一、前言
在实际的业务场景中,Redis 一般和其他数据库搭配使用,用来减轻后端数据库的压力,比如和关系型数据库 MySQL 配合使用。
Redis 会把 MySQL 中经常被查询的数据缓存起来,比如热点数据,这样当用户来访问的时候,就不需要到 MySQL 中去查询了,而是直接获取 Redis 中的缓存数据,从而降低了后端数据库的读取压力。如果说用户查询的数据 Redis 没有,此时用户的查询请求就会转到 MySQL 数据库,当 MySQL 将数据返回给客户端时,同时会将数据缓存到 Redis 中,这样用户再次读取时,就可以直接从 Redis 中获取数据。流程图如下所示:
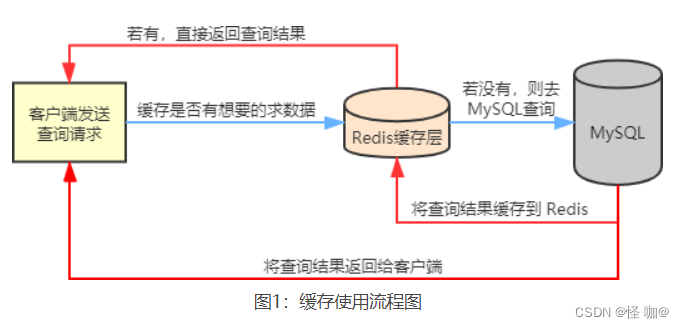
当我们使用缓存时,目标通常有两个:第一,提升响应效率和并发量;第二,减轻数据库的压力。
而本文中所提到的这三种场景:缓存穿透、缓存雪崩和缓存击穿的发生,都是因为在某些特殊情况下,缓存失去了预期的功能所致。
当缓存失效或没有抵挡住流量,流量直接涌入到数据库,在高并发的情况下,可能直接击垮数据库,导致整个系统崩溃。
这就是我们需要知道的大前提,而缓存穿透、缓存雪崩和缓存击穿,只不过是在这个大前提下的不同场景的细分场景而已。
二、缓存穿透
1、问题描述
缓存穿透是指当用户查询某个数据时,Redis 中不存在该数据,也就是缓存没有命中,此时查询请求就会转向持久层数据库 MySQL,结果发现 MySQL 中也不存在该数据,MySQL 只能返回一个空对象,代表此次查询失败。如果这种类请求非常多,或者用户利用这种请求进行恶意攻击,就会给 MySQL 数据库造成很大压力,甚至于崩溃,这种现象就叫缓存穿透。
注:虽然查询数据库为空,但是sql语句已经执行了,只要sql语句执行就会给mysql增压,特别是复杂的查询有时候会特别消耗cpu,cpu爆满直接就宕机了!
扫描二维码关注公众号,回复: 15894746 查看本文章
缓存穿透发生的场景一般有两类:
- 原来数据是存在的,但由于某些原因(误删除、主动清理等)在缓存和数据库层面被删除了,但前端或前置的应用程序依旧保有这些数据;
- 恶意攻击行为,利用不存在的Key或者恶意尝试导致产生大量不存在的业务数据请求。
2、解决方案
总体来看,计算机解决问题的思路无非就两个:空间换时间,时间换空间。当然,目前的算法都集中于空间换时间。
- 缓存空对象:
当 MySQL 返回空对象时, Redis 将该对象缓存起来,同时为其设置一个过期时间。当用户再次发起相同请求时,就会从缓存中拿到一个空对象,用户的请求被阻断在了缓存层,从而保护了后端数据库,但是这种做法也存在一些问题,虽然请求进不了 MySQL ,但是这种策略会占用 Redis 的缓存空间。 - 业务逻辑前置校验: 在业务请求的入口处进行数据合法性校验,检查请求参数是否合理、是否包含非法值、是否恶意请求等,提前有效阻断非法请求。比如,根据年龄查询时,请求的年龄为-10岁,这显然是不合法的请求参数,直接在参数校验时进行判断返回。
- 用户黑名单限制: 当发生异常情况时,实时监控访问的对象和数据,分析用户行为,针对故意请求、爬虫或攻击者,进行特定用户的限制;
- 进行实时监控: 当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
- 布隆过滤器: 我们知道,布隆过滤器判定不存在的数据,那么该数据一定不存在,利用它的这一特点可以防止缓存穿透。
首先将用户可能会访问的热点数据存储在布隆过滤器中(也称缓存预热),当有一个用户请求到来时会先经过布隆过滤器,如果请求的数据,布隆过滤器中不存在,那么该请求将直接被拒绝,否则将继续执行查询。相较于第一种方法,用布隆过滤器方法更为高效、实用。其流程示意图如下:
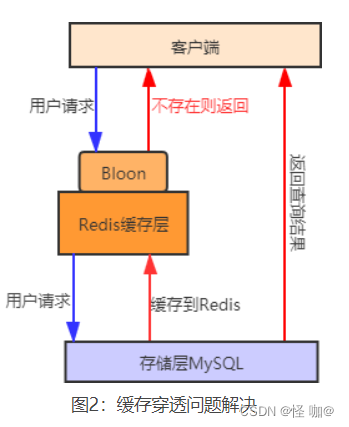
缓存预热:是指系统启动时,提前将相关的数据加载到 Redis 缓存系统中。这样避免了用户请求的时再去加载数据。
三、缓存击穿
1、问题描述
缓存击穿是指用户查询的数据缓存中不存在,但是后端数据库却存在,这种现象出现原因是一般是由缓存中 key 过期导致的。比如一个热点数据 key,它无时无刻都在接受大量的并发访问,如果某一时刻这个 key 突然失效了,就致使大量的并发请求进入后端数据库,导致其压力瞬间增大。这种现象被称为缓存击穿。
2、解决方案
- 改变过期时间: 设置热点数据永不过期。
- 分布式锁: 采用分布式锁的方法,重新设计缓存的使用方式,过程如下:
- 上锁:当我们通过 key 去查询数据时,首先查询缓存,如果没有,就通过分布式锁进行加锁,第一个获取锁的进程进入后端数据库查询,并将查询结果缓到Redis 中。
- 解锁:当其他进程发现锁被某个进程占用时,就进入等待状态,直至解锁后,其余进程再依次访问被缓存的 key。
- 实时调整: 现场监控哪些数据热门,实时调整key的过期时长
四、缓存雪崩
1、问题描述
缓存雪崩是指缓存中大批量的 key 同时过期,而此时数据访问量又非常大,从而导致后端数据库压力突然暴增,甚至会挂掉,这种现象被称为缓存雪崩。它和缓存击穿不同,缓存击穿是在并发量特别大时,某一个热点 key 突然过期,而缓存雪崩则是大量的 key 同时过期,因此它们根本不是一个量级。
所以,缓存雪崩的场景通常有两个:
- 大量热点key同时过期;
- 缓存服务故障;
2、解决方案
缓存雪崩和缓存击穿有相似之处,所以解决方案都是互通的。
- 构建多级缓存架构: nginx缓存 + redis缓存 +其他缓存(ehcache等)
- 使用锁或队列: 用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
- 设置过期标志更新缓存: 记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
- 将缓存失效时间分散开: 比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
- 不设置过期时间: 热点数据可以考虑不失效,后台异步更新缓存,适用于不严格要求缓存一致性的场景。
- 双key策略:主key设置过期时间,备key不设置过期时间,当主key失效时,直接返回备key值。
五、总结
很多人会把缓存穿透和击穿搞混,主要是名词方面的混淆。更多的,我觉得关注意思即可。
缓存穿透与击穿的区别:
- 穿透:数据库里“没”数据;
- 击穿:数据库里“有”数据;
提起来穿透我们就去想象王者荣耀的破甲碎星锤,无视防御装备,因为缓存压根没有,并且数据库也没有,所以直接打真伤。
缓存击穿可以规避,因为只是 redis 缓存数据失效了,而数据库里有数据,只要把数据库里的数据更新到 redis 上,那么就可以解决掉缓存击穿的问题。
但是,缓存穿透,意味着,这个数据,数据库里也没有。所以,就不可能会把数据存到 redis 缓存里,因此只要有人来查询,就一定缓存中查不到,所以就一定要走数据库。那么,假设很多人,故意去查那些数据库里也没有的记录,我们的 redis 就起不到屏障的作用,因为 redis 里不可能有数据,所以并发查询就一定会打到数据库的身上。那么,想要解决缓存穿透,就必须想办法,能够识别出,哪些请求的数据,是数据库没有的,然后,对这些请求的查询,进行过滤。
而缓存雪崩更多的指多处被击穿这才引发的雪崩。
针对不同的缓存异常场景,可选择不同的方案来进行处理。当然,除了上述方案,我们还可以限流、降级、熔断等服务层的措施,也可以考虑数据库层是否可以进行横向扩展,当缓存异常发生时,确保数据库能够抗住流量,不至于让整个系统崩溃。