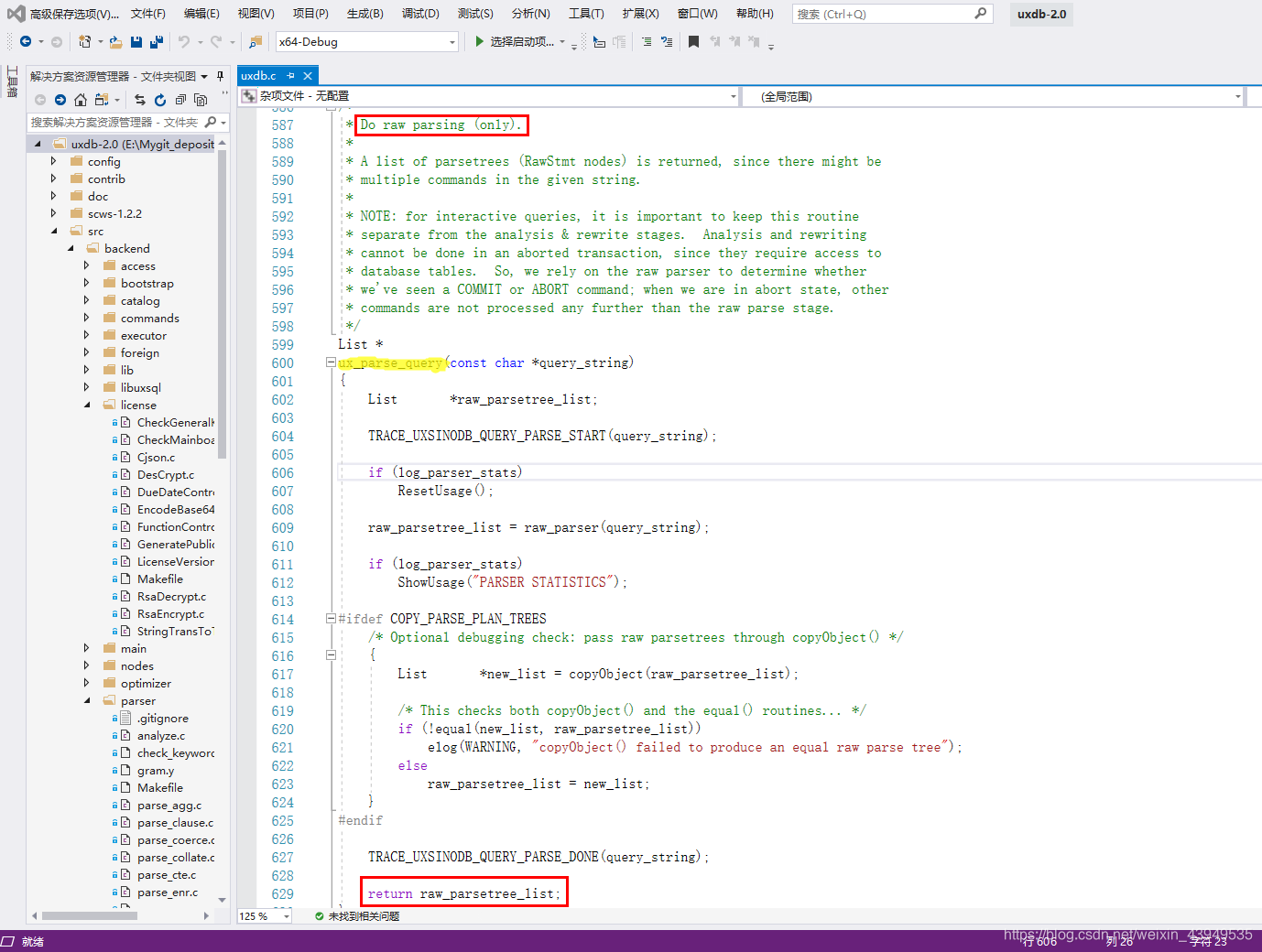
最后返回的是raw_parsetree_list分析树。注:pg_parse_query函数的入参是C语言字符串:里面可能有多个;相隔的查询语句。多个查询语句经过词法分析和语法分析之后,形成了一个List,其中每个节点代表一个Query查询树。
typedef struct ListCell ListCell;
typedef struct List
{
NodeTag type; /* T_List, T_IntList, or T_OidList */
int length;
ListCell *head;
ListCell *tail;
} List;
struct ListCell
{
union
{
void *ptr_value;
int int_value;
Oid oid_value;
} data;
ListCell *next;
};
其中类型如上,data字段指向具体的目标数据结构(注:大家先记一下这里的list的第一个变量NodeTag type;)
下面就看一下最终的查询树(Query结构,未进行重写的)
/*****************************************************************************
* Query Tree
*****************************************************************************/
/*
* Query -
* Parse analysis turns all statements into a Query tree
* for further processing by the rewriter and planner.
*
* Utility statements (i.e. non-optimizable statements) have the
* utilityStmt field set, and the rest of the Query is mostly dummy.
*
* Planning converts a Query tree into a Plan tree headed by a PlannedStmt
* node --- the Query structure is not used by the executor.
*/
typedef struct Query
{
NodeTag type;
CmdType commandType; /* select|insert|update|delete|utility */
QuerySource querySource; /* where did I come from? */
uint32 queryId; /* query identifier (can be set by plugins) */
bool canSetTag; /* do I set the command result tag? */
Node *utilityStmt; /* non-null if commandType == CMD_UTILITY */
int resultRelation; /* rtable index of target relation for
* INSERT/UPDATE/DELETE; 0 for SELECT */
bool hasAggs; /* has aggregates in tlist or havingQual */
bool hasWindowFuncs; /* has window functions in tlist */
bool hasTargetSRFs; /* has set-returning functions in tlist */
bool hasSubLinks; /* has subquery SubLink */
bool hasDistinctOn; /* distinctClause is from DISTINCT ON */
bool hasRecursive; /* WITH RECURSIVE was specified */
bool hasModifyingCTE; /* has INSERT/UPDATE/DELETE in WITH */
bool hasForUpdate; /* FOR [KEY] UPDATE/SHARE was specified */
bool hasRowSecurity; /* rewriter has applied some RLS policy */
List *cteList; /* WITH list (of CommonTableExpr's) */
List *rtable; /* list of range table entries */
FromExpr *jointree; /* table join tree (FROM and WHERE clauses) */
List *targetList; /* target list (of TargetEntry) */
OverridingKind override; /* OVERRIDING clause */
OnConflictExpr *onConflict; /* ON CONFLICT DO [NOTHING | UPDATE] */
List *returningList; /* return-values list (of TargetEntry) */
List *groupClause; /* a list of SortGroupClause's */
List *groupingSets; /* a list of GroupingSet's if present */
Node *havingQual; /* qualifications applied to groups */
List *windowClause; /* a list of WindowClause's */
List *distinctClause; /* a list of SortGroupClause's */
List *sortClause; /* a list of SortGroupClause's */
Node *limitOffset; /* # of result tuples to skip (int8 expr) */
Node *limitCount; /* # of result tuples to return (int8 expr) */
List *rowMarks; /* a list of RowMarkClause's */
Node *setOperations; /* set-operation tree if this is top level of
* a UNION/INTERSECT/EXCEPT query */
List *constraintDeps; /* a list of ux_constraint OIDs that the query
* depends on to be semantically valid */
List *withCheckOptions; /* a list of WithCheckOption's, which are
* only added during rewrite and therefore
* are not written out as part of Query. */
/*
* The following two fields identify the portion of the source text string
* containing this query. They are typically only populated in top-level
* Queries, not in sub-queries. When not set, they might both be zero, or
* both be -1 meaning "unknown".
*/
int stmt_location; /* start location, or -1 if unknown */
int stmt_len; /* length in bytes; 0 means "rest of string" */
} Query;
我们上面也说了,在得到词法和语法分析模块返还的raw_parsetree_list分析树之后,(循环遍历)对其中每个分析树调用pg_analyze_and_rewrite进行语义分析和查询重写。首先通过调用parse_analyze()生成对应的查询树,即Query结构(上面就是其结构类型定义),然后我们再调用pg_rewrite_query()对这个查询树进行重写,最终生成一个可能包含多棵查询树的链表。
下面先行看一下:(词法和语法分析模块)主要看一下raw_parser函数在(\src\backend\parser\parser.c)
/*
* raw_parser
* Given a query in string form, do lexical and grammatical analysis.
