翻译自:HBase lookup in Spark Streaming
简介
在Spark Streaming应用中,HBase可用于处理流式数据过程中每个Batch进行lookup数据的高速缓存(即在Spark中对Hbase做实时读取),对这个缓存的查询是在每条Spark Streaming新到的消息的基础上去进行的。由于Spark Streaming是微批次(micro-batching)架构,有两种方法去完成这个需求:
-
在每个微批次中使用一个包括所有row key的set一次性从HBase中把整个batch的lookup操作做完。
-
在每个微批次中,每条单独记录中的key都到HBase里面进行lookup。
测试环境
这里提供4种可供选择的Spark和HBase的API进行lookup操作:
- Spark SQL + newAPlHadoopRDD
- Scan
- Get
- Multi-Get
上面4种API均在以下环境中进行测试:
- 从Kafka中消费9000个包含大量key value的Json记录
- 过滤出10个key value并使用它们的value去lookup一张包含2亿3千万数据的Hbase大表
- 根据key值把HBase的查询结果Join到记录当中
- 在Spark Streaming 计算图的最后执行collect操作。
API对比
newAPlHadoopRDD
newAPlHadoopRDD方法会在整个Hbase表中生成一个RDD。这个RDD会转化为一个能用于在HBase执行一般查询的data frame,但这个RDD对于时耗以及内存耗费的利用效率是非常低的。一个单点查询在2亿3千万的大表中进行需要6.5分钟,另外,这会导致executor因为内存问题而反复挂掉。
Scan
Scan API 当rowkeys为连续范围的情况下非常好用,使用bulk load时也非常好用,但使用Scan API在2亿3千万的大表中进行单点查询仍需要2.5分钟。
Get
Get API 在单点查询时是最为快速的,仅需要42ms,这令他比前面的方法更有效率,但是这对于微批次来说还是有点慢,如果一个batch有100条记录那么它将耗时4s,但每个batch的间隔可能仅为1s。
Multi-Get
Multi-Get API接受一个row key的列表作为输入,返回一个包含Result对象的数组,这个数组每个Result都包含输入列表中每个row key所相对应的HBase行。在查询一个2亿3千万的HBase大表的情况下,一个size为5000的batch,他会耗时200ms左右,一个size为19000的batch会耗时800ms左右。这个测试场景比一般业务场景都要严格一些,因此Multi-Get在微批次的角度来说完胜前面几种API。
总结
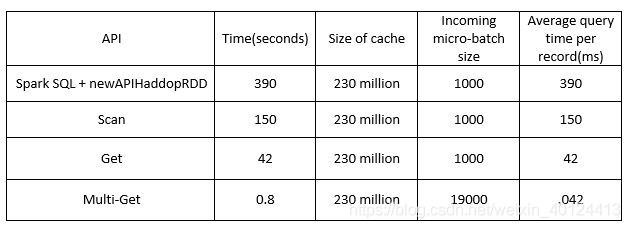
综上所述,在Spark Streaming中需要使用到HBase做缓存进行lookup的情况下,使用Multi-Get API是最快速的。