python提取语音信号MFCC
Mel频率倒谱系数(MFCC)的分析是基于人的听觉机理,即依据人的听觉实验结果来分析语音的频谱,期望获得好的语音特性。
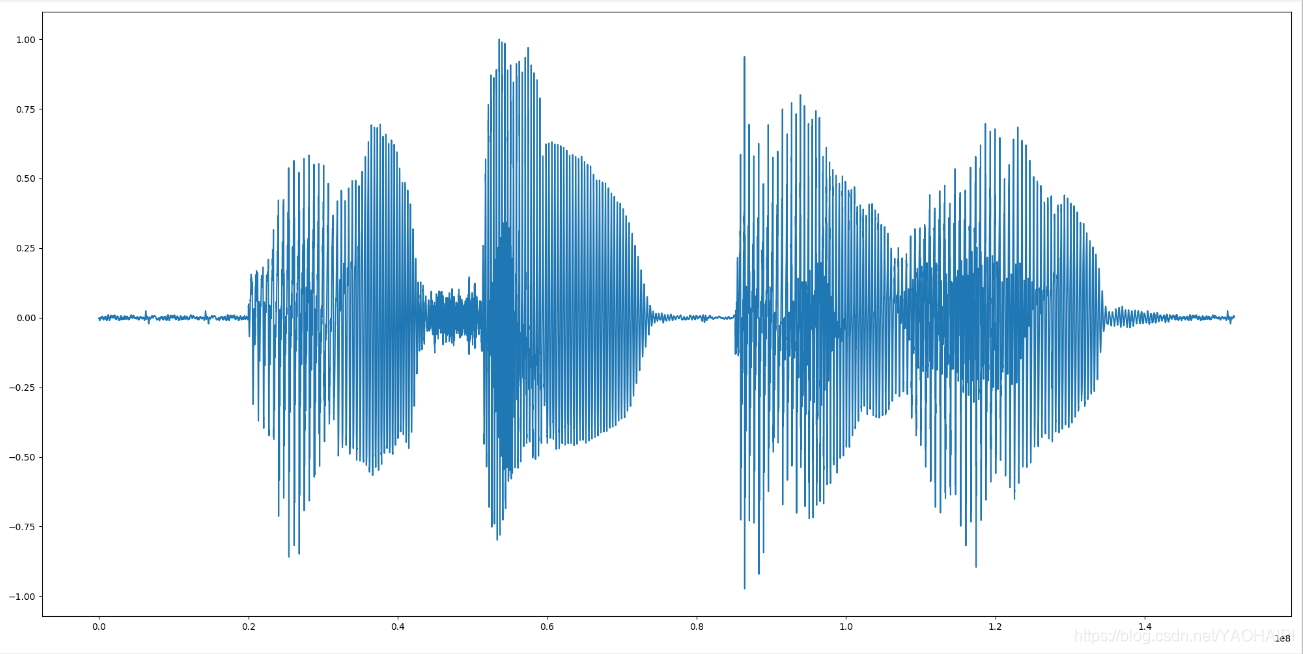
一、读取语音信号
import numpy as np
import wave
import matplotlib.pyplot as plt
from scipy.fftpack import dct
f = wave.open(r"lantian.wav", "rb")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
str_data = f.readframes(nframes)
signal = np.fromstring(str_data, dtype=np.short)
signal=signal*1.0/(max(abs(signal))) #归一化
python读取语音调用wave模块
nchannels: 声道数 1
sampwidth:量化位数 2
framerate:采样频率 8000
nframes:采样点数 19000
二、预加重
预加重的目的是为了补偿高频分量的损失,提升高频分量,预加重的滤波器常设为
变换后:
signal_add=np.append(signal[0],signal[1:]-0.97*signal[:-1]) #预加重
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pfA54HWO-1576392559693)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1576388987768.png)]](https://img-blog.csdnimg.cn/20191215145038978.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
三、分帧、加窗
分帧处理:由于语音信号是一个准稳态的信号,把它分成较短的帧,在每帧中可将其看做稳态信号,可用处理稳态信号的方法来处理。同时,为了使一帧与另一帧之间的参数能较平稳地过渡,在相邻两帧之间互相有部分重叠。
加窗函数:加窗函数的目的是减少频域中的泄漏,将对每一帧语音乘以汉明窗或海宁窗。语音信号x(n)经预处理后为xi(m),其中下标i表示分帧后的第i帧。
wlen=512
inc=128
N=512
if signal_len<wlen:
nf=1
else:
nf = int(np.ceil((1.0 * signal_len - wlen + inc) / inc))
pad_len=int((nf-1)*inc+wlen)
zeros=np.zeros(pad_len-signal_len)
pad_signal=np.concatenate((signal,zeros))
indices=np.tile(np.arange(0,wlen),(nf,1))+np.tile(np.arange(0,nf*inc,inc),(wlen,1)).T
indices=np.array(indices,dtype=np.int32)
frames=pad_signal[indices]
win=np.hanning(wlen)
四、快速傅里叶变换
对每一帧信号进行快速傅里叶变换。
for i in range(nf): #帧数
x=frames[i:i+1]
y=win*x[0]
a=np.fft.fft(y) #快速傅里叶变换
五、计算能量谱线
对每一帧数据计算能量谱线。
for i in range(nf):
x=frames[i:i+1]
y=win*x[0]
a=np.fft.fft(y)
b=np.square(abs(a)) #求FFT变换结果的模的平方
六、梅尔滤波器
人的听觉系统是一个特殊的非线性系统,它响应不同频率信号的灵敏度是不同的。在语音特征的提取上,人类听觉系统做得非常好,它不仅能提取出语义信息, 而且能提取出说话人的个人特征,这些都是现有的语音识别系统所望尘莫及的。如果在语音识别系统中能模拟人类听觉感知处理特点,就有可能提高语音的识别率。
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。
将普通频率转化为mel频率的公式为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BJXSCmBI-1576392559694)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1576392519332.png)]](https://img-blog.csdnimg.cn/20191215145100969.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
将mel频率转化为普通频率公式为:
梅尔滤波器组,每个滤波器的传递函数为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RT9e3Hab-1576392559694)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1576390569317.png)]](https://img-blog.csdnimg.cn/20191215145116711.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