* 做词法分析和语法分析的
* Returns a list of raw (un-analyzed) parse trees. The immediate elements
* of the list are always RawStmt nodes.
*/
List *
raw_parser(const char *str)
{
core_yyscan_t yyscanner;
base_yy_extra_type yyextra;
int yyresult;
/* initialize the flex scanner 词法分析器的初始化*/
yyscanner = scanner_init(str, &yyextra.core_yy_extra,
ScanKeywords, NumScanKeywords);
/* base_yylex() only needs this much initialization */
yyextra.have_lookahead = false;
/* initialize the bison parser 语法分析器的初始化*/
parser_init(&yyextra);
/* Parse! 进行词法分析和语法分析 */
yyresult = base_yyparse(yyscanner);
/* Clean up (release memory) */
scanner_finish(yyscanner);//一些清理工作
if (yyresult) /* error */
return NIL;
return yyextra.parsetree;//返回词法分析和语法分析的结果
}
在其中,raw_parser是通过Lex和Yacc生成的代码来进行词法和语法分析并生成分析树。Lex和 Yacc是词法与语法分析工具,两者相配合可以生成用于词法和语法分析的C语言源代码。在raw_parser中,就是通过调用采用它俩预生成的函数base_yyparse来实现词法和语法分析工作。
- Lex用来生成扫描器,其工作是识别一个一个的模式,比如数字、字符串、特殊符号等,然后将其传给Yacc。
- Yacc则用于生成语法分析器,它识别模式的组合,即语法。它们通过共同的符号表传递标识符,通过内置变量 yylval传递表示的值。
Lex和Yacc简介
词法分析工具 Lex
Lex 是通用的用于生成扫描器的工具,它利用正则表达式来表达模式。词法分析的主要工作是利用正则表达式在给定字符序列中进行模式匹配,这些正则表达式通常写在一个后缀为.l 的文件(Lex文件)中,通过Lex 命令可以从Lex文件生成一个包含有扫描器的C语言源代码,其他源代码可以通过调用该扫描器来实现词法分析。
下面看一个简单的实例来说明Lex的文件基本语法: (Lex文件不仅仅只有 正则表达式)


Lex文件分为3段,分别是定义段、规则段和代码段,各段之间由"%%"符号分隔。
- 定义段可以包含任意的C语言头文件、符号说明等,其代码会被直接拷贝到生成的扫描器代码文件中。
- 规则段利用正则表达式来匹配模式,每当成功匹配1个模式,就对应其后{}中的代码,这些匹配规则及动作都会反映到最后生成的扫扫描代码文件中。
- 代码段可以是任意的C代码,但是其中必须要调用Lex提供的函数 。上例中使用yylex 就是其中之一,它完成实际的分析工作。在代码段中,只需要调用 yylex 即可,其实现代码将由Lex工具根据规则段的内容来生成。代码段中的内容将会被直接拷贝到生成的扫描器代码文件中。
于是上面这个简单的实例的例子,就会如下:也就是说 生成了一个可以用来识别一个整数并将其输出的C文件。
生成这个扫描器代码的命令:lex example.l
编译这个扫描器代码的命令:cc lex.yy.c -o out -ll
解释上面这两句话:
- Lex 命令从文件example.l 生成 lex.yy.c 文件
- cc命令中的参数-ll用于链接Lex 库
- 编译生成的程序名为out,运行out后输入任意字符串将会输出结果,例如输入 “123”后会输出结果 “num=123”。

语法分析工具 Yacc
语法分析的主要工作是从给定模式序列输入中寻找某一个特定语法结构。例如,有一个简单的英文句子的语法定义"Sentence ——>subject verb object , Object ——>noun , Subject——>noun或pronoun" 。这个定义表明句子 sentence是由主语( subject) 动词 (verb)和宾语 (object的序列构成,而宾语由1个名词组成,主语由名词或者代词( pronoun) 组成。因此 She goes home就是符合该语法的句子,而 She home则不符合该语法,因为后面这个句子缺乏动词,不能匹配该语法的模式。Yacc 也以类似的方式来定义语法,Yacc 的工作方式和Lex相似,也是将语法的定义以及一些必要的C语言代码写在一个后缀为.y的文件Yacc文件中,然后使用 Yacc 命令由该文件生成具有语法分析功能的C语言代码文件。


上面以1个简单的只识别加减法的计算嚣的Yacc 文件为例,对Yacc 文件的格式进行介绍。可以看到,Yacc 文件同样分为3个段:定义段、规则段和代码段,其中各个段由"%%"符号分隔。
- 定义段可以是C代码,如包含头文件和函数声明("% {…%} 中的内容),同时也可以定义Yacc 的内部标志等。在这个计算器的例子中,%token 定义标识符,%left指定运算法的优先级,%start 表示从标识符开始解析
- 规则段用来表示语法规则, 并在每识别一个语法规则后,根据规则后面{}内的代码进行相应的处理操作。其中$ $ 代表语法表达式的 左边结构 的值,而 $ 1 代表语法表达式 右边结构第一个标识符对应的值,依此类推。例子中的第12行的语法表达式就说明expression可以由一个 expression 、" +"号和一个NUMBER 构成,如果有1个模式能够匹配这个语法规则,则左边 expression的值( $ $ )等于右边expression 的值 ($ 1)加上 NUMBER 的值( $3) ,中间跳过没有用到的 $2 指的是 +号
- 代码段包括C代码,它将被直接拷贝到生成的C文件中。同样代码段中也包含一些Yacc函数 和 一些Lex传递给 Yacc 的变量
我们从上面结构可以看出,main 函数不断地执行yyparse函数来进行语法分析。 yyparse 函数识别某种语法结构并进行相应的行为处理。可以看到,该语法结构是每当识别一个加法表达式时,就把加法两边的数相加;每当识别减法表达式时,就把减号两边的数相减。这样就完成了加减功能。 NAME NUMBER 这些符号只是定义,它们的值由Lex通过变量传送给 Yacc 。注意,我们虽然没有在例子中看到对Lex变量的直接使用,但是 Yacc 在生成代码时会使用这些变量 。因此, Yacc 是无法单独运行的,要与Lex配合使用。计算器例子对应的Lex文件如下:

如上图所示:我们可以看到Lex 每识别一个数字,将以标识符 NUMBER 返回给 Yacc (Lex 文件第7 行) ,并将它的值传给 yylval。Yacc 根据 NUMBER 标识可以判断 yylval 中存放的是1个数字,并从 yylval取其值。例如,前面提到的 $1 等就是从 yylval 中取值的。
于是,我们就可以利用上面的这两个文件来新建一个计算器程序,其命令如下:
yacc - d calculator. y 是生成y.tab.c和y.tab.h
lex calculator. l 是生成lex.yy.c
cc -o calculator y. tab.c lex. yy.c -ly -ll 是编译和链接C文件
最后就生成了可执行程序calculator,运行之后可以输入一个完整的加减法公式,他会识别后并计算结果返回。如:输入“1+2”,程序会返回结果:“=3”
注:不同版本下的Yacc程序其命令可能不同。例如:GNU的Yacc工具是bison 同样,不同OS下的编译链接C文件命令也不一定是cc。
在PostgreSQL中,其词法解析和语法解析就是借助于Lex和Yacc实现的,PostgreSQL的源代码中包含 scan.l 和gram.y两个文件,并且已经为这两个文件预生成了 C文件,分别是scan.c和gram.c。如果对 scan.l 和gram.y两个文件进行了修改,那么在编译 PostgreSQL的时候就会重新生成两个源文件。这两个C文件再配合上词法和语法分析模块需要的C文件就构成了整个模块。词法和语法分析模块的源代码位于目录 src/backend/parser 下,其中主要源文件的说明见下表所示,文件之间的关系如图所示。
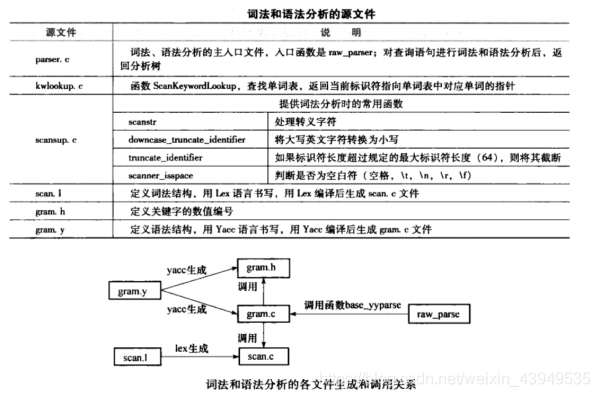
scan.l文件的主要目的就是:识别出PostgreSQL中使用的所有的关键字。
注:上图的kwlookup.c文件在我学习的PostgreSQL 10.0内核上面已经没有了,代之以src\common\keywords.c文件。但是上面的函数ScanKeywordLookup 依旧:
/*
* ScanKeywordLookup - see if a given word is a keyword
*
* The table to be searched is passed explicitly, so that this can be used
* to search keyword lists other than the standard list appearing above.
*
* Returns a pointer to the ScanKeyword table entry, or NULL if no match.
*
* The match is done case-insensitively. Note that we deliberately use a
* dumbed-down case conversion that will only translate 'A'-'Z' into 'a'-'z',
* even if we are in a locale where tolower() would produce more or different
* translations. This is to conform to the SQL99 spec, which says that
* keywords are to be matched in this way even though non-keyword identifiers
* receive a different case-normalization mapping.
*/
const ScanKeyword *
ScanKeywordLookup(const char *text,
const ScanKeyword *keywords,
int num_keywords)
{
int len,
i;
char word[NAMEDATALEN];
const ScanKeyword *low;
const ScanKeyword *high;
len = strlen(text);
/* We assume all keywords are shorter than NAMEDATALEN. */
if (len >= NAMEDATALEN)
return NULL;
/*
* Apply an ASCII-only downcasing. We must not use tolower() since it may
* produce the wrong translation in some locales (eg, Turkish).
*/
for (i = 0; i < len; i++)
{
char ch = text[i];
if (ch >= 'A' && ch <= 'Z')
ch += 'a' - 'A';
word[i] = ch;
}
word[len] = '\0';
/*
* Now do a binary search using plain strcmp() comparison.
*/
low = keywords;
high = keywords + (num_keywords - 1);
while (low <= high)
{
const ScanKeyword *middle;
int difference;
middle = low + (high - low) / 2;
difference = strcmp(middle->name, word);
if (difference == 0)
return middle;
else if (difference < 0)
low = middle + 1;
else
high = middle - 1;
}
return NULL;
}
上面也说了词法和语法分析的入口函数是raw_parser,它最后返回的raw_parsetree_list结构用于存储生成的分析树。(之后,我会把具体select语句为例分析查询语句是如何被解析并生成分析树 更新到我的博客上)
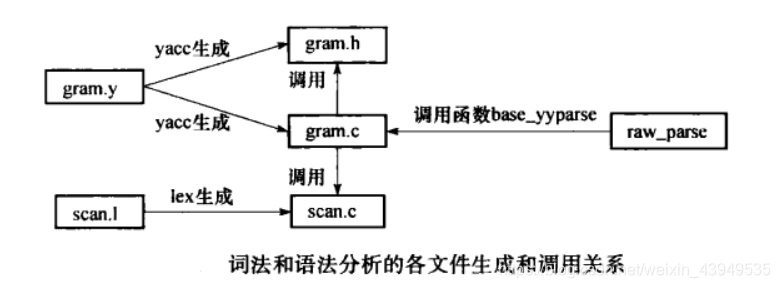
接下来看一下base_yyparse函数:
我们先看一下语法分析模块scan.l文件:该文件分为三部分。其中%top{}里面的是定义部分,它会原封不动的拷贝到源文件当中。这部分从上而下:包括了头文件、函数定义、变量,以及option 一些词法分析的选项内容等 和 %x的一些内部状态(例如:xb表示的是 当前的词法分析已经进入到了比特字符串里面;xc表示进入了一个C风格的注释里面等等) 正则表达式的定义和含义等 如空格space 水平的空格horiz_space 新行newline 注释comment 大块的空白部分whitespace等;这些正则表达式用来匹配我们的输入。(%%隔开)然后紧接着是规则部分:
%%
{whitespace} {
/* ignore */ 选择忽略空白的动作
}
{xcstart} { 遇到一个注释,采取的动作如下:
/* Set location in case of syntax error in comment */
SET_YYLLOC();//标记起始的地方
yyextra->xcdepth = 0;
BEGIN(xc);//表示 接下来进入注释的状态
/* Put back any characters past slash-star; see above */
yyless(2);//把斜线星后面的任何字符放回去;见上行
}
//上面的这个xcstart 是xcstart \/\*{op_chars}* 意指C语言风格注释的开始
<xc>{xcstart} {
(yyextra->xcdepth)++;//又遇到一个xcstart,当前深度就进入下一层
/* Put back any characters past slash-star; see above */
yyless(2);
}
<xc>{xcstop} {//注释的结束 //如果当前的深度<=0,则表明是当前最外层的注释结束
if (yyextra->xcdepth <= 0)
BEGIN(INITIAL);
else
(yyextra->xcdepth)--;//处在多个嵌套注释中的一个
}
<xc>{xcinside} {
/* ignore */ //在注释内部,忽略
}
···
{typecast} {//即做类型转换的
SET_YYLLOC();
return TYPECAST;//返回关键字 代表的值
}
//typecast的解释如下:
/* Assorted special-case operators and operator-like tokens */
typecast "::"
上面的return 的TYPECAST,在gram.h里面 值为266.即 keyword
···
这部分是由 一个规则,{}包含的是它的动作。scan.l就是匹配输入的每个规则,然后执行相应的动作。如上部分。
然后我们先看一下有哪些keyword:(在src\include\parser\kwlist.h)在词法解析到一个关键字的时候,它若是一个关键字 则返回在gram.h里面代表的关键字的值。
(%%隔开)然后紧接着是代码段:这部分内容(词法分析的辅助内容)也会原封不动的拷贝到生成的源文件当中。
下面进入语法解析模块(通过gram.y进行的),该文件同样分为3部分:(上面已经讲过了,不再赘述)
第一部分的%union,如下:
%union //很多的数据类型 定义
{
core_YYSTYPE core_yystype;//这些数据类型 将是我们接下来要用到的
/* these fields must match core_YYSTYPE: */
int ival;
char *str;
const char *keyword;
char chr;
bool boolean;
JoinType jtype;
DropBehavior dbehavior;
OnCommitAction oncommit;
List *list;
Node *node;
Value *value;
ObjectType objtype;
TypeName *typnam;
FunctionParameter *fun_param;
FunctionParameterMode fun_param_mode;
ObjectWithArgs *objwithargs;
DefElem *defelt;
SortBy *sortby;
WindowDef *windef;
JoinExpr *jexpr;
IndexElem *ielem;
Alias *alias;
RangeVar *range;
IntoClause *into;
WithClause *with;
InferClause *infer;
OnConflictClause *onconflict;
A_Indices *aind;
ResTarget *target;
struct PrivTarget *privtarget;
AccessPriv *accesspriv;
struct ImportQual *importqual;
InsertStmt *istmt;
VariableSetStmt *vsetstmt;
PartitionElem *partelem;
PartitionSpec *partspec;
PartitionBoundSpec *partboundspec;
RoleSpec *rolespec;
}
下面的%type < node > 定义的这么多数据类型,其实际数据类型是《》里面的类型决定的 也就是node(上面union里面的node)。
紧接着的是%token < str > ,token就是所定义的 由词法分析所返回的值
%token < keyword > 是关键字所代表的的值,keyword类型实际上是 const char* 。这些不能用于用户自定义的表名或列名等。因为遇到关键字,这里返回的是关键字代表的值 而非其字符串。
接下来是:是控制语法分析所需要的优先级
/* Precedence: lowest to highest 从低到高*/
%nonassoc SET /* see relation_expr_opt_alias */
%left UNION EXCEPT
%left INTERSECT
%left OR
%left AND
%right NOT
%nonassoc IS ISNULL NOTNULL /* IS sets precedence for IS NULL, etc */
%nonassoc '<' '>' '=' LESS_EQUALS GREATER_EQUALS NOT_EQUALS
%nonassoc BETWEEN IN_P LIKE ILIKE SIMILAR NOT_LA
%nonassoc ESCAPE /* ESCAPE must be just above LIKE/ILIKE/SIMILAR */
%left POSTFIXOP /* dummy for postfix Op rules */
还有操作符的结合:左结合还是右结合。左结合:先算左边 后算右边。如+ -。
%nonassoc UNBOUNDED /* ideally should have same precedence as IDENT */
%nonassoc IDENT GENERATED NULL_P PARTITION RANGE ROWS PRECEDING FOLLOWING CUBE ROLLUP
%left Op OPERATOR /* multi-character ops and user-defined operators */
%left '+' '-'
%left '*' '/' '%'
%left '^'
/* Unary Operators */
%left AT /* sets precedence for AT TIME ZONE */
%left COLLATE
%right UMINUS
%left '[' ']'
%left '(' ')'
%left TYPECAST
%left '.'
