4 Limit 和 Union的用法
4.1 Limit 的用法
从 select 语句的查询结果中返回其中的一部分记录。如:从所有学生中找出成绩最好的前三个人。
Limit 的基本语法:
- SELECT 列名(集)
FROM 表名
LIMIT [起始行号], 返回行数
注:行号从 0 开始编号
SELECT * FROM table LIMIT 5,10; # 表示返回第 6 行到第 15 行记录,共 10 行记录
# 如果只给定一个参数,它表示返回最大的记录行数目:
# 换句话说,LIMIT n 等价于 LIMIT 0,n。
SELECT * FROM table LIMIT 5; # 5 表示从查询结果中返回 5 条记录,0 到 4 行
等价于
SELECT * FROM table LIMIT 0, 5;
# 当第二个参数为 -1 时,表示返回到表的结尾。
SELECT * FROM 表名 LIMIT 50,-1;
注:现在 limit 的第二个参数不能用 -1 了,以前可以执行,新版本的 mysql 做出了修复,现在的替代方法是第二个参数用一个较大的正数代替。
Limit 的对效率的影响分析:
当数据量很大并且起始行号较小时,使用 limit 能够避免全表扫描而提高查询效率;
当数据量很大量并且起始行号较大时,仅用 limit 来限制提取行数会导致效率低下。
4.1 Union 的用法
把数据结构相同或者类似的两张或多张表格中的信息查询出来并进行合并。
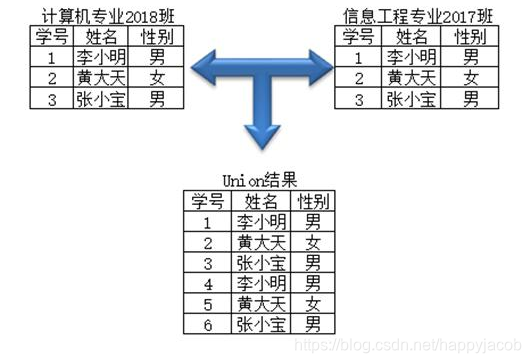
多个 select 语句要能够进行 Union 操作必须满足以下条件:一是每个查询语句的字段个数要相同,二是对应字段的类型要相同或者兼容。UNION 结果集中的列名总是显示 UNION 中第一个 SELECT 子句中的列名
Union语法:
- SELECT 字段,… FROM 表1
UNION [ALL]
SELECT 字段,… FROM 表2
…
Union 仅显示不重复记录,删除重复记录,Union All 显示包括重复记录的所有记录。
Union 字句排序:
- (SELECT 字段 FROM 表1)
UNION ALL
(SELECT 字段 FROM 表2)
ORDER BY 字段 DESC
order by 要放在最后一个 select 后
example:
select * from choose order by score desc;
select * from choose order by score desc limit 3;
5 排序及分组数据
5.1 查询结果排序 — ORDER BY
SELECT 语句的查询结果默认按记录插入到数据表中的顺序来显示。如果希望按指定的一列或多列对查询结果进行排序,使用 ORDER BY 子句 。 语法为:
- SELECT <select_list> FROM table
ORDER BY col_name | expr [ASC | DESC]
- col_name 或 expr 为排序关键字,可以是列名称或表达式,ASC 为升序排列,可省略;DESC 为降序排列。
- 多列排序时,先按第 1 列的值排序,第 1 列的值相同时,才会按第 2 列的值排序.
order by 子句可以指定多个排序依据字段,每个字段单独说明升序降序,默认为升序
example:
select
student.student_id,
student.student_name,
course.Course_name,
course.term,
choose.score
from choose
inner join student on choose.Student_id = student.Student_id
inner join course on course.Course_id = choose.Course_id
order by course.term desc, choose.score asc;
5.2 分组查询 — GROUP BY
分组查询是指按指定的一列或多列对数据进行分组,使用 GROUP BY 分组关键字实现,其语法为:
- SELECT <select_list> FROM table
GROUP BY col_name | expr HAVING conditions
- col_name 或 expr 为分组关键字,可以是列名称,也可以是表达式,HAVING conditions 过滤分组数据!
- 使用多列进行分组时,先按第 1 列分组,在第 1 列值相同的记录中,再根据第 2 列的值进行分组…… 依次类推。
- GROUP BY 通常和 MAX() 、COUNT()
example:
select
department.Department_id as 学院编号,
department.Department_name as 学院名称,
count(teacher.teacher_id) as 教师人数
from department left join teacher
on department.Department_id=teacher.Department_id
group by department.Department_id having count(teacher.teacher_id)>0;
select
department.Department_name as 学院,
classes.Year as 年级,
classes.Class_name as 班级,
count(student.Student_id) as 学生人数
from student
inner join classes on student.Class_id=classes.Class_id
inner join department on student.Department_id=department.Department_id
group by department.Department_name, Classes.Year, classes.Class_name;
