了解到 pivot()函数可以实现
尝试一:
df = spark.sql("""
select payload.avatar_id as avatar,
local_dt as play_date,
count(distinct payload.account_id) as player_count
from dts_obt.eventtypeingameitems
where dt between "20200501" and "20200504"
and local_dt between "20200502" and "20200503"
group by payload.avatar_id,local_dt
order by payload.avatar_id,local_dt
""")
df.show()

这里我想要(以下是通过excel表格的透视表实现的)
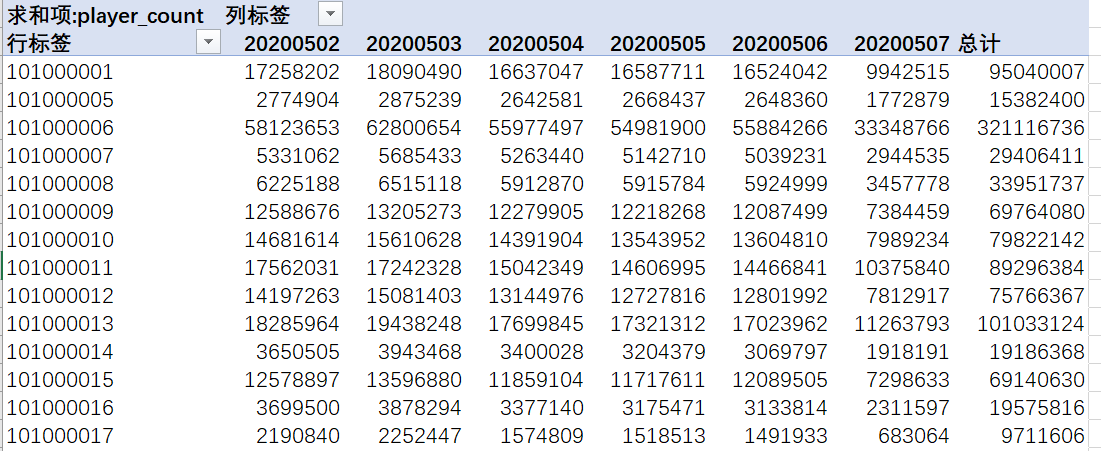
如何用pyspark实现?
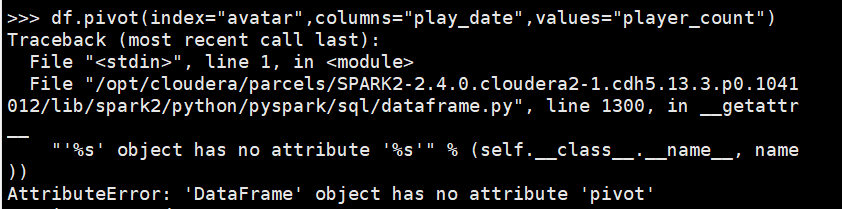
df.pivot(index="avatar",columns="play_date",values="player_count")
但是报错