/*
* These might seem to be low-precedence, but actually they are not part
* of the arithmetic hierarchy at all in their use as JOIN operators.
* We make them high-precedence to support their use as function names.
* They wouldn't be given a precedence at all, were it not that we need
* left-associativity among the JOIN rules themselves.
*/
%left JOIN CROSS LEFT FULL RIGHT INNER_P NATURAL
/* kluge to keep xml_whitespace_option from causing shift/reduce conflicts */
%right PRESERVE STRIP_P
接下来是第二部分(规则部分):匹配到一条规则,以及匹配到规则之后的动作。如下:
%%
/*
* The target production for the whole parse.
*/
stmtblock: stmtmulti //这里是语法解析的最顶层
{
ux_yyget_extra(yyscanner)->parsetree = $1;//到这里就都语法分析完了
}
;
/*
*这个规则向上查找该文件,其类型是list类型。stmtblock实质上 其定义是stmtmulti
*(其类型是list类型),然后意思就是当解析stmtblock时 就把$1 就是stmtmulti
*赋给这里的parsetree
*--------------------
*大家跟我回忆一下:位于src\backend\parser\parser.c的raw_parser的return
/*
* raw_parser
* Given a query in string form, do lexical and grammatical analysis.
*
* Returns a list of raw (un-analyzed) parse trees. The immediate elements
* of the list are always RawStmt nodes.
*/
List *
raw_parser(const char *str)
{
core_yyscan_t yyscanner;
base_yy_extra_type yyextra;
int yyresult;
/* initialize the flex scanner */
yyscanner = scanner_init(str, &yyextra.core_yy_extra,
ScanKeywords, NumScanKeywords);
/* base_yylex() only needs this much initialization */
yyextra.have_lookahead = false;
/* initialize the bison parser */
parser_init(&yyextra);
/* Parse! */
yyresult = base_yyparse(yyscanner);
/* Clean up (release memory) */
scanner_finish(yyscanner);
if (yyresult) /* error */
return NIL;
return yyextra.parsetree;
}
*/
然后接下来看一下stmtmulti:它可以分为有;分隔的stmtmulti和stmt。
/*
* At top level, we wrap each stmt with a RawStmt node carrying start location
* and length of the stmt's text. Notice that the start loc/len are driven
* entirely from semicolon locations (@2). It would seem natural to use
* @1 or @3 to get the true start location of a stmt, but that doesn't work
* for statements that can start with empty nonterminals (opt_with_clause is
* the main offender here); as noted in the comments for YYLLOC_DEFAULT,
* we'd get -1 for the location in such cases.
* We also take care to discard empty statements entirely.
*/
stmtmulti: stmtmulti ';' stmt
{
if ($1 != NIL)
{
/* update length of previous stmt */
updateRawStmtEnd(llast_node(RawStmt, $1), @2);
}
if ($3 != NULL)//多条情况下,把链表附加到最左边
$$ = lappend($1, makeRawStmt($3, @2 + 1));
else
$$ = $1;
}
| stmt//单条情况下 把单条的语句创建一个链表,并把链表附加到最左边
{
if ($1 != NULL)
$$ = list_make1(makeRawStmt($1, 0));
else
$$ = NIL;
}
;
上面两个规则就说明了:语法分析 递归的 定义的情况,最终的所有定义的规则就都会匹配到最顶层的stmtblock规则。下面来看一下stmt规则:这个语句可以由下面的多种语句来代表。我就着重讲一下SelectStmt:(一条查询语句的类型:%type < node >),好 我们先看一下Node类型:(类型位于src\include\nodes\nodes.h)
/*
* The first field of a node of any type is guaranteed to be the NodeTag.
* Hence the type of any node can be gotten by casting it to Node. Declaring
* a variable to be of Node * (instead of void *) can also facilitate
* debugging.
*/
typedef struct Node
{
NodeTag type;
} Node;
其中NodeTag是代表这个Node类型的标签,通过这个标签可以判断Node具体是什么类型 然后通过一个强制转化 转换成相应的类型。
以SELECT为例 分析pg查询语句如何被解析和生成分析树
SelectStmt: select_no_parens %prec UMINUS 没有括号的
| select_with_parens %prec UMINUS 有括号的
;
select_with_parens:
'(' select_no_parens ')' { $$ = $2; }
| '(' select_with_parens ')' { $$ = $2; }
;
SELECT 语句(用标识符SelectStmt 表示)定义为带括号的 SELECT 语句(用标识符 select_with
parens 表示)和 不带括 SELECT 语句(用标识符select_no_parens表示)。带括号的 SELECT 语句最终会定义为括号和不带括号的 SELECT 语句的序列来处理,因此最终要处理的是不带括号的形式,如下没有括号的分为以下几种情况:
select_no_parens://不带括号的SELECT的语法定义
simple_select { $$ = $1; }//简单select
| select_clause sort_clause//和select + 排序的子句
{
insertSelectOptions((SelectStmt *) $1, $2, NIL,
NULL, NULL, NULL,
yyscanner);
$$ = $1;
}
| select_clause opt_sort_clause for_locking_clause opt_select_limit
{
insertSelectOptions((SelectStmt *) $1, $2, $3,
list_nth($4, 0), list_nth($4, 1),
NULL,
yyscanner);
$$ = $1;
}
| select_clause opt_sort_clause select_limit opt_for_locking_clause
{
insertSelectOptions((SelectStmt *) $1, $2, $4,
list_nth($3, 0), list_nth($3, 1),
NULL,
yyscanner);
$$ = $1;
}
| with_clause select_clause
{
insertSelectOptions((SelectStmt *) $2, NULL, NIL,
NULL, NULL,
$1,
yyscanner);
$$ = $2;
}
| with_clause select_clause sort_clause
{
insertSelectOptions((SelectStmt *) $2, $3, NIL,
NULL, NULL,
$1,
yyscanner);
$$ = $2;
}
| with_clause select_clause opt_sort_clause for_locking_clause opt_select_limit
{
insertSelectOptions((SelectStmt *) $2, $3, $4,
list_nth($5, 0), list_nth($5, 1),
$1,
yyscanner);
$$ = $2;
}
| with_clause select_clause opt_sort_clause select_limit opt_for_locking_clause
{
insertSelectOptions((SelectStmt *) $2, $3, $5,
list_nth($4, 0), list_nth($4, 1),
$1,
yyscanner);
$$ = $2;
}
;
select_clause:
simple_select { $$ = $1; }
| select_with_parens { $$ = $1; }
;
从以上代码可以看出,一条不带括号的 SELECT 语句可以定义为一条简单的 SELECT 语句(是用
标识符 símple_select 表示) ,也可以定义为在简单 SELECT 语句后接排序子句 (标识符为sort_clause )、LIMIT子句 标识符 (select_limit) 等构成的复杂语句 。可以看到,对于整个语句的语法分析实际上是将语句拆分成很多小的语法单元,然后分别对这些小的单元进行分析。因此,只要弄消楚各个小语法单元的做法,就可以把它们组合在一起形成整个语法树。这里我们着重分析simple_select的语法定义。simple_select子句:(一个简单的select语句就是下面这样定义的)
/*
* This rule parses SELECT statements that can appear within set operations,
* including UNION, INTERSECT and EXCEPT. '(' and ')' can be used to specify
* the ordering of the set operations. Without '(' and ')' we want the
* operations to be ordered per the precedence specs at the head of this file.
