谏言:穷则独善其身,达则兼济天下
抓取腾讯招聘信息
# 抓取用户指定的关键词的所有工作岗位 import requests # 导入请求库 def get_jobs( keyword,pageIndex): # 传入工作岗位keyword url='https://careers.tencent.com/tencentcareer/api/post/Query' params={ 'keyword': keyword, 'pageIndex': pageIndex, 'pageSize': 10, 'language': 'zh-cn', 'area': 'cn', } response = requests.get(url=url,params=params)# 请求网页 if response.status_code==200: return response.json() # 返回为json格式 else: print("程序出现错误!!!") keyword=input('请输入你要查询的工作岗位名称: ') get_jobs(keyword,1) count=data['Data']['Count'] # 获取总页数 page_num=int(count/10)+1 job_list=[] for i in range(page_num): print('*****开始下载第'+str(i+1)+'页****') data=get_jobs(keyword,i) jobs=data['Data']['Posts'] job_list.extend(jobs)
请输入你要查询的工作岗位名称: python *****开始下载第1页**** *****开始下载第2页**** *****开始下载第3页**** *****开始下载第4页**** *****开始下载第5页**** *****开始下载第6页**** *****开始下载第7页**** *****开始下载第8页**** *****开始下载第9页**** ....
*****开始下载第92页**** *****开始下载第93页**** *****开始下载第94页**** *****开始下载第95页**** *****开始下载第96页**** *****开始下载第97页**** *****开始下载第98页**** *****开始下载第99页****
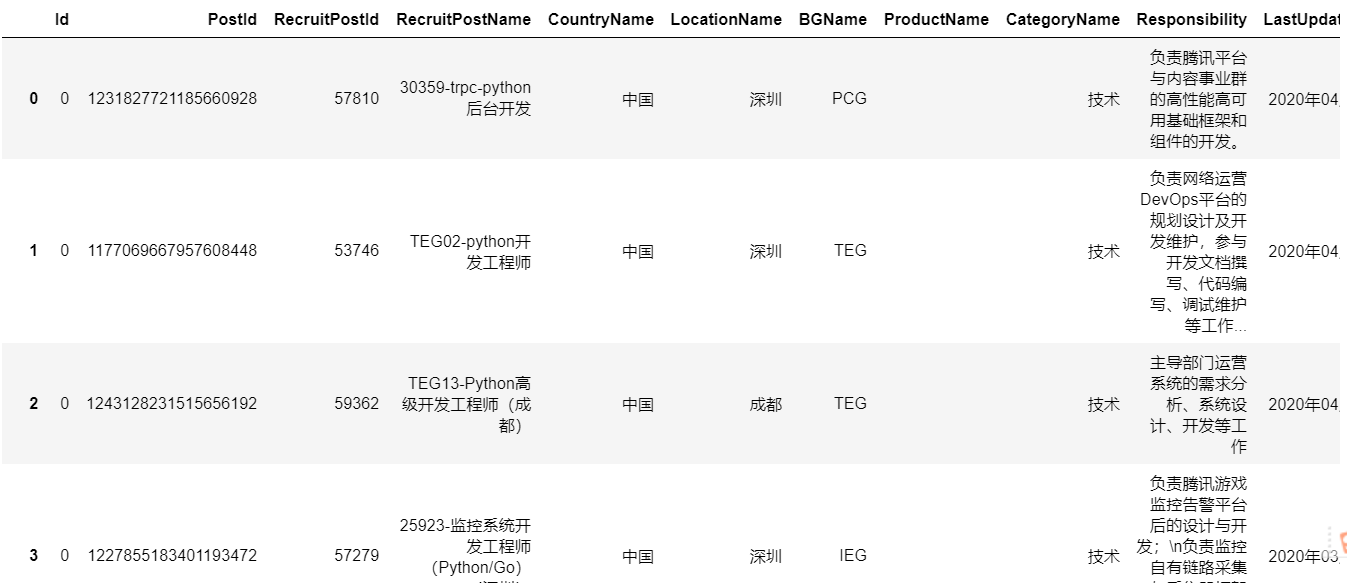
import pandas as pd jobs_df=pd.DataFrame(job_list)
jobs_df
jobs_df.to_csv('tencent.csv',encoding='utf-8-sig') # 存于tencent.csv文件中