1,架构图示

第一层、数据采集层
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat做日志收集,然后把采集到的原始日志发送到Kafka+zookeeper集群上。
第二层、消息队列层
原始日志发送到Kafka+zookeeper集群上后,会进行集中存储,此时,filbeat是消息的生产者,存储的消息可以随时被消费。
第三层、数据分析层
Logstash作为消费者,会去Kafka+zookeeper集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch集群。
第四层、数据持久化存储
Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到Elasticsearch集群上。
第五层、数据查询、展示层
Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。
什么是分布式系统?
分布式系统就是在不同地域分布的多个服务器,共同组成的一个应用系统来为用户提供服务,在分布式系统中最重要的是进程的调度。
传统的方式是采用一个备用节点解决单点故障问题,可能会出现脑裂问题。
Zookeeper是如何进行工作的?
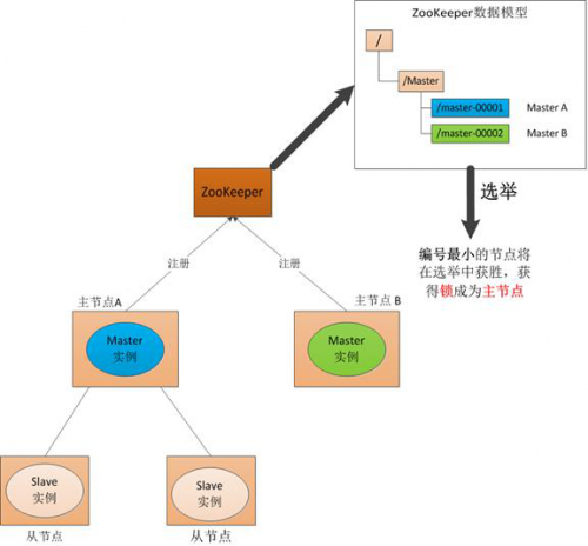
(1) Master启动
在分布式系统中引入Zookeeper以后,就可以配置多个主节点,这里以配置两个主节点为例,假定它们是"主节点A"和"主节点B",当两个主节点都启动后,它们都会向ZooKeeper中注册节点信息。我们假设"主节点A"锁注册的节点信息是"master00001","主节点B"注册的节点信息是"master00002",注册完以后会进行选举,选举有多种算法,这里以编号最小作为选举算法,那么编号最小的节点将在选举中获胜并获得锁成为主节点,也就是"主节点A"将会获得锁成为主节点,然后"主节点B"将被阻塞成为一个备用节点。这样,通过这种方式Zookeeper就完成了对两个Master进程的调度。完成了主、备节点的分配和协作。
(2) Master故障 如果"主节点A"发生了故障,这时候它在ZooKeeper所注册的节点信息会被自动删除,而ZooKeeper会自动感知节点的变化,发现"主节点A"故障后,会再次发出选举,这时候"主节点B"将在选举中获胜,替代"主节点A"成为新的主节点,这样就完成了主、被节点的重新选举。
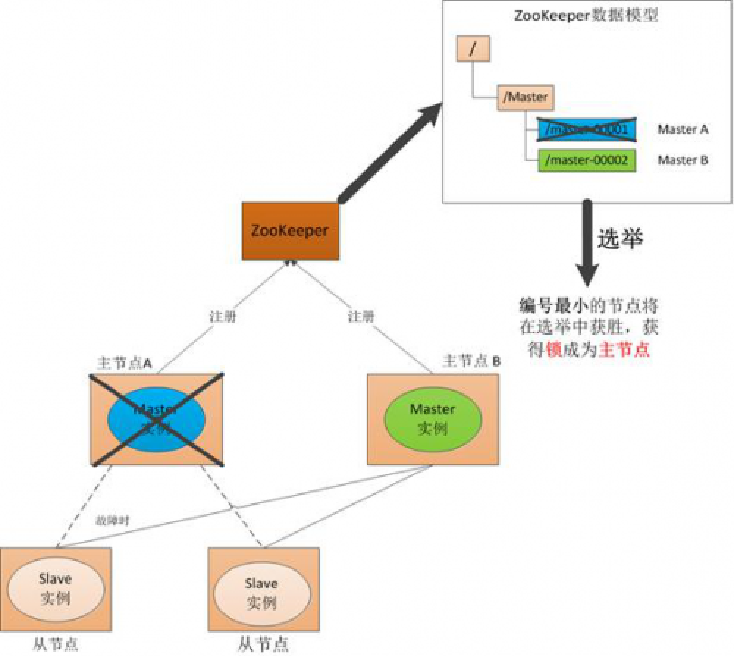
3)Master恢复 如果主节点恢复了,它会再次向ZooKeeper注册自身的节点信息,只不过这时候它注册的节点信息将会变成"master00003",而不是原来的信息。ZooKeeper会感知节点的变化再次发动选举,这时候"主节点B"在选举中会再次获胜继续担任"主节点","主节点A"会担任备用节点。 Zookeeper就是通过这样的协调、调度机制如此反复的对集群进行管理和状态同步的。
Zookeeper集群主要角色有Server和client,其中,Server又分为Leader、Follower和Observer三个角色,每个角色的含义如下:

Leader:领导者角色,主要负责投票的发起和决议,以及更新系统状态。
Follower:跟随者角色,用于接收客户端的请求并返回结果给客户端,在选举过程中参与投票。
Observer:观察者角色,用户接收客户端的请求,并将写请求转发给leader,同时同步leader状态,但不参与投票。Observer目的是扩展系统,提高伸缩性。
Client:客户端角色,用于向Zookeeper发起请求。
Zookeeper集群中每个Server在内存中存储了一份数据,在Zookeeper启动时,将从实例中选举一个Server作为leader,Leader负责处理数据更新等操作,当且仅当大多数Server在内存中成功修改数据,才认为数据修改成功。
Zookeeper写的流程为:客户端Client首先和一个Server或者Observe通信,发起写请求,然后Server将写请求转发给Leader,Leader再将写请求转发给其它Server,其它Server在接收到写请求后写入数据并响应Leader,Leader在接收到大多数写成功回应后,认为数据写成功,最后响应Client,完成一次写操作过程。
kafka是一个分布式的基于发布订阅的消息队列。Kafka是基于发布订阅模式的消费者主动拉取数据模式。
1,什么是消息队列?
传统消息队列有2种应用场景:
1)同步处理
2)异步处理
2,消息队列有2种模式:
1)点模式(生产者发送一条消息到queue,只有一个消费者能收到。)
在点对点消息系统中,消息持久化到一个队列中。此时,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。
2)发布/订阅模式
在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。
3,发布订阅模式又包含2种获取数据的模式:
1)消费者主动拉取数据模式
2)队列queue主动推送数据模式
Kafka的一个新的机器,启动后,对应的ids会在ZooKeeper中注册,这样集群就会得到对应的机器信息,从而加入集群。
kafka角色术语
在介绍架构之前,先了解下kafka中一些核心概念和各种角色。
Broker:Kafka集群包含一个或多个服务器,每个服务器被称为broker。
Topic:每条发布到Kafka集群的消息都有一个分类,这个类别被称为Topic(主题)。
Producer:指消息的生产者,负责发布消息到Kafka broker。
Consumer :指消息的消费者,从Kafka broker拉取数据,并消费这些已发布的消息。
Partition:Parition是物理上的概念,每个Topic包含一个或多个Partition,每个partition都是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(称为offset)。
Consumer Group:消费者组,可以给每个Consumer指定消费者组,若不指定消费者组,则属于默认的group。
Message:消息,通信的基本单位,每个producer可以向一个topic发布一些消息。
一个典型的Kafka集群包含若干Producer,若干broker、若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。

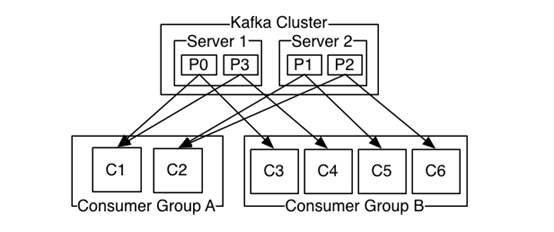
消费规则:
1、不同 Consumer Group下的消费者可以消费partition中相同的消息,相同的Consumer Group下的消费者只能消费partition中不同的数据。
2、topic的partition的个数和同一个消费组的消费者个数最好一致,如果消费者个数多于partition个数,则会存在有的消费者消费不到数据。
3、服务器会记录每个consumer的在每个topic的每个partition下的消费的offset,然后每次去消费去拉取数据时,都会从上次记录的位置开始拉取数据。
其实Kafka最核心的思想是使用磁盘,而不是使用内存,使用磁盘操作有以下几个好处:
1、磁盘缓存由Linux系统维护,减少了程序员的不少工作。
2、磁盘顺序读写速度超过内存随机读写。
3、JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题。
4、系统冷启动后,磁盘缓存依然可用。