*
* As with select_no_parens, simple_select cannot have outer parentheses,
* but can have parenthesized subclauses.
*
* Note that sort clauses cannot be included at this level --- SQL requires
* SELECT foo UNION SELECT bar ORDER BY baz
* to be parsed as
* (SELECT foo UNION SELECT bar) ORDER BY baz
* not
* SELECT foo UNION (SELECT bar ORDER BY baz)
* Likewise for WITH, FOR UPDATE and LIMIT. Therefore, those clauses are
* described as part of the select_no_parens production, not simple_select.
* This does not limit functionality, because you can reintroduce these
* clauses inside parentheses.
*
* NOTE: only the leftmost component SelectStmt should have INTO.
* However, this is not checked by the grammar; parse analysis must check it.
*/
/*
解释下面第一种情况:若是匹配到关键字SELECT,词法分析会返回这个关键字的值(在gram.y文件上半部分)
给语法分析器,语法分析器会来匹配这个规则。opt_all_clause实际all,opt_target_list主要选择的目
标列,into_clause是select into的情况,from_clause是where选择的哪些范围 表,
where_clause是select选择的where条件,group_clause分组情况,
having_clause是分组情况的条件,window_clause窗口部分
*/
simple_select:
SELECT opt_all_clause opt_target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
//创建一个SELECT节点
SelectStmt *n = makeNode(SelectStmt);//创建一个SelectStmt节点
n->targetList = $3;//下面是把节点的成员填充进去 目标属性
n->intoClause = $4;//select into子句
n->fromClause = $5;//from 子句
n->whereClause = $6;//where 子句
n->groupClause = $7;//group by子句
n->havingClause = $8;//HAVING 子句
n->windowClause = $9;//窗口子句
$$ = (Node *)n;//然后把SelectStmt节点 强转Node节点 并返回
}//然后simple_select再不断地向上返回,到select_clause
//再向上到select_no_parens 再向上到 SelectStmt ,它就是stmt,
//再向上到stmtmulti 再向上到stmtblock。
//最后统统都是结束到stmtblock,然后就结束了语法分析的工作。
| SELECT distinct_clause target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->distinctClause = $2;
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
}
| values_clause { $$ = $1; }
| TABLE relation_expr
{
/* same as SELECT * FROM relation_expr */
ColumnRef *cr = makeNode(ColumnRef);
ResTarget *rt = makeNode(ResTarget);
SelectStmt *n = makeNode(SelectStmt);
cr->fields = list_make1(makeNode(A_Star));
cr->location = -1;
rt->name = NULL;
rt->indirection = NIL;
rt->val = (Node *)cr;
rt->location = -1;
n->targetList = list_make1(rt);
n->fromClause = list_make1($2);
$$ = (Node *)n;
}
| select_clause UNION all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_UNION, $3, $1, $4);
}
| select_clause INTERSECT all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_INTERSECT, $3, $1, $4);
}
| select_clause EXCEPT all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_EXCEPT, $3, $1, $4);
}
;
simple_select是一 SELECT语句的最核心部分,从simple_select的语法定义可以看出,它由如
下子句组成:去除行重复的DISTINCT(标识符distinct_clause ) 、 目标属性(标识符opt_target_list)、 SECT INTO子句(标识符ínto_clause )、 FROM子句(标识符 from_clause )、WHERE 子句(标识符
where_ clause )、 GROUP BY子句{标识符 group _clause)、HAVING 子句(标识符having_clause )和窗口子句(标识符 window_clause) 。在成功匹配simple_select语法结构后,将创建一个SelectStmt结构体(数据结构如下:) 并将各子句赋值到结构体中相应的字段。
typedef struct SelectStmt
{
NodeTag type;//节点类型 用于标识节点的内容,在SelectStmt中会取值T_SelectStmt
/*
* These fields are used only in "leaf" SelectStmts.
*/
//DISTINCT子句
List *distinctClause; /* NULL, list of DISTINCT ON exprs, or
* lcons(NIL,NIL) for all (SELECT DISTINCT) */
//SELECT INTO或者CREATE TABLE AS子句
IntoClause *intoClause; /* target for SELECT INTO */
List *targetList; /* the target list (of ResTarget) 目标属性*/
List *fromClause; /* the FROM clause from子句*/
Node *whereClause; /* WHERE qualification where子句*/
List *groupClause; /* GROUP BY clauses */
Node *havingClause; /* HAVING conditional-expression */
List *windowClause; /* WINDOW window_name AS (...), ... */
/*
* In a "leaf" node representing a VALUES list, the above fields are all
* null, and instead this field is set. Note that the elements of the
* sublists are just expressions, without ResTarget decoration. Also note
* that a list element can be DEFAULT (represented as a SetToDefault
* node), regardless of the context of the VALUES list. It's up to parse
* analysis to reject that where not valid.
values列表,产生“常量表”,常量表可以作为虚拟表出现在FROM中*/
List *valuesLists; /* untransformed list of expression lists */
/*
* These fields are used in both "leaf" SelectStmts and upper-level
* SelectStmts.
*/
List *sortClause; /* sort clause (a list of SortBy's) 是ORDER BY子句*/
Node *limitOffset; /* # of result tuples to skip OFFSET子句*/
Node *limitCount; /* # of result tuples to return limit子句*/
List *lockingClause; /* FOR UPDATE (list of LockingClause's) 子句*/
WithClause *withClause; /* WITH clause with子句*/
/*
* These fields are used only in upper-level SelectStmts.
*/
//查询语句的集合操作,∩/∪/差
SetOperation op; /* type of set op */
//在集合操作时是否指定了ALL关键字
bool all; /* ALL specified? */
struct SelectStmt *larg; /* left child 左孩子节点*/
struct SelectStmt *rarg; /* right child */
/* Eventually add fields for CORRESPONDING spec here */
} SelectStmt;
我们上面也看到了:此外simple_select 还可以定义为其他的形式。如VALUES 子句、关系表达式以及多个 SELECT 语句的交并差等,但这些情况最终都会转化成最基本símple_selec 形式来处理。而对于simple_select 来说,目标属性(标识符 target_list) 、 FROM 子句(标识 from_clause )、WHERE子句(标识符 where_clause )以及 GROUP BY 子句 (标识 group_clause) 是最重要的部分。
然后我们重点关注一下opt_target_list:主要选择的目标列
/*****************************************************************************
*
* target list for SELECT
*
*****************************************************************************/
opt_target_list: target_list { $$ = $1; }
| /* EMPTY */ { $$ = NIL; }
;
target_list://有几个,分隔的target_el
target_el { $$ = list_make1($1); }
| target_list ',' target_el { $$ = lappend($1, $3); }
;
target_el: a_expr AS ColLabel 这是select as 给列取别名
{
$$ = makeNode(ResTarget);
$$->name = $3;
$$->indirection = NIL;
$$->val = (Node *)$1;
$$->location = @1;
}
/*
* We support omitting AS only for column labels that aren't
* any known keyword. There is an ambiguity against postfix
* operators: is "a ! b" an infix expression, or a postfix
* expression and a column label? We prefer to resolve this
* as an infix expression, which we accomplish by assigning
* IDENT a precedence higher than POSTFIXOP.
*/
| a_expr IDENT
{
$$ = makeNode(ResTarget);
$$->name = $2;
$$->indirection = NIL;
$$->val = (Node *)$1;
$$->location = @1;
}
| a_expr 直接就是select 表达式
{
$$ = makeNode(ResTarget);
$$->name = NULL;
$$->indirection = NIL;
$$->val = (Node *)$1;
$$->location = @1;
}
| '*' 直接就是select *,即所有的列
{
ColumnRef *n = makeNode(ColumnRef);
n->fields = list_make1(makeNode(A_Star));
n->location = @1;
$$ = makeNode(ResTarget);
$$->name = NULL;
$$->indirection = NIL;
$$->val = (Node *)n;
$$->location = @1;
}
;
下面是from_clause是where选择的哪些范围 表:
/*****************************************************************************
*
* clauses common to all Optimizable Stmts:
* from_clause - allow list of both JOIN expressions and table names
* where_clause - qualifications for joins or restrictions
*
*****************************************************************************/
//from子句 首先匹配的是FROM关键字,
from_clause:
FROM from_list { $$ = $2; }
| /*EMPTY*/ { $$ = NIL; }
;
from_list: //实际代表的内容
table_ref { $$ = list_make1($1); }
| from_list ',' table_ref { $$ = lappend($1, $3); }
;
//上面from_list 有多个以 ,隔开的table_ref组成的
其中对于table_ref(一个表),如下:
/*
* table_ref is where an alias clause can be attached.
