所有文章
https://www.cnblogs.com/lay2017/p/12901123.html
正文
前面的文章中,我们学习了不少关于Java NIO相关的概念,比如:Selector、Channel、Buffer等,但是要设计一个非阻塞的服务器似乎还不够。要使用NIO构建非阻塞服务器比起BIO来说还是有不少挑战的。本文就针对几个要点进行讨论。
NIO Pipeline
pipeline是一条处理IO的链,这条链包含了多个组件。如图所示
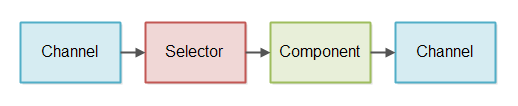
上图表示的是一个Component通过Selector监听Channel,并从Channel中read数据,而后Component生成数据,并向Channel中write。
pipeline其实并非总是同时需要read和write,有时候可能只需要read,也可能只需要write。
上图中仅仅展示了一个Component,其实可能会有更多的Component来处理read过来的数据。pipeline的长度多长,取决于要怎么处理数据。
pipeline也可能同时从多个Channel中读取数据,例如从多个SocketChannel读取网络传输过来的数据。
上图的流程经过简化,尽管流程是从左往右的,但并不是Channel把数据push给Selector再进入Component。而是Component通过Selector监听Channel,并read数据。
非阻塞 VS 阻塞 IO Pipeline
非阻塞IO的Pipeline和阻塞IO的Pipeline最大的区别点在于怎么从Channel中读取数据。
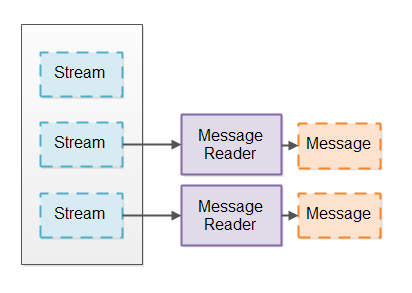
IO Pipeline总是把读取到的数据流分割成具有一定逻辑的信息,有点像是通过标记器把数据流分割成各种标记。这里的数据流将被分割成逻辑信息,如图所示,由message reader将数据流stream读取并分割为有意义的多个信息。

阻塞IO可以使用类似InputStream的实现类来处理message的分割,其实这样的处理方式相对是比较简单的。阻塞IO会一直等待有数据可以read,然后开始处理。就不会出现数据还没有准备好,或者数据只有一半的情况。
相似的,阻塞IO在写入数据的时候也会比较简单,同样不用处理写一般之类的问题。因此,阻塞IO其实针对MessageReader的实现是比较简单的。
阻塞IO的缺点
阻塞IO实现MessageReader比较简单,但同样的会有一些缺点。
由于阻塞IO必须阻塞等待数据可以read,基本上一个线程只能同时处理一个IO,效率比较低。如果你的服务器需要支撑高并发的话,那么这种一个线程一个IO的情况下是很难支持的。同时,每个线程都会占用一定的内存空间,如果有100万个线程,可能就得占用1TB的空间,更不用谈线程处理的内容需要再占用更多的空间了。
有一种做法是,维度固定的线程数来处理进入服务端的连接,如果未能被线程处理的连接就进入等待队列,如图
但是这种做法其实也没什么意义,因为阻塞IO的本质依旧是一个线程处理一个IO。也就是说,只要这个线程没有处理完毕,那么线程就会被占用着,当固定线程全部被占用达到最大值的时候,服务端就无响应了,也就完蛋了。不管你把线程池扩大到多少,反正都不能超过机器资源的限制,因此并发量也就被控制的死死的。因此,阻塞IO通过线程池这种做法其实是一种不合理的做法。
非阻塞IO的Pipeline
非阻塞IO可以利用单线程去读取多个流,前提条件是该流可以切换为非阻塞模式。当处于非阻塞模式的时候,一个流的读取可能返回0字节,因为在你读取数据的时候,可能流还并没有数据给你读取。
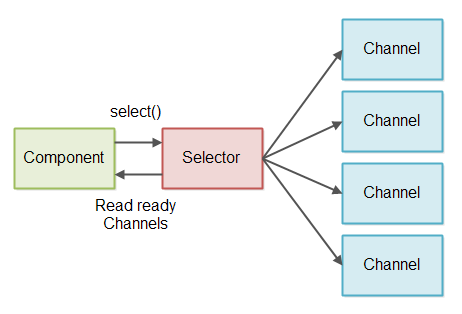
想要避免自己判断是否0字节的麻烦,可以和Selector选择器协同使用。多个Channel可以注册到Selector当中。当你调用select或者selectNow,可读的Channel会返回给你,如图
读取部分数据
当我们从Channel中读取数据以后,我们其实并不知道这部分数据是否能够组成一个有效信息。一个数据块可以是信息的一部分,也可以是一个完整的信息,或者超过一个完整的信息。如图
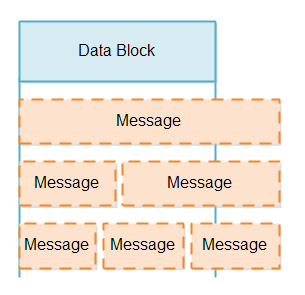
这里有两个问题需要考虑
1.校验数据块是否是一个完整的信息
2.在构成一个完整的信息之前,这部分提前读取的信息怎么处理
校验数据块是否是一个完整信息需要message reader来做,只有获取到一个或者多个的完整信息以后,才可以被传递并处理。
当数据块并不是一个完整的信息的时候,需要先储藏起来,等待一个完整的数据达到以后再处理。
这样看来,校验数据块和存储数据块都是由message reader来完成的。那么,为了避免同一个message reader处理不同Channel的造成数据混乱问题,所以一个message reader将对应一个Channel,如图
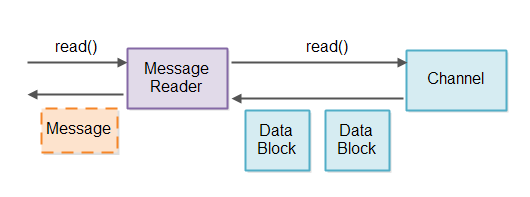
当Selector监听到Channel有数据到达的时候,找到Channel对应的message reader,如果构成一个完整信息,就沿着Pipeline向下传递信息并处理。
由此看来,message reader其实就是一种协议规范。message reader知道要传递过来的数据是什么样的格式,并能够按照协议进行处理。如果我们希望message reader可以复用,那么最好插件化它的实现,也许需要使用工厂来根据参数配置进行构造获取。
存储部分数据
前面我们提到了message reader读取到部分数据,需要先存储下来,等待完整信息的数据达到。那么,这个存储是怎么实现的呢
有两个考虑点需要注意
1.数据拷贝要尽可能的少,越少数据拷贝,性能越好
2.数据存储要有序,有序的数据更容易转化为完整信息
一个message reader一个Buffer
最简单的方式就是在每个message reader中内置一个Buffer。但是,Buffer的大小该是多少呢?
如果Buffer为1MB,而一个完整信息为10MB,超出了Buffer的大小,那也不行。况且,即使不超过1MB,当请求量很大的时候,单单Buffer占用的空间就会导致内存不足的问题了,这样和阻塞IO的问题其实没啥区别。
大小可变的Buffer
另一种思路是实现一个大小可变的Buffer。Buffer初始化很小,如果需要更大的空间的时候,Buffer会扩大。因为,不是每个请求都需要1MB空间的,如果很多请求都低于1Mb实际上可以减少消耗。
实现可变大小的Buffer有几种方式,下面一一了解
通过copy的方式实现
第一种方式是初始化一个小Buffer,例如只有4KB大小。如果4KB不能容纳,就分配一个8KB的Buffer,把4Kb中的数据copy到8KB的Buffer里面。
优点是,数据将会有序存放。
缺点就是大量数据拷贝操作,尤其是大数据量的时候。
优化方案也是有的,你可以分析一下请求,然后设计出多个大小层级的Buffer,例如:
1级,4kb
2级,128kb
3级,某个最大值
当大量的请求都是4KB的时候,其实都不需要拷贝。而少量请求是128kb的时候只需要一次拷贝,把4kb拷贝到128kb,而超过128kb的时候需要进行两次拷贝。容量扩大,但是次数也逐渐减少。
通过append的方式实现
另一种方式是构建一个包含多个数组的Buffer。这样你只需要新建一个数组,并写入数据即可。
优点是直接避免了数据拷贝,缺点就是你得从多个数组中读取数据并处理,这将增加信息构造的复杂度。
TLV编码的方式
tlv就是type、length、value,一些协议支持这种消息格式化的编码方式。着意味着,当一个消息达到的时候,消息的length将会被存储起来。你会知道需要分配多少内存给这个消息。
tlv使得内存管理相对简单,没有内存空间会被浪费。
有一个缺点是你需要事先分配内存空间,如果有一个大数据传输过来,就会占用很多内存,这也将可能导致服务不可用。
一个方法是包含多个tlv,这样你可以把一个大数据分割成多个来处理,减小了数据大小。但是,如果数据还是过大,那这个方法就不奏效了。
另一个方法是启用超时机制,如果一定时间内数据没有传递完,那么直接超时结束。这样起码可以让服务端避免被占用完,但是这种方式其实无法避免短时间内的服务不响应。另外,如果有人攻击服务器,故意让你的内存占满也是有问题的。
tlv存储许多变种,具体tlv指定type和length需要多少字节由每个tlv编码决定。也有的tlv把length放在type之前,然后才是value(应该称作ltv编码)。和tlv有点不同,但也是tlv的一个变种。
tlv编码使得内存管理更简单了,但也是http1.1协议的问题点之一。在http2.0中将致力于解决该问题,问题点在于数据也在ltv编码中一起传输。这也是为什么jenkov说要设计自己的网络协议的原因
写部分数据
在NIO的Pipeline中,写数据一样是一个挑战。当你调用write(ByteBuffer)到Channel,你无法知道有多少数据从ByteBuffer被写入到Channel。但是write方法会返回写入了多少数据,所以需要去跟踪写入多少数据,直到所有数据被写入完。
和读取部分数据的message reader类似,这里需要建立一个message writer。在message writer内部跟踪写入了多少数据。
以防多个数据传输混乱,需要把数据队列化,如图

为了检测Channel是否可以写入数据,你可能会想要直接register到Selector里面去。但是思考一下,如果有100万个Channel注册到Selector里面去,你就不得不校验这么多的message writer是否有数据做write。
要避免message writer的校验,需要按照以下两步
1.当一条消息入message writer。把关联的Channelregister到Selector
2.Selector会检测哪个Channel可以write,遍历Channel,并写入数据。如果写入完毕,Channel从Selector取消注册。
这两步确保了只有Channel实例拥有待写入数据的时候才会注册到Selector,避免没有数据的时候Selector大量检测
汇总
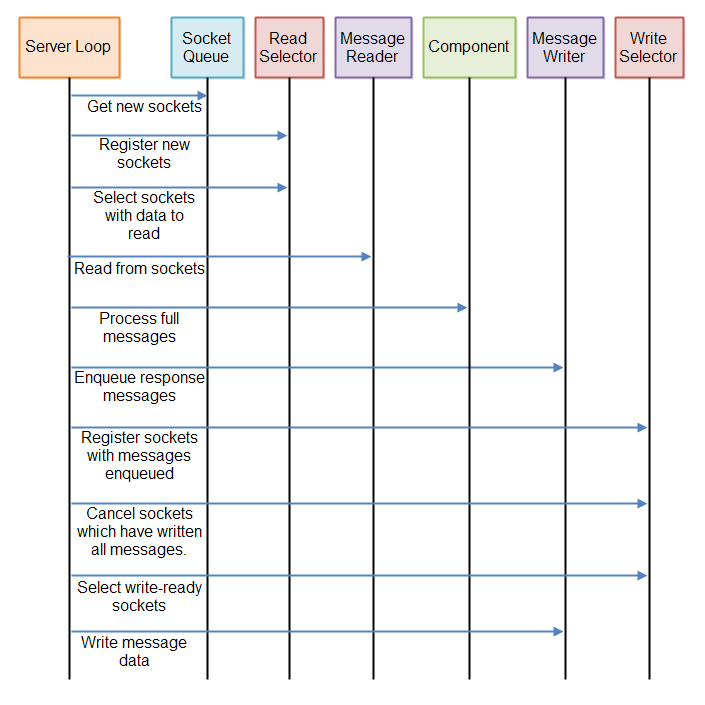
如你所见,非阻塞服务器需要时不时地校验接收的数据。服务器需要多次校验,直到有完整消息被接收。校验一次肯定是不够的
同样的,非阻塞服务器需要时不时校验是否有数据需要写入。如果有,服务器需要校验是否有连接准备好写入。由于消息可能部分写入,所以只是在消息第一次被队列化的时候校验是不够的。
需要按照如下规则执行
1.read需要去校验从Connection中读取来的数据
2.process只处理完整的信息
3.write要校验是否有待写入信息,且Connection可以写入
这三步将循环执行,如图
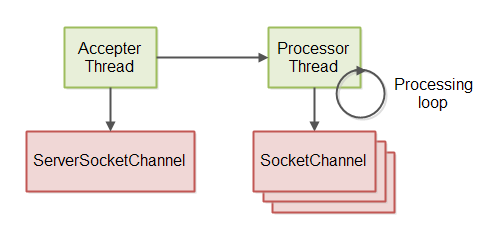
服务端线程模型
非阻塞服务器的线程模型实现采用了两个线程。第一个线程从ServerSocketChannel接收连接。第二个线程处理接收的连接,包括读取消息、处理消息、写入响应到连接。如图