5.3 查询结果不重复 — DISTINCT
DISTINCT 关键字用于去除 SELECT 查询结果中的重复值,多个重复值只保留一个。 语法为:
- SELECT DISTINCT fieldname FROM table
example:
select
distinct teacher.Department_id,
department.Department_name
from teacher inner join department
on department.Department_id = teacher.Department_id;
5.4 限制查询结果的数量 — LIMIT
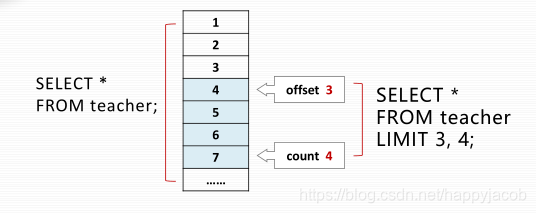
LIMIT 用来限制查询结果的记录数量,可设置 1 个或 2 个参数。语法为:
- SELECT <select_list> FROM table LIMIT [offset, ]count;
- offset:位置偏移量,可选参数, 第 1 条记录的 offset 为 0,第 2 条记录的为 1,…… 依此类推。如果没有指定该参数 , 默认从 0 开始。
- count:返回的记录数量
6 轻松搞定 MySQL 函数
6.1 聚合函数
聚合函数主要是用于对一组值进行计算返回一个汇总值
| 函数名称 | 描述 |
|---|---|
| COUNT() | 统计结果集中记录的行数 |
| SUM() | 对数值型字段的值累加求和 |
| AVG() | 对数值型字段的值求平均值 |
| MAX() | 统计数值型字段值的最大值 |
| MIN() | 统计数值型字段值的最小值 |
example:
select count(*) as 学生人数 from student;
select
b.Course_name,
sum(a.score) as 总成绩,
avg(a.score) as 平均分,
max(a.score) as 最高分,
min(a.score) as 最低分
from choose a, course b
where a.Course_id = b.Course_id and b.Course_name='线性代数';
6.2 字符串函数
| 函数名称 | 描述 |
|---|---|
| CONCAT(S1,S2,…,Sn) | 连接 S1,S2,…,Sn 为一个字符串 |
| LEFT(str, x) | 返回字符串 st 最左边的x个字符 |
| RIGHT(str, x) | 返回字符串 s 最右边的x个字符 |
| SUBSTRING(str, x,y) | 返回从字符串 s x 位置起 y 个字符长度的字串(起始位置从 1 开始) |
example:
select concat('aaa', 'bbb');
select
left('华中科技大学', 4),
right('华中科技大学', 4);
select substring('Mysql数据库', 1, 5);
6.3 数学函数
| 函数名称 | 描述 |
|---|---|
| RAND () | 返回 0~1内的随机值 |
| ROUND(x, y) | 返回参数 x 的四含五入的有y位小数的值 |
| TRUNCATE(x, y) | 返回数字 x 截断为 y 位小数的结果 |
example:
select rand();
select round(rand()*10.0);
select truncate(rand() * 10, 0);
6.4 日期和时间函数
| 函数名称 | 描述 |
|---|---|
| CURDATE() | 返回当前日期,只包含年月日 |
| CURTIME() | 返回当前时间,只包含时分秒 |
| NOW() | 返回当前日期和时间,年月日时分秒都包含 |
| YEAR(date) | 返回日期 date 的年份,即所给的日期是哪一年 |
example:
select curdate();
select curtime();
select now();
select
student_name,
year(now())-year(birthday) as 年龄
from student;
6.5 其他常用函数
| 函数名称 | 描述 |
|---|---|
| DATABASE() | 返回当前数据库名 |
| VERSION() | 返回当前数据库版本 |
| USER() | 返回当前登录用户名 |
example:
select database();
select version();
select user();
7 特殊字符序的实战经验
特殊字符序
| MySQL中的特殊字符序列 | 转义后的字符 |
|---|---|
| \" | 双引号(") |
| \’ | 单引号(‘) |
| \\ | 反斜杠(\) |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \0 | ASCII 0(NUL) |
| \b | 退格符 |
| \_ | _ |
| \% | % |
select 语句中,查询条件 where 子句中可以使用 like 关键字进行“模糊查询”。“模糊查询”存在两个匹配字符 “_” 和 “%”。其中,“_” 可以匹配单个字符, “%”可以匹配任意个数的字符。如果使用 like 关键字查询某个字段是否存在 “_” 或 “%”,那么就需要对 “_” 和 “%” 进行转义。
查询应用实例
example:
# 查询名字中含有字符_的同学
select * from student where student_name like '%\_%';
# 查询名字中含有字符'的同学
select * from student where student_name like '%\'%';
8 子查询
8.1 理解子查询
子查询也称为嵌套查询,是嵌套在外层查询 WHERE 子句中的查询。子查询为主查询返回其所需数据,或者对外查询的查询结果作进一步的限制。

