文章目录
首先,看Map的主要的实现类的简化 继承层次图:
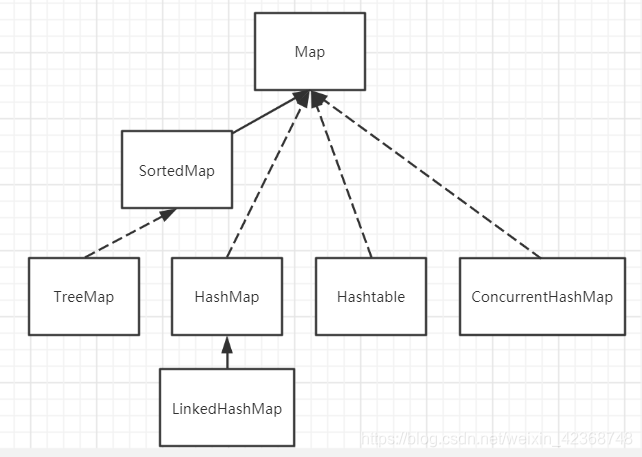
Map
public interface Map<K,V>
将键映射到值的对象。
一个映射不能包含重复的键;每个键最多只能映射到一个值。
此接口取代 Dictionary 类,后者完全是一个抽象类,而不是一个接口。
Map 接口提供三种 collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容。映射顺序定义为迭代器在映射的 collection 视图上返回其元素的顺序。(某些映射实现可明确保证其顺序,如 TreeMap 类;另一些映射实现则不保证顺序,如 HashMap 类)
主要方法:

Map.Entry
public static interface Map.Entry<K,V>
映射项(键-值对)。可看作是Map中存储的一个单位。
方法摘要:

获得映射项引用的唯一方法是通过此 collection 视图的迭代器来实现。但可以自己创建新的实现类对象(充当类似pair来使用)。
Map.Entry有两个主要的实现类:AbstractMap.SimpleEntry<K,V> 和 AbstractMap.SimpleImmutableEntry<K,V> .
AbstractMap.SimpleEntry
维护键和值的 Entry。可以使用 setValue 方法更改值。此类简化了构建自定义映射实现的过程。例如,可以使用 Map.entrySet().toArray 方法方便地返回 SimpleEntry 实例数组。

留意 toString() 方法。返回此映射项的 String 表示形式。此实现返回此项的键的字符串表示形式,后跟等号 ("="),然后是此项的值的字符串表示形式。
AbstractMap.SimpleImmutableEntry
维护不可变的键和值的 Entry。此类不支持 setValue 方法。在返回线程安全的键-值映射关系快照的方法中,此类也许很方便。
构造方法和主要方法与前者一样。除了setValue()方法会现抛出 UnsupportedOperationException。
TreeMap
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, Serializable
特点:
- 基于红黑树实现。
- 根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序。
- 继承了NavigableMap接口(继承了SortedMap接口),可支持一系列的导航定位以及导航操作的方法。
- 为 containsKey、get、put 和 remove 操作提供受保证的 log(n) 时间开销。
- 不是同步的。解决方法:
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
构造方法:

常用方法:(参考)
增添元素:
V put(K key, V value):将指定映射放入该TreeMap中
V putAll(Map map):将指定map放入该TreeMap中
删除元素:
void clear():清空TreeMap中的所有元素
V remove(Object key):从TreeMap中移除指定key对应的映射
修改元素:
V replace(K key, V value):替换指定key对应的value值
boolean replace(K key, V oldValue, V newValue):当指定key的对应的value为指定值时,替换该值为新值
查找元素:
boolean containsKey(Object key):判断该TreeMap中是否包含指定key的映射
boolean containsValue(Object value):判断该TreeMap中是否包含有关指定value的映射
Map.Entry<K, V> firstEntry():返回该TreeMap的第一个(最小的)映射
K firstKey():返回该TreeMap的第一个(最小的)映射的key
Map.Entry<K, V> lastEntry():返回该TreeMap的最后一个(最大的)映射
K lastKey():返回该TreeMap的最后一个(最大的)映射的key
v get(K key):返回指定key对应的value
SortedMap<K, V> headMap(K toKey):返回该TreeMap中严格小于指定key的映射集合
SortedMap<K, V> subMap(K fromKey, K toKey):返回该TreeMap中指定范围的映射集合(大于等于fromKey,小于toKey)
遍历方式:
for (Map.Entry entry : treeMap.entrySet()) {
System.out.println(entry);
}
Iterator iterator = treeMap.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
HashMap
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
基于哈希表的 Map 接口的实现。
特点:
- 有两个参数影响其性能:初始容量和加载因子。
- 容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。
- 加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。
- 当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
- 不是同步的。
- 解决方法:
Map m = Collections.synchronizedMap(new HashMap(...));
- 解决方法:
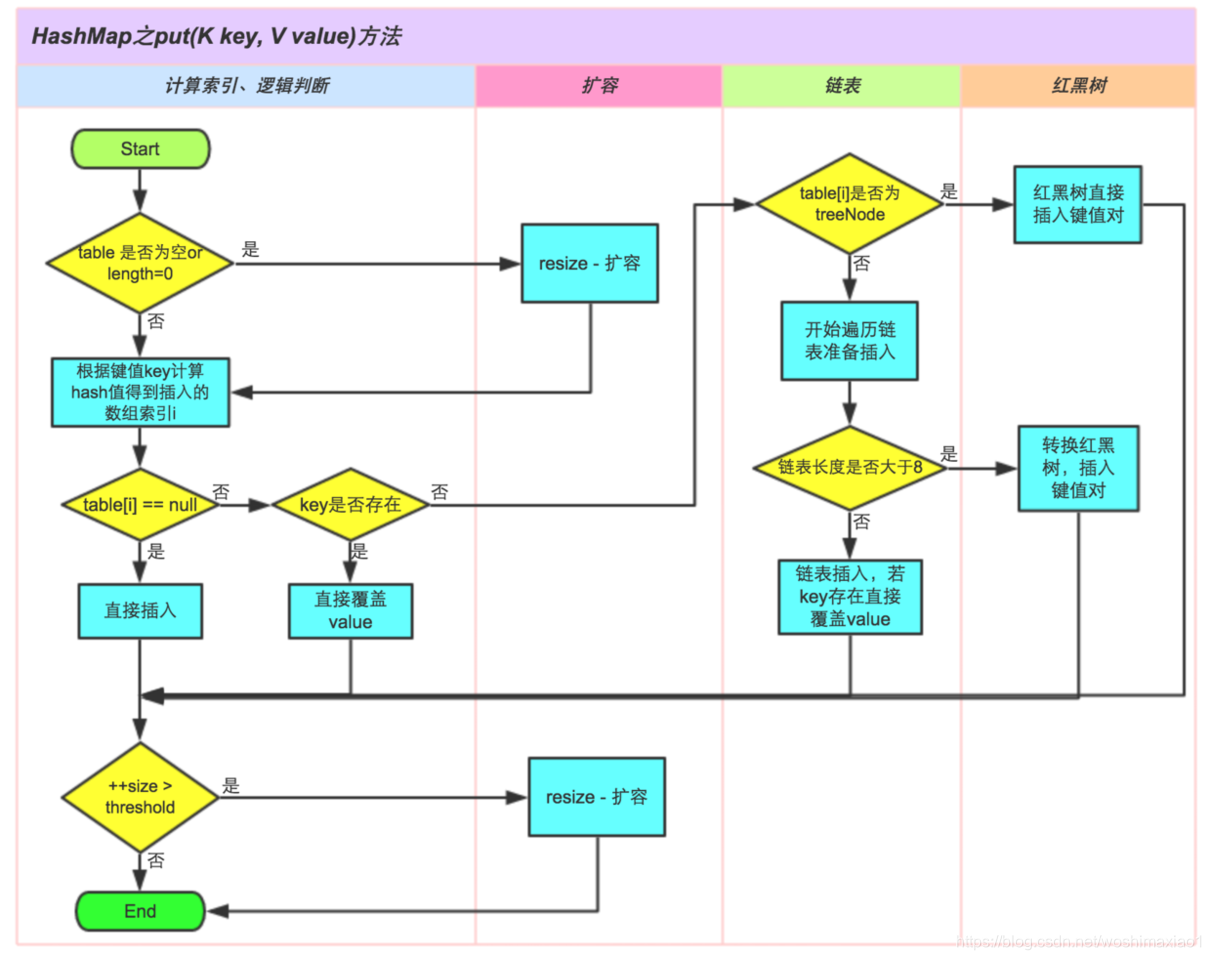
- 底层基于数组+链表+红黑树。(如下图)(当因哈希冲突使得链表深度达到8时,链表就转换为红黑树)
构造方法:

主要方法:

原理以后单独写一篇。可以先看看这两篇,分析得非常详细:(图片来源同)
https://www.jianshu.com/p/ee0de4c99f87
https://blog.csdn.net/woshimaxiao1/article/details/83661464
LinkedHashMap
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
继承HashMap,Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。
特点:
-
维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。图解LinkedHashMap原理
-
不是同步的。解决方法:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
构造方法:(最后一种常用于生成一个与原来顺序相同的映射副本)

样例代码:(源同上)
Map<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("name1", "aaa");
linkedHashMap.put("name2", "bbb");
linkedHashMap.put("name3", "ccc");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
HashTable
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, Serializable
此类(继承了传统的Dictionary类)实现一个哈希表,该哈希表将键映射到相应的值。
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。是线程安全的,能用于多线程环境中。实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
构造方法:

主要方法:

put方法的实现:
1.确定value值不可为null
2.若key已经在table中存在,通过for循环,查找符合条件的key,赋予新的Value 返回 旧值
3.若不存在则进行新增操作:
3.1 修改次数+1,判断HashTable是否需要扩容
3.2 获取tab索引下的Entry 赋给 e
3.3 创建一个HashTableEntry赋给tab指定索引位置
3.4 tab的条目数 +1
源码及分析:https://www.jianshu.com/p/b776e05954f9 、https://blog.csdn.net/ns_code/article/details/36191279
HashTable和HashMap的区别
| 散列表 | 实现方式 | 数据安全 | 数据安全实现方式 | 值是否可为Null |
|---|---|---|---|---|
| HashMap | 数组+单向链表+红黑树 | 不安全 | 无 | 可为Null |
| HashTable | 数组+单向链表 | 安全 | Synchronized | 不可为 Null |
参考自:https://www.cnblogs.com/williamjie/p/9099141.html
1、继承的父类不同。
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
2、线程安全性不同
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。
HashMap线程不安全的原因:
当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的头结点。对链表而言,新加入的节点会从头结点加入。
put操作:现在假如A线程和B线程同时对同一个数组位置调用addEntry,两个线程会同时得到现在的头结点,然后A写入新的头结点之后,B也写入新的头结点,那B的写入操作就会覆盖A的写入操作造成A的写入操作丢失。
*remove操作:当多个线程同时操作同一个数组位置的时候,也都会先取得现在状态下该位置存储的头结点,然后各自去进行计算操作,之后再把结果写会到该数组位置去,其实写回的时候可能其他的线程已经就把这个位置给修改过了,就会覆盖其他线程的修改。
resize操作:当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。
3、是否提供contains方法
HashMap去掉contains方法(底层还会调用),只有containsValue和containsKey。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
4、key和value是否允许null值
HashTable中,key和value都不允许出现null值。(编译可以通过,但运行时会抛出NullPointerException异常)
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
5、hash值不同
HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值。
Hashtable计算hash值,直接用key的hashCode();在求hash值对应的位置索引时,用取模运算。
HashMap重新计算了key的hash值;而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF(将负的hash值转化为正值)后,再对length取模。
6、内部实现使用的数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16。
Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1;而HashMap扩容时,将容量变为原来的2倍。
ConcurrentHashMap
public class ConcurrentHashMap<K,V>
extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable
支持获取的完全并发和更新的所期望可调整并发的哈希表。此类遵守与 Hashtable 相同的功能规范,并且包括对应于 Hashtable 的每个方法的方法版本(所以构造方法和主要方法不再赘述)。继承自AbstractMap类,实现了ConcurrentMap和Serializable接口。
为什么需要ConcurrentHashMap?
HashMap是线程不安全的:get时会形成环状链表,死循环;
HashTable线程安全但代价太大:get/put所有相关操作都是synchronized的,相当于整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
ConcurrentHashMap则在前者基础上采用"分段锁"思想,将map拆分成多个Segment(默认16个)。在多线程环境下,不同线程操作不同的Segment,他们互不影响,这便可实现并发操作。
ConcurrentHashMap由一个Segment[]数组组成,而每个Segment维护着一个HashEntry数组:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
final Segment<K,V>[] segments;
...
}
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
}
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就相当于一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。
ConcurrentHashMap的扩容是Segment中的HashEntry数组扩容。当HashEntry达到某个临界点后,会扩容2为之前的2倍, 原理跟HashMap扩容类似。
get方法无需加锁,由于其中涉及到的共享变量都使用volatile修饰,volatile可以保证内存可见性,所以不会读取到过期数据;Segment中的put方法是要加锁的,不过锁粒度细。
JDK8版本的变动
jdk8版本的ConcurrentHashMap直接抛弃了Segment的设计,采用了较为轻捷的Node + CAS + Synchronized设计,来保证线程安全。
ConcurrentHashMap的大体结构为一个node数组(默认为16,可以自动扩展,扩展速度为0.75),每一个节点挂载一个链表。当链表挂载数据大于8时,链表自动转换成红黑树。此时,node数组中存放的不是TreeNode对象,而是就是TreeBin对象(TreeNode节点的包装对象,可以认为是红黑树对象,代替了TreeNode的根节点)。
这部分参考:https://www.jianshu.com/p/1e1a96075256 、https://blog.csdn.net/helei810304/article/details/79786606
总结
参考了这一篇:https://www.cnblogs.com/skywang12345/p/3308833.html
HashMap
最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为Null(多条会覆盖);允许多条记录的值为 Null。非同步的。
TreeMap
能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
Hashtable
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
LinkedHashMap
保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的。
ConcurrentHashMap
与HashTable的用法和实现很相似,也支持线程的同步,而且采用分段锁的思想,并发性能更佳。
性能比较:

