文章目录
Map概述
- 1、Map和collection没有继承关系
- 2、Map集合以key和value的方式存储数据:键值对
- key和value都是引用数据类型。
- key和value都是存储对象的内存地址。
- key起到主导的地址,value是key的一个附属品。
Map常用方法
| V put(K key,V value) | 向Map集合中添加键值对 |
|---|---|
| V get(Object key) | 通过Key获取value |
| void clear() | 清空Map集合 |
| boolean containsKey(Object key) | 判断Map中是否包含某个Key |
| boolean containsValue(Object value) | 判断Map中是否包含某个value |
| boolean isEmpty() | 判断Map集合中元素个数是否为0 |
| V remove(Object key) | 通过key删除键值对 |
| int size() | 获取Map集合中键值对的个数 |
| Set keySet() | 获取Map集合中所有的key(所有的键是一个set集合) |
| Collection values() | 获取Map集合中所有的value,返回一个Collection |
| Set<Map.Entry<K,V> entrySet> | 将Map集合转换成Set集合遍历key-value |
public class MapTest01 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
//1.向Map中添加key-value
map.put(101,"zhangsan");
map.put(202,"lisi");
map.put(303,"wangwu");
map.put(404,"zhaoliu");
//2.获取添加到Map中的key-value的个数
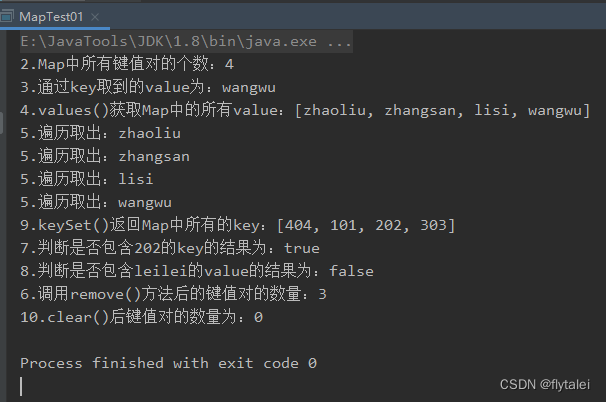
System.out.println("2.Map中所有键值对的个数:"+map.size());
//3.通过key取value
String value = map.get(303);
System.out.println("3.通过key取到的value为:"+value);
//4.获取所有的value
Collection<String> values = map.values();
System.out.println("4.values()获取Map中的所有value:"+values);
//foreach values
for(String str : values){
System.out.println("5.遍历取出:"+str);
}
//5.获取所有的key
Set<Integer> keys = map.keySet();
System.out.println("9.keySet()返回Map中所有的key:"+keys);
//6.判断是否包含某个key和value
System.out.println("7.判断是否包含202的key的结果为:"+map.containsKey(202));
System.out.println("8.判断是否包含zhaoliu的value的结果为:"+map.containsValue("leilei"));
//7.通过key删除key-value
map.remove(404);
System.out.println("6.调用remove()方法后的键值对的数量:"+map.size());
//8.清空Map集合
map.clear();
System.out.println("10.clear()后键值对的数量为:"+map.size());
}
}
put(K key,V value)实现原理
put(K key,V value)实现原理
第一步:先将K,V封装到Node对象当中。
第二步:底层会调用k的hashCode()方法得出hash值,然后通过哈希函数/哈希算法,将hash值转换成数组的下标,
下标位置上如果没有任何元素,就把Node添加到这个位置上了。
如果说下标对应的位置上有链表,此时会拿着k和链表上每一个节点中的k进行equals,
如果所有的equals方法返回都是false,那么这个新节点将被添加到链表的末尾,
如果其中一个equals返回可true,那么这个节点的value将会被覆盖。
get(k)实现原理
v=map.get(k)实现原理
先调用k的hashCode方法得出哈希值,通过哈希算法转换成数组下标。
通过数组下标快速定位到某个位置,如果这个位置上什么也没有,则返回null。
如果这个位置上有单向链表,那么会拿着参数k和单向链表上的每个节点的k进行equals,
如果所有的equals方法返回false,那么get方法返回null,