8.2 使用关系运算符和 IN 关键字的子查询
内层查询返回列 col_name 的值,外层查询意义相同的列 col_name 和子查询的返回值做比较。使用关系运算符时,返回值至多一个,使用 IN 时,返回值可以有多个。

example:
# 查询和“周一老师”在同一个学院的教师信息
select * from teacher
where department_id = (select Department_id from teacher where Teacher_Name = "周一老师");
# 查询哪些同学至少有一门课程的成绩在 95 以上
select
student_id,
student_name
from student where student_id in(select student_id from choose where score >= 95);
# 查询所有课程的成绩都在85以上的同学信息
select
student_id,
student_name
from student
where student_id not in (select distinct student_id from choose where score < 85);
8.3 带 SOME、ANY、ALL 的子查询
ANY 和 SOME 同义,在进行比较运算时只要子查询的查询结果有一行能使结果为 True,则结果就为 True;而 ALL 则要求子查询中的所有行都使结果为 True,结果才为 True。

example:
# 查询有成绩大于等于“M20177003”(张三)同学的所有的成绩的同学信息
select
distinct student.student_id,
student.student_name
from student inner join choose on student.student_id = choose.Student_id
where choose.score >= ALL(select choose.score from choose where choose.Student_id = "M20177003");
# 或者
select
distinct student.student_id,
student.student_name
from student inner join choose on student.student_id = choose.Student_id
where choose.score >= (select max(choose.score) from choose where choose.Student_id = "M20177003");
8.4 带 EXISTS 关键字的子查询
EXISTS 用来检查子查询是否有查询结果返回,只要返回一行,EXISTS 的结果即为 True,外查询语句将进行查询;反之结果为 False,此时外层语句将不进行查询

example:
# 查询还没有教师的部门(学院)信息
select *
from department
where department_id not in (select distinct department_id from teacher);
# 或
select * from department
where not exists (select distinct Department_id from teacher where teacher.Department_id = department.Department_id);
8.5 在 CREATE TABLE 语句和数据操作语句中使用子查询
在 CREATE TABLE 命令中,使用 SELECT 查询可以把现有表的结构和数据复制到新表,但不复制索引。

在 INSERT、DELETE 和 UPDATE 语句中使用 SELECT 查询,可实现数据的添加、删除和更新

example:
# 复制表 teacher 的结构
create table newteacher as
select * from teacher limit 0, 0;
# 将 2017 级学生信息生成一个新表
create table student2017 as
select * from student where left(student_id, 5) = 'M2017';
# 将教授信息插到新表 newteacher 中
insert into newteacher
select * from teacher where profesional = "教授";
# 删除没有教师的学院
delete from department
where department_id not in (select distinct department_id from teacher);
# 用数据库 department 中的部门名称更新数据库 newdepartment
update newdepartment set Department_name = (select Department_name from department where Department_id = "401")
where Department_id = "401";

 博客专家
博客专家