1 elk简介
elk 简介
elk 下载安装下载地址:https://www.elastic.co/downloads 建议在 linux上运行,elk在windows上支持得不好,另外需要jdk1.8 的支持,需要提前安装好jdk. |
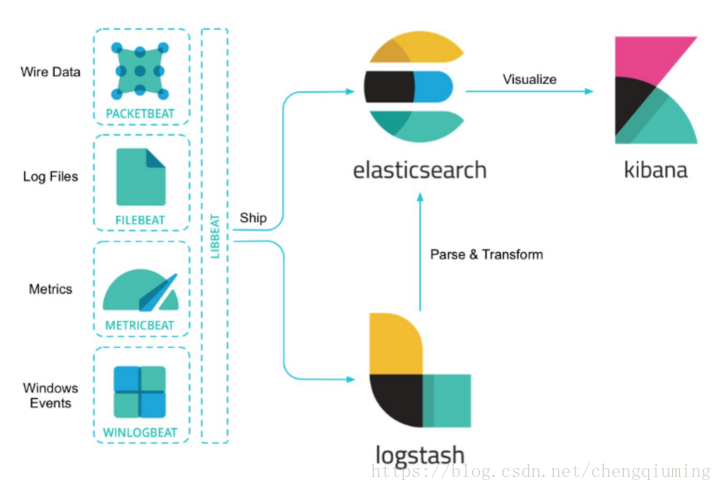
2 elk架构
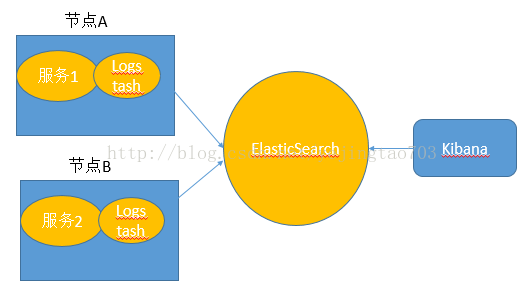
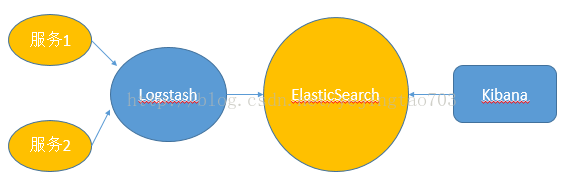
| Spring Cloud Sleuth与ELK整合时实际上只要与Logstash对接既可,所以我们要为Logstash准备好Json格式的日志信息。SpringBoot默认使用logback来记录日志,而Logstash自身也有对logback日志工具的支持工具,所以可以直接通过在logback配置中增加Logstash的Appender来非常方便的将日志转化为Json的格式存储和输出了。 Spring Cloud Sleuth与Logstash的直接集成有两种方式: Logstash与微服务应用安装在一起,监听日志文件 Logstash独立部署,微服务节点通过网络向Logstash发送日志信息。 之所以上面用了直接这个词,因为还存在间接形式的变种,微服务将日志发送给Redis或者MQ,再由他们去对接Logstash。 |
3 elk 安装
3.1 es安装启动1 解压 tar -zxvf elasticsearch-6.3.2.tar.gz 2 修改配置文件 [root@study08 elasticsearch]# grep "^[a-z]" elasticsearch.yml 3 启动 ./bin/elasticsearch 版本查看:curl -XGET localhost:9200 配置信息:network.host: 0.0.0.0 http.port: 8088
后台启动:./elasticsearch -d 4 启动失败 4.1 内存不足 修改jvm.properties文件 4.2 不能以root用户启动 Caused by: java.lang.RuntimeException: can not run elasticsearch as root 新的版本安全级别 提高了,不允许采用root启动,我们需要添加一个新的用户 4.3elasticsearch max virtual memory areas vm.max_map_count [65530] is too low 切换到root用户修改配置sysctl.conf vi /etc/sysctl.conf vm.max_map_count=655360 sysctl -p 4.4 Error: Could not find or load main class org.elasticsearch.tools.JavaVersionChecker openjdk version "1.8.0_181" 原因:没有权限 虽然此文件夹属于elasticsearch;但是此用户没有权限调用java 没有办法打开java的位置! 3. 2 head插件安装参考:https://www.jianshu.com/p/8091adadfc1b https://blog.csdn.net/u012637358/article/details/80780601 安装包准备:elasticsearch-head-master.zip 1 解压 uzip elasticsearch-head-master cd elasticsearch-head-master 2 辅助:node.js环境 elasticsearch-head插件需要nodejs的支持! node-v8.11.3-linux-x64.tar.xz
解压 配置环境变量 #set node environment 验证版本:node -v 验证版本:npm -v 常规NodeJS的搭建到现在为止已经完成了 3 正式安装 cd elasticsearch-head-master npm install ----ERR! [email protected] install: `node install.js 解决方案:npm -g install [email protected] --ignore-script 或者通过cnm安装 cnpm install
npm install -g cnpm --registry=https://registry.npm.taobao.org [root@node1 ~]# npm install -g grunt root@node1 ~]# npm install -g grunt-cli --registry=https://registry.npm.taobao.org --no-proxy 4 修改ip 端口号 启动 vi Gruntfile.js: hostname: '0.0.0.0', 启动:[root@node1 elasticsearch-head-master]$ grunt server === npm run start 后台启动:nohup grunt server & exit 5、为es设置跨域访问(必须授权 才能添加集群连接信息) 3.3 安装sql插件 参考:https://blog.csdn.net/upshi/article/details/79799508#2%E5%AE%89%E8%A3%85head%E6%8F%92%E4%BB%B6 3.4 es运维常见:1 分为unassinged 解决方法:重新分配分片
解决方法:删除分片 curl -XDELETE http://127.0.0.1:9200/logstash-2015.06.0* 查询为分片的数据: curl -s 'localhost:8088/_cat/shars 'localhost:8088/_cat/shards' | fgrep UNASSIGNED 参考链接: https://blog.csdn.net/zxf_668899/article/details/53945145 https://blog.csdn.net/laoyang360/article/details/78443006 https://discuss.elastic.co/t/how-to-resolve-the-unassigned-shards/87635/2 |

4 elk logstash 安装
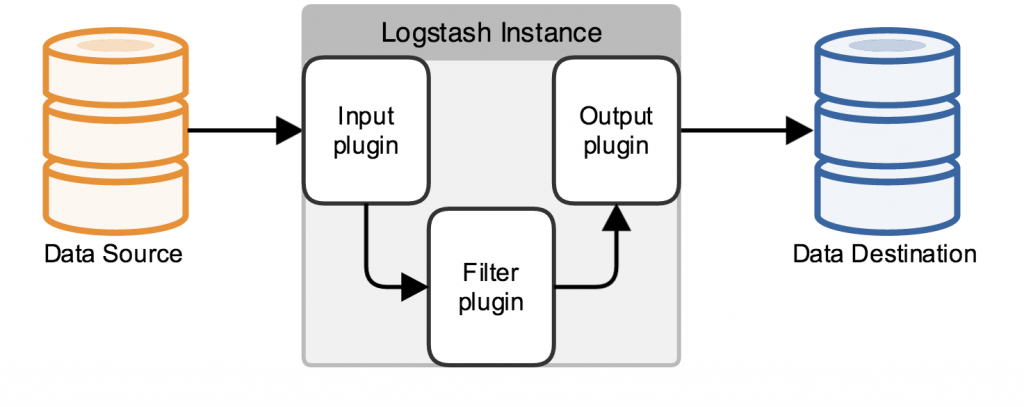
4.1 简介Logstash是一个开源的、接受来自多种数据源(input)、过滤你想要的数据(filter)、存储到其他设备的日志管理程序。 Logstash包含三个基本插件input\filter\output! 一个基本的logstash服务必须包含input和output! 4.2 架构原理Logstash数据处理有三个阶段,input–>filter–>output.input生产数据,filter根据定义的规则修改数据,output将数据输出到你定义的存储位置。
Inputs: 数据生产商,包含以下几个常用输出:
Filters: filters相当一个加工管道,它会一条一条过滤数据根据你定义的规则,常用的filters如下:
Outputs:
4.3 安装Logstash运行仅仅依赖java运行环境(jre),JDK版本1.8以上即可。直接从ELK官网下载Logstash:https://www.elastic.co/cn/products
现在我们来运行一下一个简单的例子: 我们现在可以在命令行下输入一些字符,然后我们将看到logstash的输出内容:
Ok,还挺有意思的吧… 以上例子我们在运行logstash中,定义了一个叫”stdin”的input还有一个”stdout”的output,无论我们输入什么字符,Logstash都会按照某种格式来返回我们输入的字符。这里注意我们在命令行中使用了-e参数,该参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。 我们再输入一些字符,这次我们输入”hello world ”:
以上示例通过重新设置了叫”stdout”的output(添加了”codec”参数),我们就可以改变Logstash的输出表现。 类似的我们可以通过在你的配置文件中添加或者修改inputs、outputs、filters,就可以使随意的格式化日志数据成为可能, 从而订制更合理的存储格式为查询提供便利。 前面已经说过Logstash必须有一个输入和一个输出,上面的例子表示从终端上输入并输出到终端。 数据在线程之间以事件的形式流传。不要叫行,因为Logstash可以处理多行事件。 input { # 输入域,可以使用上面提到的几种输入方式。stdin{} 表示标准输入,file{} 表示从文件读取。 input的各种插件: https://www.elastic.co/guide/en/logstash/current/input-plugins.html } output { #Logstash的功能就是对数据进行加工,上述例子就是Logstash的格式化输出,当然这是最简单的。 output的各种插件:https://www.elastic.co/guide/en/logstash/current/output-plugins.html } 4.4 指定配置文件启动Logstash配置文件和命令: Logstash的默认配置已经够我们使用了,从5.0后使用logstash.yml文件,可以将一些命令行参数直接写到YAML文件即可。
一个简单的Logstash从文件中读取配置
4.5 常用插件grok插件: Grok是Logstash最重要的插件,你可以在grok里自定义好命名规则,然后在grok参数或者其他正则表达式中引用它。 kv插件:自动处理类似于key=value样式的数据
geoip插件:主要是查询IP地址归属地,用来判断访问网站的来源地 4.6 常用自定义配置文件收集参考https://blog.csdn.net/hellolovelife/article/details/81560278 |

5 elk kibana 安装
| 安装准备文件:kibana-6.3.2-linux-x86_64.tar.gz 1 解压 tar -xzvf kibana-5.2.0-darwin-x86_64.tar.gz 2 设置执行es vim /data/kibana-6.3.0/config/kibana.yml 添加内容: server.port: 5601 3 切换到bin启动 ./kibana 后台启动: 4 查看日志 |