windows环境下使用Spark读取HBase
工具:IDEA
环境:jdk1.8,scala2.11
hbase:1.2-cdh5.16.1
spark:1.6-cdh5.16.1
hadoop:2.6.0-cdh5.16.1
以上组件都是用Cloudera Manager离线搭建的,不会的可参考另一篇博客
首先打开IDEA创建个scala项目,不过首先要下载scala插件

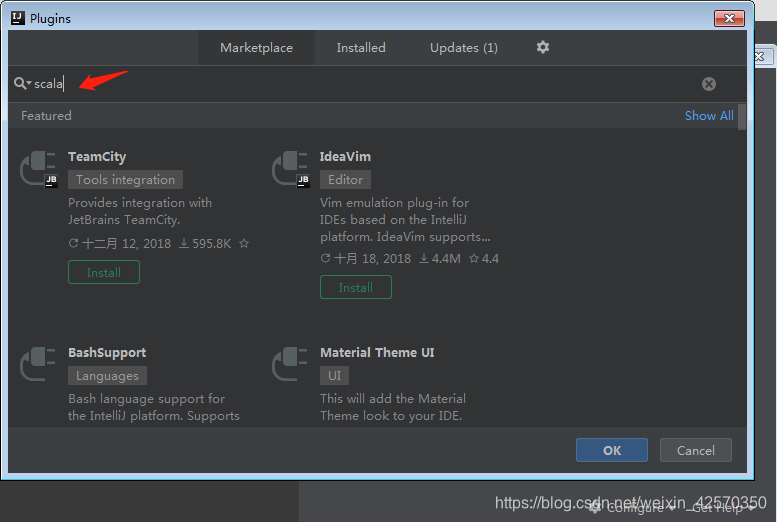
由于我是已经下载好了的,所以搜索不到,下载安装后重启下IDEA就可以开始创建项目了

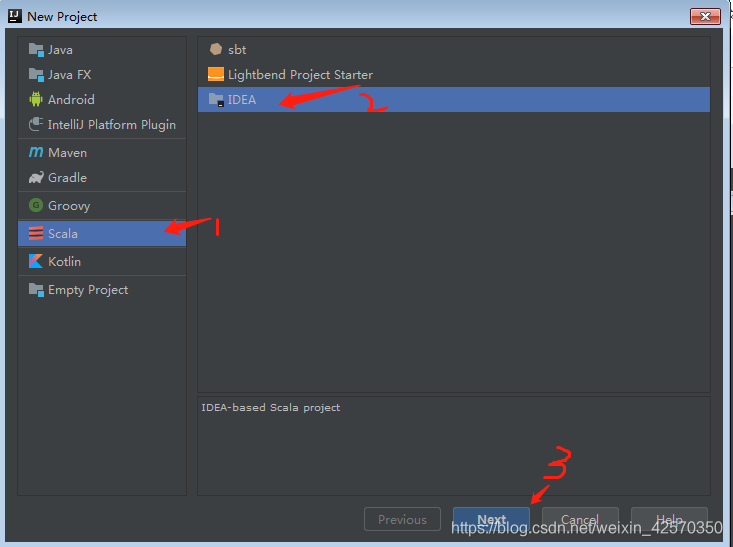
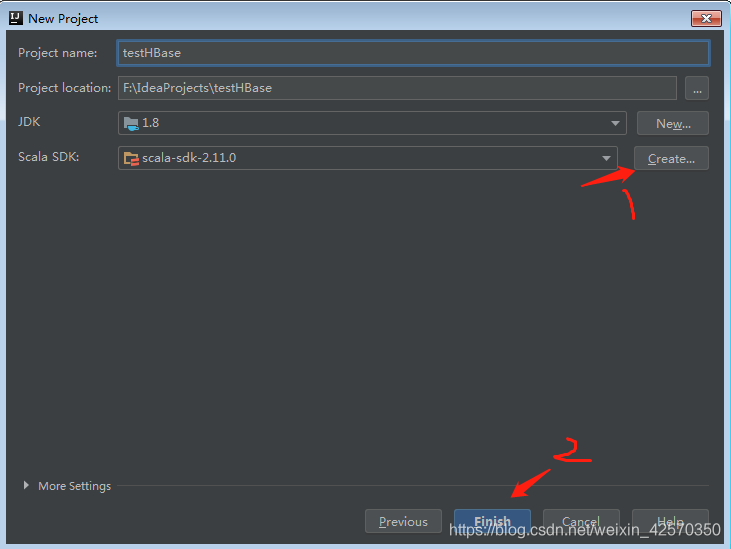
注意:第一次创建scala项目需要create一下,找到你本地安装的scala路径
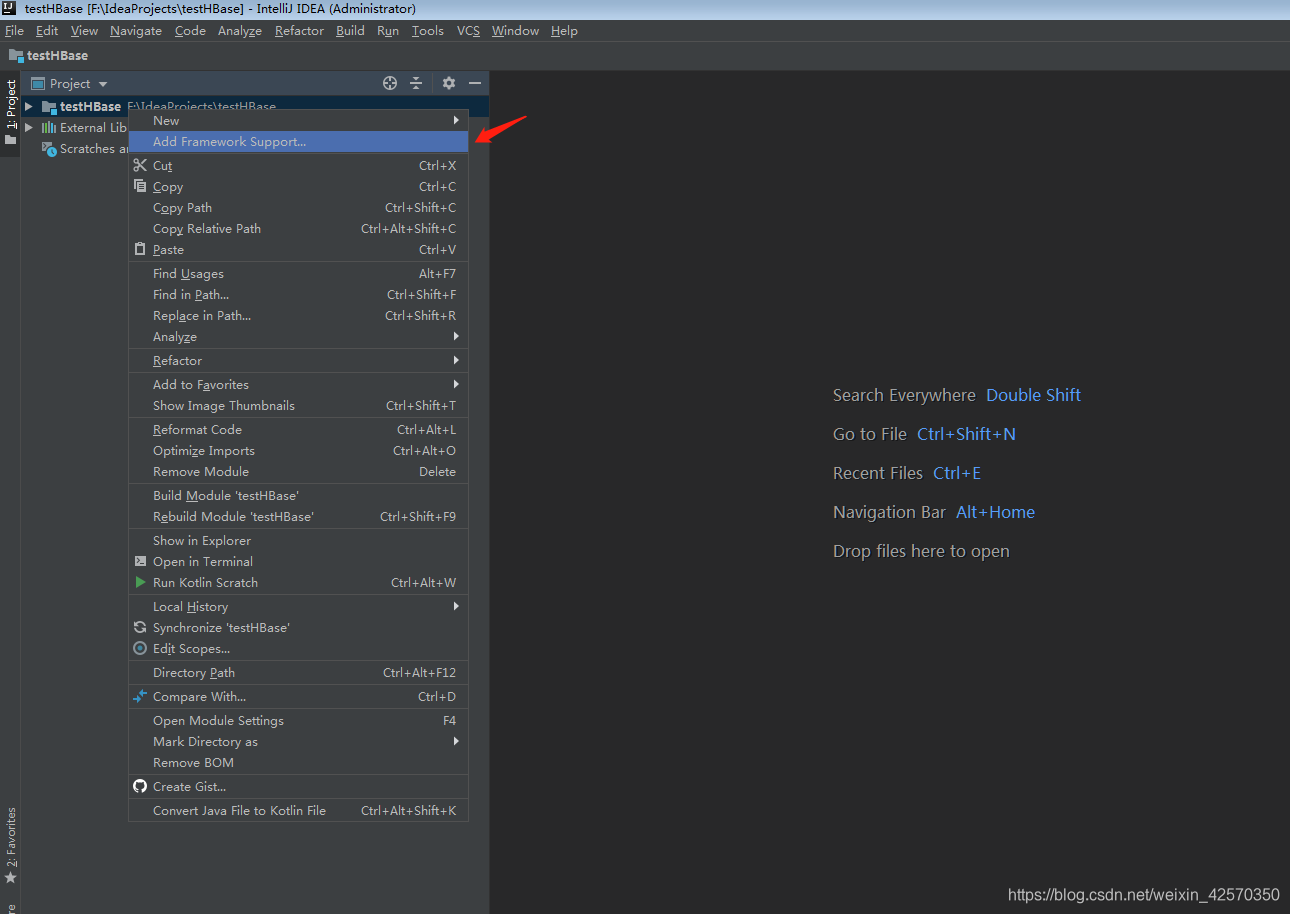 然后右键点击项目名,添加maven工具
然后右键点击项目名,添加maven工具
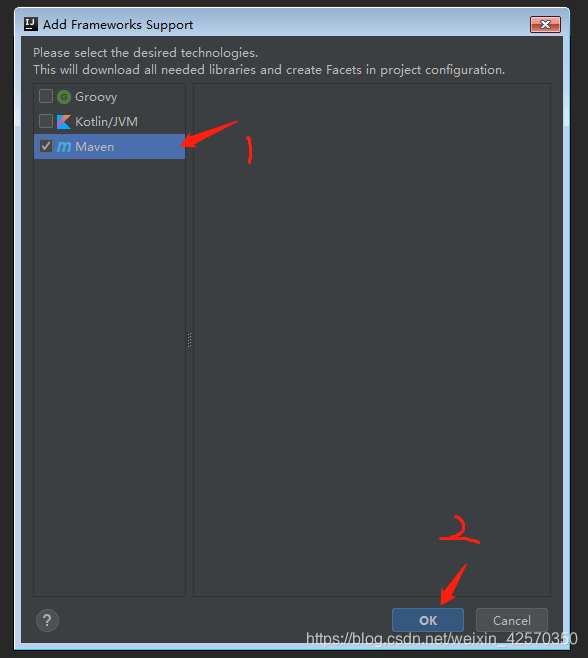
接下来开始添加maven依赖
<groupId>groupId</groupId>
<artifactId>testHBase</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>1.6.0</spark.version>