*/
table_ref: relation_expr opt_alias_clause//只带了一个表和其别名
{
$1->alias = $2;
$$ = (Node *) $1;
}
| relation_expr opt_alias_clause tablesample_clause
{
RangeTableSample *n = (RangeTableSample *) $3;
$1->alias = $2;
/* relation_expr goes inside the RangeTableSample node */
n->relation = (Node *) $1;
$$ = (Node *) n;
}
| func_table func_alias_clause
{
RangeFunction *n = (RangeFunction *) $1;
n->alias = linitial($2);
n->coldeflist = lsecond($2);
$$ = (Node *) n;
}
| LATERAL_P func_table func_alias_clause
{
RangeFunction *n = (RangeFunction *) $2;
n->lateral = true;
n->alias = linitial($3);
n->coldeflist = lsecond($3);
$$ = (Node *) n;
}
| xmltable opt_alias_clause
{
RangeTableFunc *n = (RangeTableFunc *) $1;
n->alias = $2;
$$ = (Node *) n;
}
| LATERAL_P xmltable opt_alias_clause
{
RangeTableFunc *n = (RangeTableFunc *) $2;
n->lateral = true;
n->alias = $3;
$$ = (Node *) n;
}
| select_with_parens opt_alias_clause//指 from了一个子查询
{
RangeSubselect *n = makeNode(RangeSubselect);
n->lateral = false;//RangeSubselect代表这个子查询
n->subquery = $1;
n->alias = $2;
/*
* The SQL spec does not permit a subselect
* (<derived_table>) without an alias clause,
* so we don't either. This avoids the problem
* of needing to invent a unique refname for it.
* That could be surmounted if there's sufficient
* popular demand, but for now let's just implement
* the spec and see if anyone complains.
* However, it does seem like a good idea to emit
* an error message that's better than "syntax error".
*/
if ($2 == NULL)
{
if (IsA($1, SelectStmt) &&
((SelectStmt *) $1)->valuesLists)
ereport(ERROR,
(errcode(ERRCODE_SYNTAX_ERROR),
errmsg("VALUES in FROM must have an alias"),
errhint("For example, FROM (VALUES ...) [AS] foo."),
parser_errposition(@1)));
else
ereport(ERROR,
(errcode(ERRCODE_SYNTAX_ERROR),
errmsg("subquery in FROM must have an alias"),
errhint("For example, FROM (SELECT ...) [AS] foo."),
parser_errposition(@1)));
}
$$ = (Node *) n;
}
| LATERAL_P select_with_parens opt_alias_clause
{
RangeSubselect *n = makeNode(RangeSubselect);
n->lateral = true;
n->subquery = $2;
n->alias = $3;
/* same comment as above */
if ($3 == NULL)
{
if (IsA($2, SelectStmt) &&
((SelectStmt *) $2)->valuesLists)
ereport(ERROR,
(errcode(ERRCODE_SYNTAX_ERROR),
errmsg("VALUES in FROM must have an alias"),
errhint("For example, FROM (VALUES ...) [AS] foo."),
parser_errposition(@2)));
else
ereport(ERROR,
(errcode(ERRCODE_SYNTAX_ERROR),
errmsg("subquery in FROM must have an alias"),
errhint("For example, FROM (SELECT ...) [AS] foo."),
parser_errposition(@2)));
}
$$ = (Node *) n;
}
| joined_table
{
$$ = (Node *) $1;
}
| '(' joined_table ')' alias_clause
{
$2->alias = $4;
$$ = (Node *) $2;
}
;
下面看一下UpdateStmt:
/*****************************************************************************
*
* QUERY:
* UpdateStmt (UPDATE)
*
*****************************************************************************/
UpdateStmt: opt_with_clause UPDATE relation_expr_opt_alias
SET set_clause_list
from_clause
where_or_current_clause
returning_clause
{
UpdateStmt *n = makeNode(UpdateStmt);
