注:首先声明一下 本人在过去的一年时间内,得到了很多的同学和老师 以及CSDN上面老哥的帮助,在今年毕业之后也成功进入一家公司:主要做PostgreSQL内核开发方面的。刚才CSDN通知:可以设置专栏 什么收费什么的,我在此声明:虽然我不是什么大牛,也不想挣大钱。喜欢本人的文章的小伙伴,我谢谢你们的支持。写的不好,你们可以骂我,当然我更希望我们可以一起进步。绝不收费!绝不收费!绝不收费!
为什么这么愤慨呢?我的一个学弟,技术非常good 是我佩服和羡慕的人,他有很多粉丝。然鹅,今天我去查看他的博客时,发现人家收费了。唉!我不想说什么,这是他的权利 可是我总感觉,心里很失落 很失望。因此,特此声明:努力提高技术,写好博客,一起分享,做好开源!
岁数大了(今年都22了),难免脾气大!!!好的,开始今天的学习
要求:增加create table后,默认增加一个隐藏列;再增加一个系统函数,可以给该隐藏列赋值。参考资料:pg中的技术内幕之系统字段、pg内核分析之表和元组组织方式 中文手册
预备知识
系统隐含字段
在postgresql中,每个表都会有几个系统字段,这些字段是由系统隐含定义的。这些系统字段在psql下使用\d命令的结果中并不会显示,但请记住实际表中还存在着这些隐含字段。因为表中已隐含了某些名字的字段,所以用户定义的字段名称不能再使用这些名字,这个限制与名字是否为关键字没有关系,即使字段名称用双引号括起来也不行。
这些系统字段主要有如下:
- oid:行对象标识符(对象 ID)。这个字段只有在创建表时使用了“with oids”或配置参数“default with oids”的值为真时才出现(系统不会给用户创建的表增加一个OID系统字段)。这个字段的类型是oid(类型名和字段名同名),在pg中就是使用OID作为各种系统表的主键,它是一个unsigned int,因此不太适合提供大数据范围内的唯一性保证和单个大表中使用也不行。(不建议在用户创建的表中使用OID字段,最好只用作系统表)。此外它生成的是全局的序列值(全局分配 不是由某张表单独分派)。除了作为一个对象标识符,OID还有几个表示具体对象类型的别名,它所代表的所有对象标识符类型如下:

- tableoid:包含本行的表的 oid。对父表(该表存在有继承关系的子表)进行查询时, 使用这个字段,就可以知道某一行来自父表还是子表,以及是哪个子表。 tableoid可以和 pg class的 oid 字段连接起来获取表名字。
- xmin:插入该行版本的事务ID。
- xmax:删除此行时的事务 ID,第一次插入时,此字段为0。如果查询出来此字段不为0,则可能是删除这行的事务还没有提交,或者是删除此行的事务回滚掉了。
- cmin:事务内部插入类操作的命令ID,此标识是从0 开始的。
- cmax:事务内部删除类操作的命令ID,如果不是删除命令,此字段为0。
- ctid:一个行版本在它所处的表内的物理位置(block号及块内偏移量)。其类型tid,尽管ctid可以快速的定位该数据行,但是在全盘清理之后:数据行在块内的物理位置就会移动(ctid会发生变化),也正是因为这样它是不可以作为长期的行标识符,故而应该让一个主键来标识一个逻辑行。它由两个数字组成:1物理块号,2在物理块中的行号。下面有图可以详解。若元组被更新(PostgreSQL对元组的更新采用的是标记删除旧版本元组并插入新版本元组的方式),则记录的是新版本元组的物理位置。PostgreSQL中对于元组采用多版本技术存储,对元组的每个更新操作都会产生一个新版本,版本之间从老到新形成一条版本链(将旧版本的t_ctid字段指向下一个版本的位置即可)。它就是可以唯一确定该元组处于页面 页面之中偏移的位置(物理存放的位置)。
其中四个字段在MVCC中用于控制数据行是否对用户可见,pg会将修改前后的数据都储存在相同的结构中,这分为以下几种情况:
- 新插入一行:该行的xmin=当前事务ID,xmax=0
- 修改某一行:实际上是新插入一行,旧行上的xmin不变 旧行上的xmax=当前事务ID;新行上的xmin=当前事务id,xmax=0
- 删除某一行:把被删除行上的xmax=当前事务id
从上面,就可以得到:xmin就是标记插入数据行的事务id,xmax就是标记删除数据行的事务id。这里没有修改数据行的操作,因为修改数据行实质上:把旧数据行上的xmax=自己事务id,相当于删除标志,然后再做了一个插入。
下面看一下cmin和cmax:用于判断同一个事务内的不同命令导致的行版本变化是否可见。若一个事务内所有的命令都是严格按序执行,则每个命令都可以看到之前该事务内的所有变更,这种情况下不需要使用命令标识。一般编程中,对一个数组和列表遍历时:不允许读时写。而在数据库中,对游标进行遍历时:可以对游标引用的表进行写而不至出现逻辑错误(这是因为游标是一个快照,遍历时写不会影响游标的数据。该遍历游标看到的是声明游标时的数据快照而非执行时的数据,因此在扫描数据时,会忽略声明游标后对数据的变更,因为这些变更对该游标是无效的)。游标后续看到的数据都是声明游标之前的一个快照,相当于游标与后续的命令并发交错执行(与事务间交错执行类似),存在数据可见性问题。
因此与解决事务内可见性问题类似,pg引入命令ID:行上记录了操作该行的命令id,当其他命令读取这行数据时,若当前命令id>=数据行上的命令id,则说明该行数据是可见的;否则不可见。
命令id的分配规则如下:

- 每个命令使用事务内一个全局命令标识计数器的当前值作为当前命令标识
- 事务开始时 命令标识计数器=0
- 执行更新性命令(删除、插入、更新、select…for update)时,在SQL执行之后 命令标识计数器+1
- 命令标识计数器一直加 之后回到0,报错:“cannot have more than 4G commands in a transaction”,即一个事务命令的个数最多4G
物理存储结构
基本结构
在pg中目前不支持使用裸设备和块设备,所以表里面的数据总是存放在一个或多个物理的数据文件中,而这些相应的数据文件又分为多个固定大小的数据库(数据就放在这些数据库中)。先看一下pg里面的一些术语:
- Relation:表示表或索引,也就是其他数据库的table或index(具体情况具体分析)
- Tuple:表中的行,也就是其他数据库的row
- Page:表示在磁盘中的数据块
- Buffer:表示在内存中的数据块
看一下数据块page的结构图:

一个数据块的大小默认8KB,最大32KB,一个数据块中可以存放多行数据。如上图所示:块中的结构是先有一个块头,其后记录了这个块中各个数据行的指针,行指针是向后按顺序排列的,而实际的数据行内容则是从块尾向前反向排列的。行数据指针与行数据间是空闲的。
块头的一些记录信息:
- 块的checksum值
- 空闲空间的起始位置和结束位置
- 特殊数据的起始位置
- 其他一些信息
行指针是一个32位的数字,具体结构如下:
- 行内容的偏移量 15位 能表示最大偏移量:32768。这也就决定了块的最大大小32KB
- 指针的标记 2位
- 行内容的长度 15位
在pg中,一个文件的大小最大默认1G,大于则在后面加上_1和_2等。存储表、索引等的文件都是由如上的页面组成的。
接下来看一下:tuple结构(数据行)如下:

Tuple物理结构的首先是一个行头,后面是各项数据。下面详解一下行头的重要信息:
- Natts&infomask2:字段数 其中低11位表示这行有多少个列,其他位则用于HOT技术以及行可见性的标识位。
- Infomask:用于标识行当前状态,比如行是否有OID、是否有空属性等,共16位:每位代表不同的状态。
- Hoff:行头的长度。用处:直接可以跳过头部,来定位到数据的位置
- Bits:是一个数组,用于标识该行上哪些字段(列)为空。之后就是元组的数据
之所以区分事务id和命令id:一个事务有多个command,所以用commandid来保证是谁 插入 删除的和保证可见性的。
前面也说了行上的xmin、xmax、cmin、cmax配合着clog日志一起就可以用于控制行的可见性。其中一个事务在clog中占2位,而数据库最多可达到20亿个事务,因此使用的clog就将占用到480MB空间。若此时在clog中查询事务的状态 效率非常低,于是就对查询 行的可见性做如下优化:把一些可见性的信息记录在infomask字段上(16位),该字段的t_infomask中包含如下与 可见性相关的标志位:
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
若是t_infomask中的HEAP_XMIN_COMMITTED为真,HEAP_XMAX_INVALID为假则说明 这行是新插入的行,是可见的。(此时不需要到clog中查询xmin和xmax的事务状态);若是没有设置HEAP_XMIN_COMMITTED,并不能说明 这行没有提交,而是说明不知道xmin是否提交了,需要到clog中去判断xmin的状态。HEAP_XMAX_COMMITTED亦是如此!
当第一次插入数据时,t_infomask中的HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID并没有设置。当事务提交后,再读取这个数据块的时候 会通过clog判断出这些行的事务已经提交,从而设置t_infomask中的HEAP_XMIN_COMMITTED为真,HEAP_XMAX_INVALID为真。于是当下次我们再查询该行时,直接使用t_infomask中的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID标志位就可以判断出行的可行性,从而不需要到clog中查询。
相关代码结构如下:

struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
}t_choice;
ItemPointerData t_ctid; /*block号及item号*/
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
};

这部分详见博客:http://blog.itpub.net/31493717/viewspace-2220463/
至于t_choice是具有两个成员的联合类型:
- t_heap:用于记录对元组执行插入/删除操作的事务ID和命令ID,这些信息主要用于并发控制时检查元组对事务的可见性。(前面也说过了)
- t_datum:当一个新元组在内存中形成的时候,我们并不关心其事务可见性,因此在t_choice中只需用DatumTupleFields结构来记录元组的长度等信息。但在把该元组插入到表文件时,需要在元组头信息中记录插入该元组的事务和命令ID,故此时会把t_choice所占用的内存转换HeapTupleFields结构并填充相应数据后再进行元组的插入。
FSM
随着在表的数据块中插入、删除和更新数据,会产生旧版本的数据,这些旧版本数据通过vacuum的清理,会在数据块中产生空闲空间。当再向表中插入数据的时候,最好的办法就是继续使用这些旧数据块中的空闲空间,若是给所有的新数据都分配新的数据块 会造成数据文件不断膨胀。
于是当插入新行的时候,若多个数据块中有空闲空间,应把数据行插到其中哪个数据块中呢?
因为有空闲空间的数据块不一定能容纳下新的数据行,故而要插入一行数据时,首先要做的就是快速找到一个空闲空间去足以放下该数据行的数据块。因此为了实现这一操作要求,需要实现以下两个功能:
- 要记录每个数据块空闲空间的大小
- 要实现快速查找,而非一个一个找
因此pg中使用了FSM 机制:使用一个名为FSM的文件记录每个数据块的空闲空间。Free space map,为了减少FSM的文件大小,这里只使用一个字节来记录一个数据块中的空闲空间。我们先算一下:一字节8位(256) 无法记录空闲空间的实际大小的,所以这里让这个字节值来代表空闲空间的一个范围,具体方法如下:

这256个值就可以映射为256个大小范围,注意:字节为单位。自8.4之后,pg为每个数据文件创建一个名为(表OID_fsm)文件,且为了快速查找到符合要求的数据块,这里采用树形结构组织FSM文件。