每个滤波器在mel频率上是等带宽的。
中心频率f(m)可以表示为:
这里我采用m=24个滤波器
mel_high=1125*np.log(1+(framerate/2)/700) #mel最高频率
mel_point=np.linspace(0,mel_high,m+2) #将mel频率等距离分成m+2个点
Fp=700 * (np.exp(mel_point / 1125) - 1) #将等距分好的mel频率转换为实际频率
w=int(N/2+1)
df=framerate/N
fr=[]
for n in range(w): #mel滤波器的横坐标
frs=int(n*df)
fr.append(frs)
melbank=np.zeros((m,w))
for k in range(m+1): #画mel滤波器
f1=Fp[k-1] #三角形左边点的横坐标
f2=Fp[k+1] #三角形右边点的横坐标
f0=Fp[k] #三角形中心点点的横坐标
n1=np.floor(f1/df)
n2=np.floor(f2/df)
n0=np.floor(f0/df)
for j in range(w):
if j>= n1 and j<= n0:
melbank[k-1,j]=(j-n1)/(n0-n1)
if j>= n0 and j<= n2:
melbank[k-1,j]=(n2-j)/(n2-n0)
for c in range(w):
s[i,k-1]=s[i,k-1]+b[c:c+1]*melbank[k-1,c]
plt.plot(fr, melbank[k - 1,])
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZkVrw9aq-1576392559695)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1576391540230.png)]](https://img-blog.csdnimg.cn/20191215145128213.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
具体过程可参考:
[梅尔滤波器组的分析与设计思路]: https://blog.csdn.net/tengfei0973/article/details/103182621
七、离散余弦变换(DCT)
logs=np.log(s) #取对数
num_ceps=12
D = dct(logs,type = 2,axis = 0,norm = 'ortho')[:,1 : (num_ceps + 1)]
因为语音信号特征主要集中在低频部分,所以一般选用每一帧信号的前12个滤波器作为MFCC参数。
八、总结
MFCC参数主要用来做语音识别和端点检测。
总代码:
import numpy as np
import wave
import matplotlib.pyplot as plt
from scipy.fftpack import dct
f = wave.open(r"lantian.wav", "rb")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
str_data = f.readframes(nframes)
signal = np.fromstring(str_data, dtype=np.short)
signal=signal*1.0/(max(abs(signal)))
signal_len=len(signal)
#预加重
signal_add=np.append(signal[0],signal[1:]-0.97*signal[:-1]) #预加重
time=np.arange(0,nframes)/1.0*framerate
#plt.figure(figsize=(20,10))
#plt.subplot(2,1,1)
#plt.plot(time,signal)
#plt.subplot(2,1,2)
#plt.plot(time,signal_add)
#plt.show()
#分帧
wlen=512
inc=128
N=512
if signal_len<wlen:
nf=1
else:
nf = int(np.ceil((1.0 * signal_len - wlen + inc) / inc))
pad_len=int((nf-1)*inc+wlen)
zeros=np.zeros(pad_len-signal_len)
pad_signal=np.concatenate((signal,zeros))
indices=np.tile(np.arange(0,wlen),(nf,1))+np.tile(np.arange(0,nf*inc,inc),(wlen,1)).T
indices=np.array(indices,dtype=np.int32)
frames=pad_signal[indices]
win=np.hanning(wlen)
m=24