n->relation = $3;
n->targetList = $5;
n->fromClause = $6;
n->whereClause = $7;
n->returningList = $8;
n->withClause = $1;
$$ = (Node *)n;
}
;
set_clause_list:
set_clause { $$ = $1; }
| set_clause_list ',' set_clause { $$ = list_concat($1,$3); }
;
set_clause:
set_target '=' a_expr
{
$1->val = (Node *) $3;
$$ = list_make1($1);
}
| '(' set_target_list ')' '=' a_expr
{
int ncolumns = list_length($2);
int i = 1;
ListCell *col_cell;
/* Create a MultiAssignRef source for each target */
foreach(col_cell, $2)
{
ResTarget *res_col = (ResTarget *) lfirst(col_cell);
MultiAssignRef *r = makeNode(MultiAssignRef);
r->source = (Node *) $5;
r->colno = i;
r->ncolumns = ncolumns;
res_col->val = (Node *) r;
i++;
}
$$ = $2;
}
;
set_target:
ColId opt_indirection
{
$$ = makeNode(ResTarget);
$$->name = $1;
$$->indirection = check_indirection($2, yyscanner);
$$->val = NULL; /* upper production sets this */
$$->location = @1;
}
;
set_target_list:
set_target { $$ = list_make1($1); }
| set_target_list ',' set_target { $$ = lappend($1,$3); }
;
下面来看一下SQL语句的执行中,语法树和查询树图:
update tb1 set a=1 where a=10;
它的未重写的查询树如下:
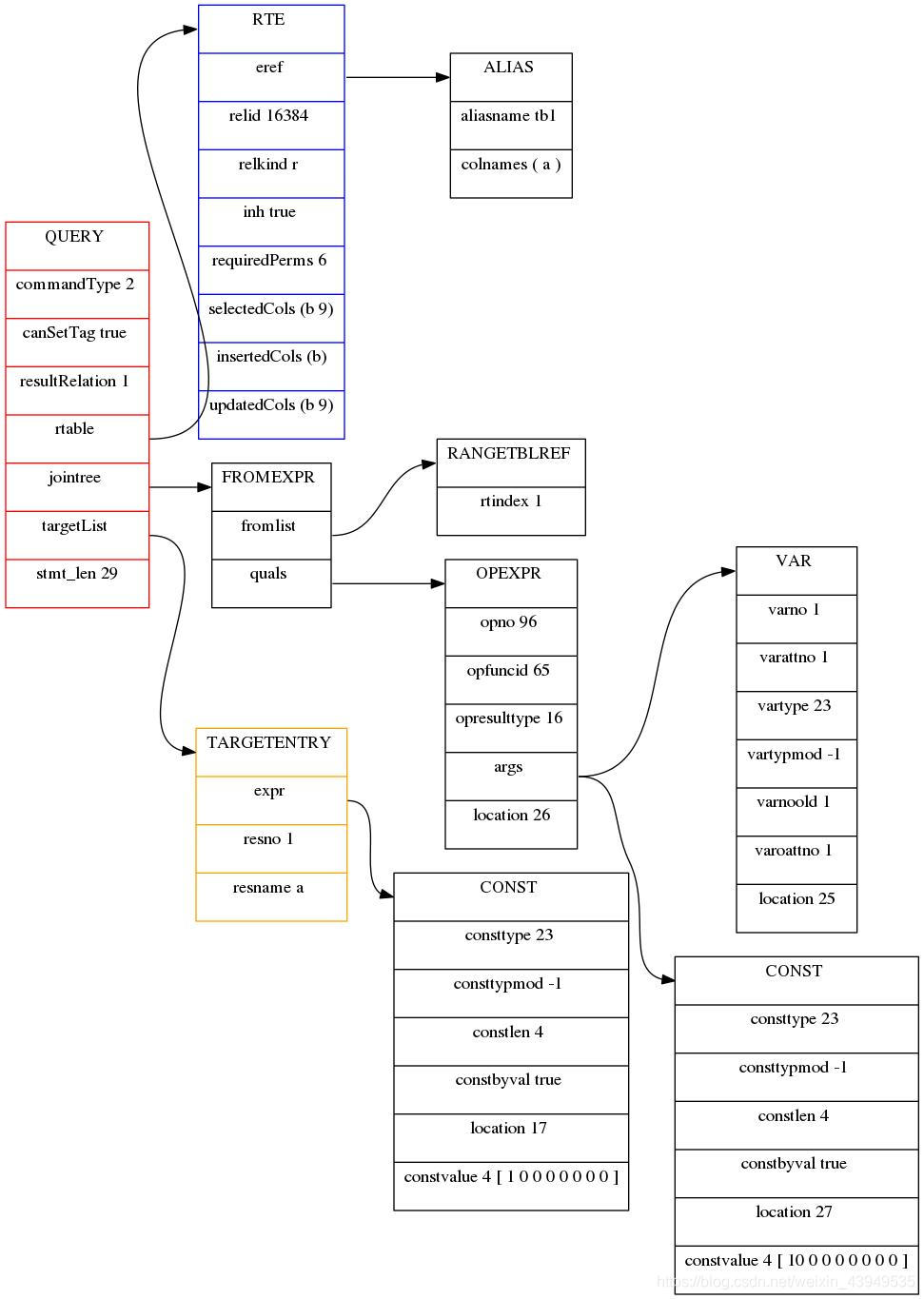
它的重写的查询树如下:
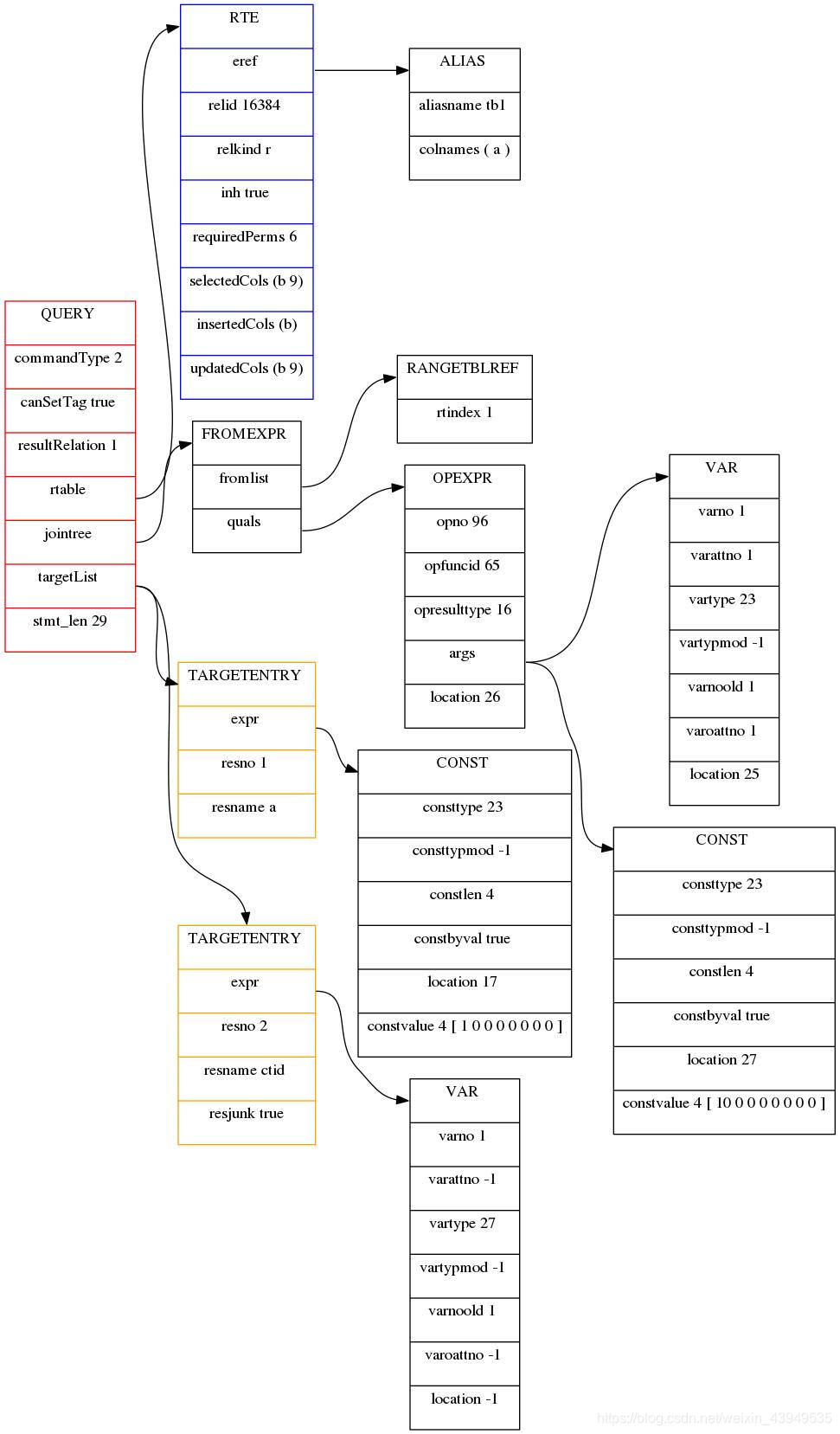
OK,下面就可以进入语义分析模块:exec_simple_query继续调用函数pg_analyze_and_rewrite进行语义分析和查询重写。其中首先调用函数 parse_analyze 进行语义分析并生成查询树(Query结构体) ,之后会将查询树传递给函数pg_rewrite_query进行查询重写。
语义分析阶段会检查命令中是否有不符合语义规定的成分。例如,所使用的表、属性、过程函数等是否存在,聚集函数(如求和函数SUM、平均函数AVG等)是否可以合法使用等。其主要作用:检查该命令是否可以正确执行。语义分析器会根据分析树上面的内容得到更有利于执行的数据。 例如:根据表的名字得到其OID,根据属性名得到其属性号,根据操作符的名字得到其对应的计算函数等。
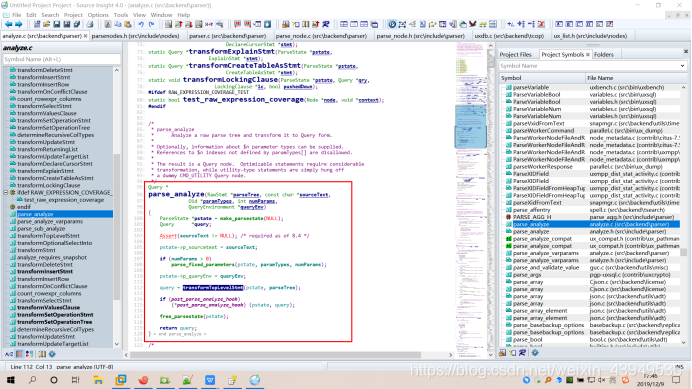
我上面也分析了在exec_simple_query在从词法和语法分析模块获取了parsetree_list之后,(进入exec_simple_query的第二大模块:语义分析和查询重写)会对其中的每一棵分析树调用ux_analyze_and_rewrite进行语义分析和查询重写(如下图foreach进行遍历操作)。而在其中负责语义分析的则是analyze. c文件中的 parse_analyze 函数。它会根据分析树生成一个对应的查询树,而查询重写模块则是继续对这个查询树进行修改,并且有可能会将这个查询树改写成一个包含多棵查询树的链表。因此,ux_analyze_and_rewrite最终返回给 exec_simple_query的将是一个查询树链表。
ux_analyze_and_rewrite作为第二模块的主要操作函数,它会依次调用里面的parse_analyze函数和ux_rewrite_query函数进行接下来的操作。
一棵分析树到达parse_analyze函数之后,会根据七种情况命令类型进行分摊处理。语义分析按命令类型分情况处理如下:
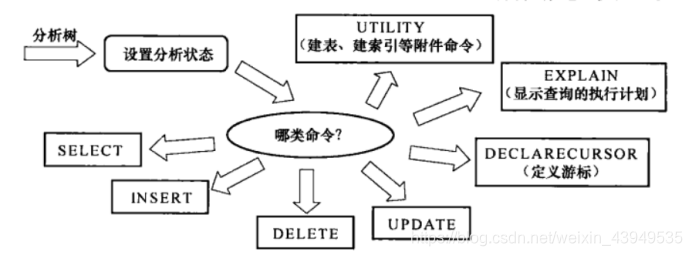
而在调用parse_analyze过程中有个ParseState结构(如下图所示)用于记录语义分析的状态(或者说:用于记录语义分析的中间信息),然后通过调用函数transformTopLevelStmt()完成分析过程。
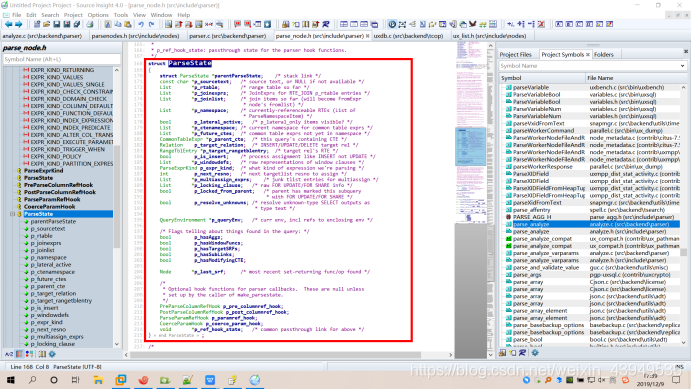
好的,接下来各位就跟在下一起看一下parse_analyze函数:首先将生成 ParseState结构用于记录语义分析的状态,然后通过调用函数transformTopLevelStmt下面的transformOptionalSelectInto下面的transformStmt函数完成语义分析过程。函数 transformStmt会根据不同的查询类型(就是上面强调的7种情况,如下绿色框框)调用相应的函数进处理。
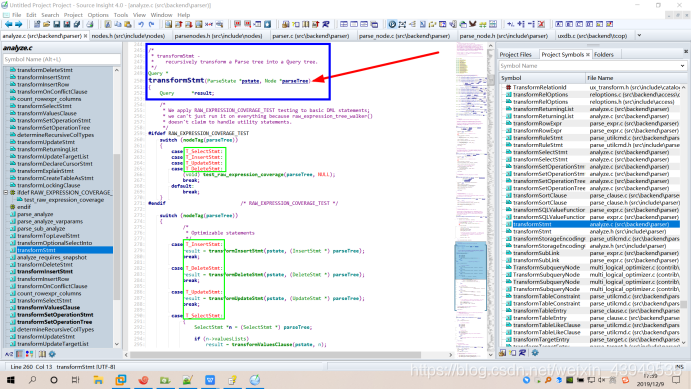
具体看一下transformStmt函数里面的内容:
我们在之前的词法和语法分析中介绍的数据结构List类型中可以看到,pg中几乎每一个数据结构的第一个字段都是 NodeTag 类型的 type。(这个大家是不是有些印象了,我在前面已经提示大家需要记一下的)。在Postgresql中为了传递参数方便,把很多数据节点的指针都通过指针类型转换成Node结构的指针, 而Node结构中只有一个类型为 NodeTag 名为type的字段,通过这样一种方式 pg就把大多数要传递的数据结构都包装成了称为 “Node” (节点)的统一形式,从而通过一套统一的操作函数进行处理。Node类型定义如下:
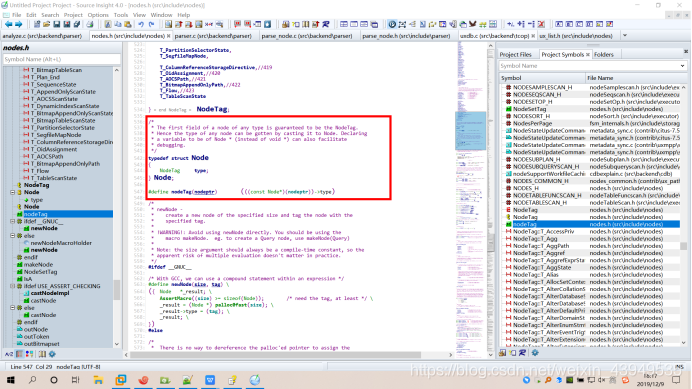
其中为了能够确定接收到的数据结构到底是哪一种,pg中把 NodeTag 设计成了 个枚举类型,每一种数据结构都在其中对一个值,这些值的名称都由“T_”及其数据类型名称组成,例如SelectStmt数据结构对应的NodeTag值就是 “T_SelectStmt”。(就是上面绿色框框里面的那七种)
这样的话,当我们得到一个Node时,只需要检查其type字段的值即可确定要处理的是哪种数据结构。