只要其中有一个节点的k和参数k equals的时候返回value,那么此时这个节点的value就是我们要找的value,get方法最终返回这个要找的value。
为什么哈希表的随机增删和查询效率都很高
为什么哈希表的随机增删和查询效率都很高
增删是在链表上完成。
查询也不需要都扫描,只需要部分扫描
哈希表是数组和链表的结合体,所以没有将数组和链表的单独特性发挥到极致,但是效率已经很高了。
Map遍历元素的方法
1.方法一:keySet()
public class MapTest02Foreach {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
//1.向Map中添加key-value
map.put(101,"zhangsan");
map.put(202,"lisi");
map.put(303,"wangwu");
map.put(404,"zhaoliu");
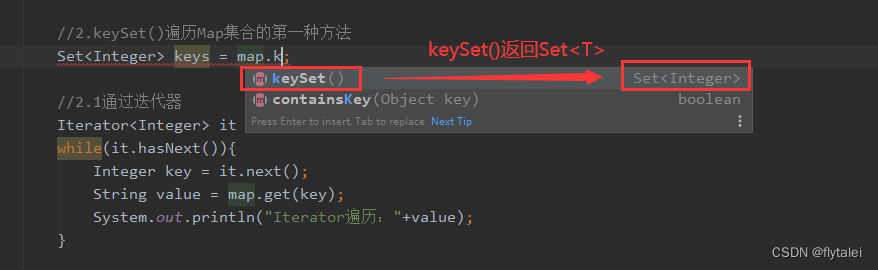
//2.keySet()遍历Map集合的第一种方法
Set<Integer> keys = map.keySet();
//2.1通过迭代器
Iterator<Integer> it = keys.iterator();
while(it.hasNext()){
Integer key = it.next();
String value = map.get(key);
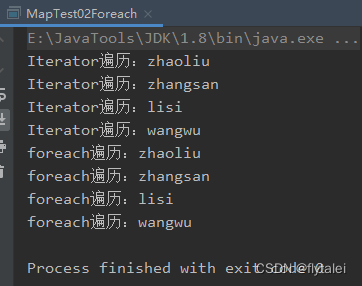
System.out.println("Iterator遍历:"+value);
}
//2.2foreach
for(Integer key : keys){
System.out.println("foreach遍历:"+map.get(key));
}
}
}
2.方法二:entrySet()
public class MapTest02Foreach {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
//1.向Map中添加key-value
map.put(101,"zhangsan");
map.put(202,"lisi");
map.put(303,"wangwu");
map.put(404,"zhaoliu");
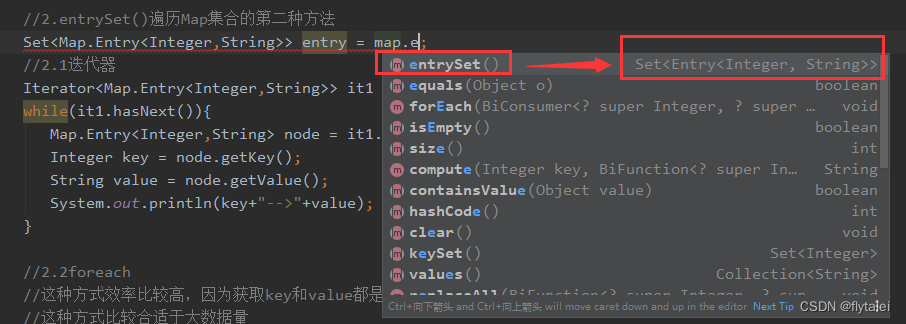
//2.entrySet()遍历Map集合的第二种方法
Set<Map.Entry<Integer,String>> entry = map.entrySet();
//2.1迭代器
Iterator<Map.Entry<Integer,String>> it1 = entry.iterator();
while(it1.hasNext()){
Map.Entry<Integer,String> node = it1.next();
Integer key = node.getKey();
String value = node.getValue();
System.out.println(key+"-->"+value);
}
//2.2foreach
//这种方式效率比较高,因为获取key和value都是直接从node对象中获取的属性值
//这种方式比较合适于大数据量
for(Map.Entry<Integer,String> node1 : entry){
System.out.println(node1);
}
}
}
HashMap
老杜说:哈希表的数据结构像西游记里面的珠珠门帘。横着的是数组,竖着一条一条的是链表,如下图

* HashMap集合:
* 1、HashMap集合底层是哈希表/散列表的数据结构。
* 2、哈希表是一个怎样的数据结构呢?
* 哈希表是一个"数组"和"单向链表"的结合体。哈希表将这个两种数据结构结合在一起,充分发挥它们的各自的优点。
* 数组:在查询方面效率很高,随机增删方面效率很低。
* 单向链表:在随机增删方面效率较高,在查询方面效率很低。
* 3、HashMap集合底层源代码:
* public class HashMap{
* // HashMap底层实际上就是一个数组。(一维数组)
* Node<K,V>[] table;
* //静态内部类HashMap.Node
* static class Node<K,V>{
* final int hash; //哈希值(哈希值是key的hashCode()方法的执行结果。hash值通过哈希函数/算法),可以转换存储成数组的下标。
* final K key; //存储到Map集合中的那个Key
* final V value; //存储到Map集合中的那个value
* Node<K,V> next; //下一个节点的内存地址。
* }
* }
* 哈希表/散列表:一维数组,这个数组中每一个元素是一个单向链表。(数组和链表的结合体)
*/