<scala.version>2.11</scala.version>
<hbase.version>1.2.0</hbase.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
</dependencies>
HBase里有一张testUwbMessage表,统计表有多少行,取十条数据查看
创建一个scala object,代码如下
package main.java.com.spark2hbase
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
object Spark_HBase {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("test")
.setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181")//zookeeper端口
hbaseConf.set("hbase.zookeeper.quorum","mf04,mf05,mf06")//zookeeper集群,我这里本地配了映射,所以写的主机名,建议直接写ip
hbaseConf.set(TableInputFormat.INPUT_TABLE,"testUwbMessage")//表名字
val hbaseRDD= sc.newAPIHadoopRDD(hbaseConf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])//转换成[key,value]形式的rdd
val count = hbaseRDD.count()
println(count)
hbaseRDD.map(_._2)
.map(a => (
Bytes.toString(a.getRow),//取出rowkey
Bytes.toString(a.getValue(Bytes.toBytes("info"), Bytes.toBytes("messageTime"))),//取出当前rowkey列簇为info列名为messagetime的cell
Bytes.toString(a.getValue(Bytes.toBytes("info"), Bytes.toBytes("labelId")))//取出当前rowkey列簇为info列名为labelId的cell
)
)
.take(10).foreach(println)
sc.stop
}
}
点击运行,统计结果是
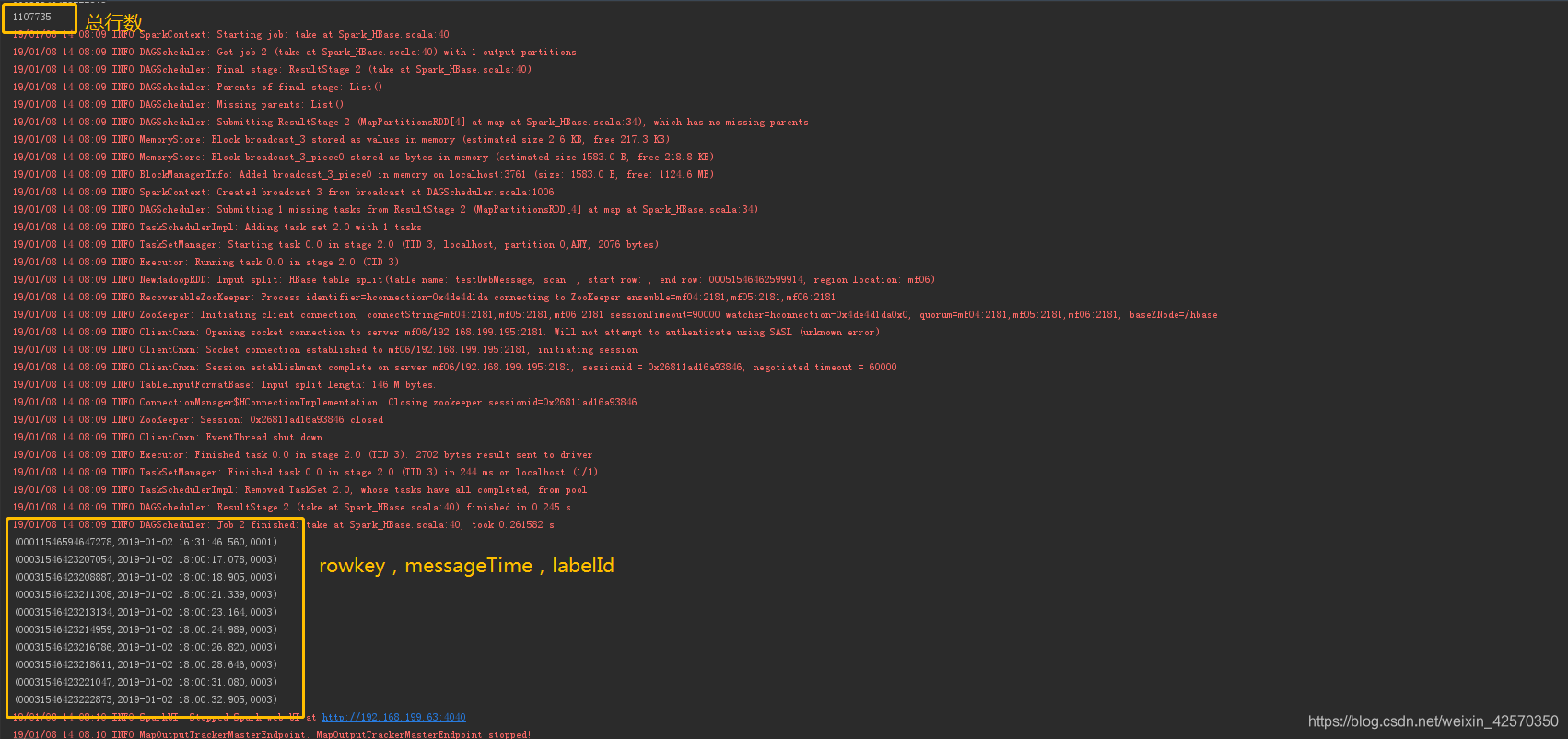
ok以上只是简单的row count和查询,我也是刚接触不久,有不对的地方欢迎指出纠正,谢谢!