下面就需要再讲一下transformStmt函数:
transformStmt -
- recursively transform a Parse tree into a Query tree.
其原型:Query * transformStmt(ParseState *pstate, Node *parseTree);
两个参数:第一个是 ParseState ,另一个就是要处理的包装成节点的分析树。
于是我们就可以通过nodeTag(parseTree)即节点type字段,该函数就可以依次处理七种分析树了。(相应的处理函数如下:)

这些transform函数的主要作用:将分析树转换为查询树( Query结构)。查询树是SQL语句在pg中被处理时的内部表现形式,组成语句的每个独立部分(子句)存储在查询树的各个字段中。在 5.3 节中将要讲到的规则也是以查询树的文本形式存储在系统表中。查询树的Query结构,上面我已经贴过了。如下所示:
typedef struct Query
{
NodeTag type;
CmdType commandType; /* select|insert|update|delete|utility */
QuerySource querySource; /* where did I come from? */
uint32 queryId; /* query identifier (can be set by plugins) */
bool canSetTag; /* do I set the command result tag? */
Node *utilityStmt; /* non-null if commandType == CMD_UTILITY */
int resultRelation; /* rtable index of target relation for
* INSERT/UPDATE/DELETE; 0 for SELECT */
bool hasAggs; /* has aggregates in tlist or havingQual */
bool hasWindowFuncs; /* has window functions in tlist */
bool hasTargetSRFs; /* has set-returning functions in tlist */
bool hasSubLinks; /* has subquery SubLink */
bool hasDistinctOn; /* distinctClause is from DISTINCT ON */
bool hasRecursive; /* WITH RECURSIVE was specified */
bool hasModifyingCTE; /* has INSERT/UPDATE/DELETE in WITH */
bool hasForUpdate; /* FOR [KEY] UPDATE/SHARE was specified */
bool hasRowSecurity; /* rewriter has applied some RLS policy */
List *cteList; /* WITH list (of CommonTableExpr's) */
List *rtable; /* list of range table entries */
FromExpr *jointree; /* table join tree (FROM and WHERE clauses) */
List *targetList; /* target list (of TargetEntry) */
OverridingKind override; /* OVERRIDING clause */
OnConflictExpr *onConflict; /* ON CONFLICT DO [NOTHING | UPDATE] */
List *returningList; /* return-values list (of TargetEntry) */
List *groupClause; /* a list of SortGroupClause's */
List *groupingSets; /* a list of GroupingSet's if present */
Node *havingQual; /* qualifications applied to groups */
List *windowClause; /* a list of WindowClause's */
List *distinctClause; /* a list of SortGroupClause's */
List *sortClause; /* a list of SortGroupClause's */
Node *limitOffset; /* # of result tuples to skip (int8 expr) */
Node *limitCount; /* # of result tuples to return (int8 expr) */
List *rowMarks; /* a list of RowMarkClause's */
Node *setOperations; /* set-operation tree if this is top level of
* a UNION/INTERSECT/EXCEPT query */
List *constraintDeps; /* a list of ux_constraint OIDs that the query
* depends on to be semantically valid */
List *withCheckOptions; /* a list of WithCheckOption's, which are
* only added during rewrite and therefore
* are not written out as part of Query. */
/*
* The following two fields identify the portion of the source text string
* containing this query. They are typically only populated in top-level
* Queries, not in sub-queries. When not set, they might both be zero, or
* both be -1 meaning "unknown".
*/
int stmt_location; /* start location, or -1 if unknown */
int stmt_len; /* length in bytes; 0 means "rest of string" */
} Query;