如上图所示:文件采用三层树形结构,第0 、1层为查找辅助层,第2层中 每个块的每个字节代表其对应的数据块中的空闲空间。第一层中的每个块中的字节值代表下一层(第二层)相应的数据块中的最大值,第0层中的每个字节表示第一层中数据块的最大值。若是第2层的每个数据块可以填4000左右个字节,则这4000字节对应着在真正的数据文件中4000个数据块各有多少空闲空间值;而第一层中的这个字节则表示第2层中对应数据块中的最大值(就是这4000个值的最大值:真正数据文件中4000个数据块最大的空闲空间);同时第0层只有1个块,于是当需要判断数据块的空闲空间是否有足够大时,就查看这个块即可确定有无合适空闲空间大小的数据块。
下面跟着我分析一下上面图的实例:第0层只有1块,该块中的第一个字节值为123,这就表示第一层的第一个数据块中字节的最大值为123;该块中的第二个字节值为192,这就表示第一层的第二个数据块中字节的最大值为192…以此类推,第一层到下一层的映射亦是如此。
注:FSM文件并非在创建表文件时就马上创建的,而是等到需要时才创建。这个需要时:执行vacuum操作或者为了插入行而第一次查询FSM文件时。
VM
在上面的那个执行vacuum操作时,原来单独的表文件 将额外增加FSM文件和VM文件。这里的VM文件就是可见性映射表文件。
前面也说过了,在pg里面更新、删除某行为标记删除:并不马上从数据块中清理掉,而是需要等到执行vacuum命令时再清理。于是这个VM文件目的:为了加快vacuum清理的速度和降低对系统I/O性能的影响。
原理:VM文件为每个数据块设置了一个标志位,用来标记数据块中是否存在需要清理的行。于是在vacuum扫描这个文件时,若发现VM文件中这个数据块上的位表示该数据块没有需要清理的行,就会跳过对该数据块的扫描(加快vacuum清理的速度)
注:vacuum这部分内容详见我的博客,这里只是为了做题 就不再向下赘述了。至于VM文件也只有在标记可用时用得上,全盘清理需要对整个数据文件进行扫描,用处不大。
增加一个隐藏列和系统赋值函数
我之前做增加系统表和SQL语法的时候,新建过一个系统表 ux_songbaibai,下面就拿它作为例子,看一下隐藏列:select a.relname,b.attname,b.atttypid from ux_class a join ux_attribute b on a.oid=b.attrelid and a.relname=‘ux_songbaibai’;

如上,我们就看到了下面的几个隐藏的属性了。
第一步:在E:\Mygit_depository\uxdb-ng\uxdb-2.0\src\include\access\sysattr.h下面为新增隐藏列timeid(这个跟之后做的题相关联上)如下:

大家不要把新增的属性放到最后面,因为当查询隐藏列会调用函数markRTEForSelectPriv的时候,col就是隐藏列的字段号,如果这个字段号小于FirstLowInvalidHeapAttributeNumber,相减的结果就是负数,程序就会报错
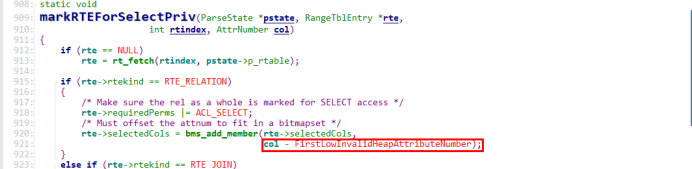
第二步:在E:\Mygit_depository\uxdb-ng\uxdb-2.0\src\backend\catalog\heap.c里面增加新增系统字段的定义

Form_ux_attribute SysAtt[]数组,类型为typedef FormData_ux_attribute *Form_ux_attribute;里面的FormData_ux_attribute的定义如下:

位于:E:\Mygit_depository\uxdb-ng\uxdb-2.0\src\include\catalog\ux_attribute.h
而我们这里增加的a9就是我们添加一个名为timeid的系统字段,TIMESTAMPOID(这是一个宏,定义在src/include/catalog/ux_type.h中,值是1114),长度是sizeof(Timestamp)。上面的SysAtt[]是FormData_ux_attribute类型的隐藏类数组,其中的隐藏列项是通过heap.c的AddNewAttributeTuples()增加到系统ux_attribute表中。
第三步:为新增系统字段分配存储空间。我们在新增系统字段后,这个元组占用的空间变大。对于新增的字段timeid,它的大小是sizeof(Timestamp),(也就是8个字节)。在构造元组(heap_form_tuple)时,需要为字段timeid分配空间并赋值。函数heap_form_tuple负责构造元组,它根据传入的元组描述符计算元组占用的内存空间大小,分配相应的内存,设置元组中的系统字段,最后根据传入的值数组构造出一个完整的元组。
在E:\Mygit_depository\uxdb-ng\uxdb-2.0\src\backend\access\common\heaptuple.c

上面的代码片段可以看见header长度计算分为四步:offsetof首先计算出到t_bits成员之前的长度;然后看看是否有null域,如果有的话必须分配一个bitmap来表示;然后看看是否有OID,如果有就加四个字节;最后对齐。在此加上新增字段的长度。
第四步:在E:\Mygit_depository\uxdb-ng\uxdb-2.0\src\include\access\htup_details.h里面增加,
增加我们这里的头文件#include “datatype/timestamp.h”,对timeid是否改变在tuple的header中进行标记,由于td->t_infomask的标记已经占满,这里选择td->t_infomask2进行标记:
#define HEAP2_TIMEID_CHANGED 0x0800(主要是用于在插值时标志该列的更新)

第五步:定义新增字段的get和set宏,用于获取和设置隐藏列的值
因为t_bits这个就是一个变长的,为了不改变UXDB现有的数据结构,这里将新增加的系统字段timeeid放在元组头的可变部分,也就是成员t_bits之后的部分。这部分空间取决于(tup)->t_infomask,只有当(tup)->t_infomask & HEAP_HASOID为真时,才会去分配Oid占用的空间。E:\Mygit_depository\uxdb-ng\uxdb-2.0\src\include\access\htup_details.h增加如下:

和
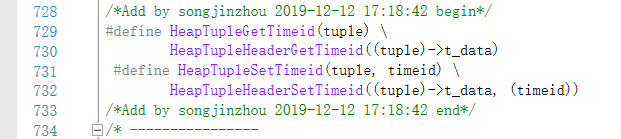
第六步:修改heap_getsysattr()函数,添加新增隐藏列的获取代码(不增加的话,select查询的时候查不到新增的字段)

第七步:增加系统函数给隐藏列赋值,系统表ux_proc中存储了所有的系统函数,新增的系统函数应insert到此系统表中。

其中“3”表时函数有三个参数,“19 26 1114”分别表时参数的类型为:19表示NAMEOID, 26表示OID,23表示TIMESTAMPOID
第八步:定义赋值函数
在E:\Mygit_depository\uxdb-ng\uxdb-2.0\src\backend\catalog\namespace.c下面

功能测试
重编之后,进行下面的测试:
- 创建包含oid的表,通过与ux_class、ux_attribute联合查询,确认隐藏列的存在
create table time_table (c1 int) with oids;
select a.relname,b.attname,b.atttypid from ux_class a join ux_attribute b on a.oid=b.attrelid and a.relname=‘time_table’;

2. 在time_table中插入一行数据,查看其oid以及tb_descr_id列的值

3. 调用赋值函数为隐藏列赋值,并查看结果
首先看一下,上面我们给插入系统表选择的那个OID为3430 如下:

如果没有这一步的话成功,下面不可能实现赋值操作!

OK,做了好几天了,成功!
select set_table_timeid(‘time_table’,16390,‘2019-12-13 18:20:59’);
实现代码
diff --git a/.gitignore b/.gitignore
index b638c3dfb..2afaa6262 100644
--- a/.gitignore
+++ b/.gitignore
@@ -8,6 +8,7 @@ build/
*.cache/
.settings/
*.classpath
+/uxdb-2.0/.vs
/boost_1_62_0/
uxdbadmin4-3.0_install/linux/build-linux
uxdbadmin4-3.0_install/linux/lib
diff --git a/uxdb-2.0/src/backend/access/common/heaptuple.c b/uxdb-2.0/src/backend/access/common/heaptuple.c
index 8fec9fa3f..c180fafac 100755
--- a/uxdb-2.0/src/backend/access/common/heaptuple.c
+++ b/uxdb-2.0/src/backend/access/common/heaptuple.c
@@ -587,6 +587,12 @@ heap_getsysattr(HeapTuple tup, int attnum, TupleDesc tupleDesc, bool *isnull)
case TableOidAttributeNumber:
result = ObjectIdGetDatum(tup->t_tableOid);
break;
+
+ /*Add by songjinzhou 2019年12月12日17:04:34 begin*/
+ case TabletimeAttributeNumber:
+ result = TimestampGetDatum(HeapTupleGetTimeid(tup));
+ break;
+ /*Add by songjinzhou 2019年12月12日17:04:34 end*/
default:
elog(ERROR, "invalid attnum: %d", attnum);
result = 0; /* keep compiler quiet */
@@ -802,6 +808,10 @@ heap_form_tuple(TupleDesc tupleDescriptor,
if (tupleDescriptor->tdhasoid)
len += sizeof(Oid);
+ /*Add by songjinzhou 2019-12-12 15:47:59 begin*/
+ len += sizeof(Timestamp);
+ /*Add by songjinzhou 2019-12-12 15:47:59 end*/
+
hoff = len = MAXALIGN(len); /* align user data safely */
data_len = heap_compute_data_size(tupleDescriptor, values, isnull);
diff --git a/uxdb-2.0/src/backend/access/heap/heapam.c b/uxdb-2.0/src/backend/access/heap/heapam.c
index c41b65913..ae18b50a0 100755
--- a/uxdb-2.0/src/backend/access/heap/heapam.c
+++ b/uxdb-2.0/src/backend/access/heap/heapam.c
@@ -3590,6 +3590,13 @@ heap_update(Relation relation, ItemPointer otid, HeapTuple newtup,
/* the new tuple is ready, except for this: */
newtup->t_tableOid = RelationGetRelid(relation);
+ /*Add by songjinzhou 2019-12-13 13:16:31 begin*/
+ if (!(newtup->t_data->t_infomask2 & HEAP2_TIMEID_CHANGED))
+ {
+ HeapTupleHeaderSetTimeid(newtup->t_data, HeapTupleHeaderGetTimeid(oldtup.t_data));
+ }
+ /*Add by songjinzhou 2019-12-13 13:16:31 end*/
+
/* Fill in OID for newtup */
if (relation->rd_rel->relhasoids)
{
diff --git a/uxdb-2.0/src/backend/catalog/heap.c b/uxdb-2.0/src/backend/catalog/heap.c
index 44e998280..4aa6168e7 100755
--- a/uxdb-2.0/src/backend/catalog/heap.c
+++ b/uxdb-2.0/src/backend/catalog/heap.c
@@ -208,8 +208,14 @@ static FormData_ux_attribute a8 = {
true, 'p', 'i', true, false, '\0', false, true, 0
};
-
-static const Form_ux_attribute SysAtt[] = {&a1, &a2, &a3, &a4, &a5, &a6, &a7, &a8};
+/*Add by songjinzhou 2019-12-12 14:48:00 begin*/
+static FormData_ux_attribute a9 = {
+ 0, {"timeid"}, TIMESTAMPOID, 0, sizeof(Timestamp),
+ TabletimeAttributeNumber, 0, -1, -1,