s=np.zeros((nf,m))
for i in range(nf):
x=frames[i:i+1]
y=win*x[0]
a=np.fft.fft(y)
b=np.square(abs(a))
mel_high=1125*np.log(1+(framerate/2)/700)
mel_point=np.linspace(0,mel_high,m+2)
Fp=700 * (np.exp(mel_point / 1125) - 1)
w=int(N/2+1)
df=framerate/N
fr=[]
for n in range(w):
frs=int(n*df)
fr.append(frs)
melbank=np.zeros((m,w))
for k in range(m+1):
f1=Fp[k-1]
f2=Fp[k+1]
f0=Fp[k]
n1=np.floor(f1/df)
n2=np.floor(f2/df)
n0=np.floor(f0/df)
for j in range(w):
if j>= n1 and j<= n0:
melbank[k-1,j]=(j-n1)/(n0-n1)
if j>= n0 and j<= n2:
melbank[k-1,j]=(n2-j)/(n2-n0)
for c in range(w):
s[i,k-1]=s[i,k-1]+b[c:c+1]*melbank[k-1,c]
plt.plot(fr, melbank[k - 1,])
plt.show()
logs=np.log(s)
num_ceps=12
D = dct(logs,type = 2,axis = 0,norm = 'ortho')[:,1 : (num_ceps + 1)]
print(D)
print(np.shape(D))
输出结果:一个146×12的矩阵 146代表帧数,12代表每帧的MFCC系数
[[ 4.84318860e+01 5.43872867e+01 2.97738841e+01 … -1.80842897e+01
-2.56759247e+01 -3.18041757e+01]
[-7.09811701e+00 -5.86839796e+00 -4.37673606e+00 … 3.47982198e+00
4.99207591e+00 6.14210310e+00]
[-1.46795072e+01 -1.88020165e+01 -9.72372794e+00 … -8.57395667e+00
-1.24359229e+01 -1.45616032e+01]
…
[-2.27406690e-01 -1.80257328e-01 -5.82389817e-01 … -1.26641927e-01
-2.98866486e-02 -6.72742599e-02]
[-1.74213838e-01 -2.16393861e-01 -1.68467011e-01 … 4.40449351e-02
-1.80765461e-02 2.14003905e-02]
[-1.06398728e-01 -6.37571905e-02 -1.43970643e-01 … 1.37202632e-01
-7.46614028e-02 8.66251398e-02]]
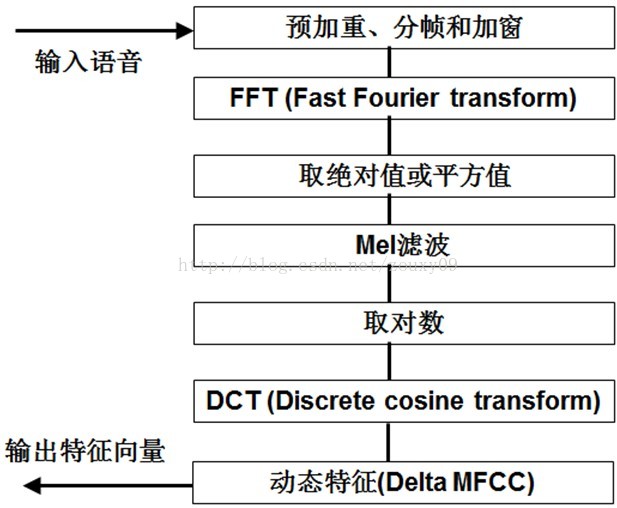
MFCC提取流程图:
matlab代码(来自书本)
clear all;
clc;
clear all;
[x,fs]=audioread('H:\语音信号处理\speech_signal\bluesky3.wav');
p=24;
frameSize=512;
inc=128;
bank=melbankm(p,frameSize,fs,0,0.5,'m');
% 归一化Mel滤波器组系数
bank=full(bank);
bank=bank/max(bank(:));
p2=p/2;
% DCT系数,p2*p
for k=1:p2
n=0:p-1;
dctcoef(k,:)=cos((2*n+1)*k*pi/(2*p));
end
% 归一化倒谱提升窗口
w = 1 + 6 * sin(pi * [1:p2] ./ p2);
w = w/max(w);
% 预加重滤波器
xx=double(x);
xx=filter([1 -0.9375],1,xx);
% 语音信号分帧
xx=enframe(xx,frameSize,inc);
n2=fix(frameSize/2)+1;
% 计算每帧的MFCC参数
for i=1:size(xx,1)
y = xx(i,:);
s = y' .* hamming(frameSize);
t = abs(fft(s));
t = t.^2;
c1=dctcoef * log(bank * t(1:n2));
c2 = c1.*w';
m(i,:)=c2';
end
%差分系数
dtm = zeros(size(m));
for i=3:size(m,1)-2
dtm(i,:) = -2*m(i-2,:) - m(i-1,:) + m(i+1,:) + 2*m(i+2,:);
end
dtm = dtm / 3;
%合并MFCC参数和一阶差分MFCC参数
ccc = [m dtm];
%去除首尾两帧,因为这两帧的一阶差分参数为0
ccc = ccc(3:size(m,1)-2,:);
