1.BeautifulSoup库的理解: BeautifulSoup对应一个HTML/XML文档的全部内容;
2.BeautifulSoup库解析器:
bs4的HTML解析器:
使用方法:BeautifulSoup(mk,‘html.parser’);
条件:安装bs4库
lxml的HTML解析器:
使用方法:BeautifulSoup(mk,‘lxml’);
条件:pip install lmxl
lxml的XML解析器:
使用方法: BeautifulSoup(mk,‘xml’)
条件:pip install lxml html5lib的解析器:
使用方法:BeautifulSoup(mk,‘html5lib’);
条件:pip install html5lib
2.基本元素:
(1)Tag:标签,最基本的信息组织单元
(2)Name:标签的名字;
(3)Attributes:标签的属性,字典形式组织;
(4)NavigableString:标签内非属性字符串;
(5)Comment:标签内字符串的注释部分;
3.简单案例 :下面展示一些 简单实用。
import requests
r=requests.get("http://python123.io/ws/demo.html")
r.text
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")
soup.a.name
soup.a.parent.name
soup.a.parent.parent.name
tag=soup.a
tag.attrs
tag.attrs['class']
tag.attrs['href']
type(tag.attrs)
type(tag)
项目结果展示

5.基于bs4库的HTML内容遍历方法
标签树的遍历:下行遍历,上行遍历,平行遍历;
.contents:子节点的列表,将所有儿子节点存入列表 。
.children:子节点的迭代类型,与contents类似,用于循环遍历儿子节点 。
.descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历;
一.标签的下行遍历:
1.遍历儿子节点: for child in soup.body.children: print(child)
1.遍历子孙节点: for child in soup.body.children: print(child)
二. 标签的上行遍历
1.parent:节点的父亲标签;
2.parents:节点的先辈标签迭代类型,用于循环遍历先辈节点;
三.标签的平行遍历
1.遍历后续节点: for sibling in soup.a.next_siblings: print(sibling)
2.遍历前续节点: for sibling in soup.a.previous_siblings: print(sibling)
1.爬取python123网页
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
demo
结果展示

2.标签的下行遍历--访问儿子节点
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")
soup.head
soup.head.contents#访问儿子节点
soup.body.contents
len(soup.body.contents)#body儿子节点的个数
soup.body.contents[1]
代码结果展示:

3.标签的上行遍历--访问父亲节点
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")
soup.title.parent#查看父亲标签
soup.html.parent
代码运行结果展示:

4.标签的平行遍历
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")
soup.a.next_sibling#a的下一个平行标签
soup.a.next_sibling.next_sibling#a的下一个的下一个的标签
soup.a.previous_sibling#a的前一个节点的平行标签
soup.a.previous_sibling.previous_sibling
soup.a.parent
程序代码运行结果展示:

5.基于bs4库的HTML格式化和编码
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
demo
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")
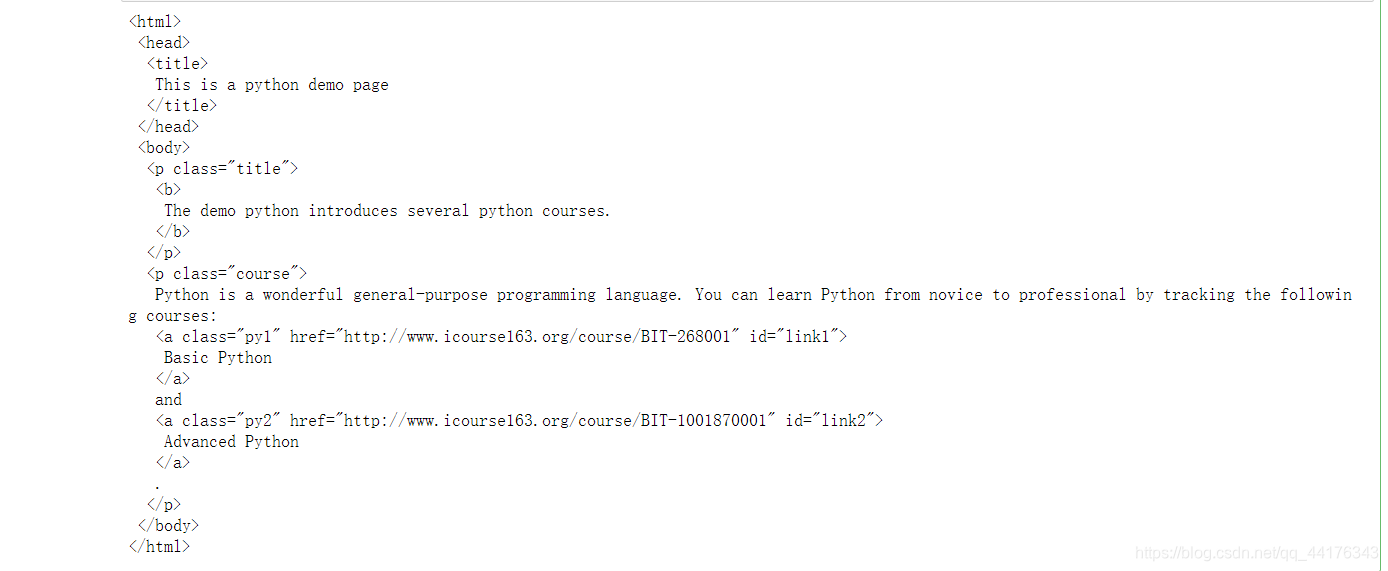
soup.prettify()
print(soup.prettify())#使代码分行显示,特别整齐
程序代码运行结果显示
6.bs4的编码
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup("<p>中文</p>","html.parser")
soup.p.string
print(soup.p.prettify())
程序代码运行结果:

7.信息提取的一般方法
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
demo
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")
for link in soup.find_all("a"):
print(link.get('href'))
程序代码运行结果展示:

8.基于bs4库的HTML内容查找方法
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
demo
from bs4 import BeautifulSoup
soup.find('a')
soup.find(['a','b'])
for tag in soup.find_all(True):
print(tag.name)
import re #引入正则表达式库
for tag in soup.find_all(re.compile('b')):#遍历出标签中以b开头的标签
print(tag.name)
程序代码运行结果展示

9.案例
import requests
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
demo
from bs4 import BeautifulSoup
soup.find_all('p','course')
soup.find_all(id='link1')
soup.find_all(id='link')
import re
soup.find_all(id=re.compile('link'))
程序代码运行结果显示:

