Intro
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells. – Wikipedia
K-means Clustering 就是把 个 sample 迭代划分为 个 cluster, 保证
- 不同 cluster 质心之间距离差足够大
- 同一 cluster 内 samples 的距离差足够小
Algo
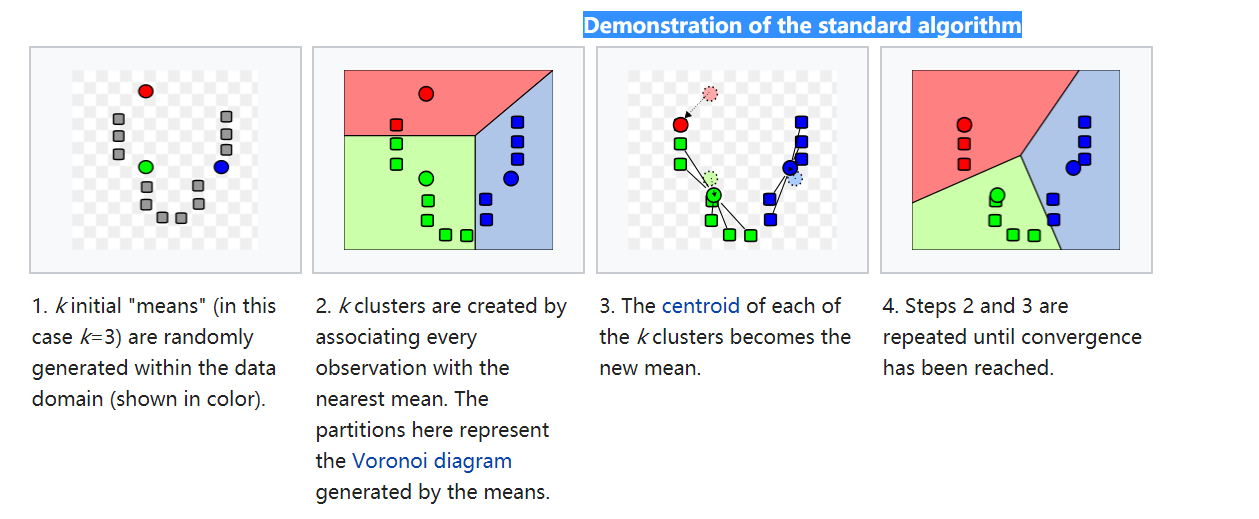
- Step 1 : 随机初始化质心 :随机选择 个 sample 作为质心 , 特征空间被划分为 个 voronoi 子空间, 个 cluster
- Step 2 :给每个 sample 分配所属的cluster: sample 从属与距离最近的质心所划分的cluster
- Step 3:所有 sample 划分完成后,重新计算每个 cluster 的质心
- Step 4: 重复 Step 2, Step 3, 直到达至最大迭代次数或两次迭代的差小于阈值,则停止迭代,输出结果。
Ref
- k-means clustering – Wikipedia
- K-means算法及C语言实现:总结的不错
- OpenCV中的K-means聚类: Python 版本,带 plt 直方图过程
- K-means 算法 : 几个图表不错
- K-Means聚类算法原理 : 原理总结很到位,还有几个 K-means 拓展也讲到了
- 深入理解K-Means聚类算法 : 嗯,讲解的很深入了
- K-means聚类算法 : 对应的是 Andrew Ng 的课件,提出了 EM思想