+ true, 'p', 'i', true, false, '\0', false, true, 0
+};
+static const Form_ux_attribute SysAtt[] = {&a1, &a2, &a3, &a4, &a5, &a6, &a7, &a8, &a9};
+/*Add by songjinzhou 2019-12-12 14:48:00 end*/
/* BEGIN: Added by LiuYongzhen For Column Storage, 2018/6/7 PN: */
diff --git a/uxdb-2.0/src/backend/catalog/namespace.c b/uxdb-2.0/src/backend/catalog/namespace.c
index 79f2abb01..20ba1e1d9 100755
--- a/uxdb-2.0/src/backend/catalog/namespace.c
+++ b/uxdb-2.0/src/backend/catalog/namespace.c
@@ -4397,3 +4397,47 @@ ux_is_other_temp_schema(UX_FUNCTION_ARGS)
UX_RETURN_BOOL(isOtherTempNamespace(oid));
}
+
+/*Add by songjinzhou 2019-12-12 19:06:57 begin*/
+Datum set_table_timeid(UX_FUNCTION_ARGS)
+{
+ //获取入参表名和修改后的timeid
+ Name tbName = UX_GETARG_NAME(0); //表名
+ Oid oid = UX_GETARG_OID(1); //指定的行的oid
+ Timestamp timeid = UX_GETARG_TIMESTAMP(2); //设置的timeid值
+
+ //Timestamp timeid = GetSQLLocalTimestamp(UX_GETARG_OID(3)); //get sql local
+
+ HeapTuple oldtime;
+ Oid RelId;
+ HeapScanDesc scan;
+ Relation relation;
+ bool find_time_tag = false;
+
+ RelId = RelnameGetRelid(NameStr(*tbName));
+ relation = heap_open(RelId, RowExclusiveLock);
+ scan = heap_beginscan(relation, GetActiveSnapshot(), 0, NULL);
+ //循环读表的每一行
+ while ((oldtime = heap_getnext(scan, ForwardScanDirection)) != NULL)
+ {
+ //判断是否是指定的行
+ if (oid == HeapTupleHeaderGetOid(oldtime->t_data))
+ {
+ find_time_tag = true;
+ break;
+ }
+ }
+ //找到指定的行
+ if (find_time_tag && HeapTupleIsValid(oldtime))
+ {
+ HeapTupleHeaderSetTimeid(oldtime->t_data, timeid);//设置该行timeid的值
+ oldtime->t_data->t_infomask2 |= HEAP2_TIMEID_CHANGED;//标识该行timeid的值已经更改了
+ simple_heap_update(relation, &oldtime->t_self, oldtime);//写入缓存中
+ }
+
+ heap_endscan(scan);
+ heap_close(relation, RowExclusiveLock);
+
+ UX_RETURN_BOOL(true);
+}
+/*Add by songjinzhou 2019-12-12 19:06:57 end*/
\ No newline at end of file
diff --git a/uxdb-2.0/src/include/access/htup_details.h b/uxdb-2.0/src/include/access/htup_details.h
index dda017304..1c6112967 100755
--- a/uxdb-2.0/src/include/access/htup_details.h
+++ b/uxdb-2.0/src/include/access/htup_details.h
@@ -20,7 +20,7 @@
#include "access/transam.h"
#include "storage/bufpage.h"
#include "executor/tuptable.h"
-
+#include "datatype/timestamp.h"
/*
* MaxTupleAttributeNumber limits the number of (user) columns in a tuple.
* The key limit on this value is that the size of the fixed overhead for
@@ -269,6 +269,10 @@ struct HeapTupleHeaderData
#define HEAP_HOT_UPDATED 0x4000 /* tuple was HOT-updated */
#define HEAP_ONLY_TUPLE 0x8000 /* this is heap-only tuple */
+/*Add by songjinzhou 2019-12-12 16:08:01 begin*/
+#define HEAP2_TIMEID_CHANGED 0x0800
+/*Add by songjinzhou 2019-12-12 16:08:01 end*/
+
#define HEAP2_XACT_MASK 0xE000 /* visibility-related bits */
/*
@@ -478,7 +482,27 @@ do { \
Assert((tup)->t_infomask & HEAP_HASOID); \
*((Oid *) ((char *)(tup) + (tup)->t_hoff - sizeof(Oid))) = (oid); \
} while (0)
-
+/*Add by songjinzhou 2019-12-12 16:59:41 begin*/
+#define HeapTupleHeaderGetTimeid(tup) \
+( \
+ ((tup)->t_infomask & HEAP_HASOID) ? \
+ *((Timestamp *) ((char *)(tup) + (tup)->t_hoff - sizeof(Oid) -sizeof(Timestamp))) \
+ : \
+ *((Timestamp *) ((char *)(tup) + (tup)->t_hoff - sizeof(Timestamp))) \
+)
+
+#define HeapTupleHeaderSetTimeid(tup, timeid) \
+do{ \
+ if((tup)->t_infomask & HEAP_HASOID) \
+ { \
+ *((Timestamp*)((char*)(tup)+(tup)->t_hoff - sizeof(Oid) - sizeof(Timestamp))) = (timeid); \
+ } \
+ else \
+ { \
+ *((Timestamp*)((char*)(tup)+(tup)->t_hoff - sizeof(Timestamp))) = (timeid); \
+ }\
+} while (0)
+/*Add by songjinzhou 2019-12-12 16:59:41 end*/
/*
* Note that we stop considering a tuple HOT-updated as soon as it is known
* aborted or the would-be updating transaction is known aborted. For best
@@ -701,7 +725,12 @@ struct MinimalTupleData
#define HeapTupleSetOid(tuple, oid) \
HeapTupleHeaderSetOid((tuple)->t_data, (oid))
-
+/*Add by songjinzhou 2019-12-12 17:18:42 begin*/
+#define HeapTupleGetTimeid(tuple) \
+ HeapTupleHeaderGetTimeid((tuple)->t_data)
+ #define HeapTupleSetTimeid(tuple, timeid) \
+ HeapTupleHeaderSetTimeid((tuple)->t_data, (timeid))
+/*Add by songjinzhou 2019-12-12 17:18:42 end*/
/* ----------------
* fastgetattr
*
diff --git a/uxdb-2.0/src/include/access/sysattr.h b/uxdb-2.0/src/include/access/sysattr.h
index 4053fec34..c4376c0b8 100755
--- a/uxdb-2.0/src/include/access/sysattr.h
+++ b/uxdb-2.0/src/include/access/sysattr.h
@@ -26,6 +26,10 @@
#define MaxCommandIdAttributeNumber (-6)
#define TableOidAttributeNumber (-7)
#define GpSegmentIdAttributeNumber (-8)
-#define FirstLowInvalidHeapAttributeNumber (-9) /*CDB*/
+
+/*Add by songjinzhou 2019-12-12 14:42:16 begin*/
+#define TabletimeAttributeNumber (-9)
+/*Add by songjinzhou 2019-12-12 14:42:36 end*/
+#define FirstLowInvalidHeapAttributeNumber (-10) /*CDB*/
#endif /* SYSATTR_H */
diff --git a/uxdb-2.0/src/include/catalog/ux_proc.h b/uxdb-2.0/src/include/catalog/ux_proc.h
index 1ba881705..df7991aa2 100755
--- a/uxdb-2.0/src/include/catalog/ux_proc.h
+++ b/uxdb-2.0/src/include/catalog/ux_proc.h
@@ -5483,7 +5483,8 @@ DESCR("get the license information loaded by the current DB service ");
+DATA(insert OID = 3430 (set_table_timeid UXNSP UXUID 12 1 0 0 0 f f f f t f s s 3 0 16 "19 26 1114" _null_ _null_ _null_ _null_ _null_ set_table_timeid _null_ _null_ _null_));
+DESCR("set table timeid");
@@ -5656,6 +5657,9 @@ DATA(insert OID = 4165 ( gp_delete_global_sequence_entry UXNSP UXUID 12 1 0 0 0
DESCR("Remove an entry from gp_global_sequence");