婴幼儿哭声和音视频特征融合学习笔记
前言
在整理完数据集之后,开始学习论文。国内在这里我挑选了四篇国内的婴幼儿哭声论文,其中有一篇是期刊论文。三篇是硕士论文。此外我还挑选了8篇音视频融合论文。他们大都用在自然语言处理中。他们当中有两篇是期刊论文。剩下的六片都是硕士论文。
-
王群. 面向监控场景的婴儿哭声识别[D]. 中国科学院大学 (中国科学院深圳先进技术研究院), 2019.
-
谢湘, 张立强, 王晶. 残差网络在婴幼儿哭声识别中的应用[J]. 电子与信息学报, 2019, 41(1): 233-239.
-
郑慧贞. 基于 LSTM 网络和 GMM 的语音检测研究[D]. 山东师范大学, 2019.
-
陈燕斌. 基于机器学习的婴儿语音检测算法研究[D].电子科技大学,2019.
-
毛小旺. 基于机器学习的哭声检测系统研究与开发[D]. 南京邮电大学, 2018.
-
陈坤. 基于多模态融合的情感识别研究[D]. 北京邮电大学, 2019.
-
张戈. 多模态连续维度情感识别研究[D].西安电子科技大学,2019.
-
张园园. 基于深度学习的多模态情感识别方法研究[D]. 中国科学技术大学, 2019.
-
徐战苍. 基于视听通道融合的多媒体暴力片段检测方法研究[D].哈尔滨工业大学,2014.
-
邵晨智. 基于音视频特征融合的暴力镜头识别方法研究[D]. 哈尔滨工业大学, 2019.
-
宋冠军,张树东,卫飞高.音视频双模态情感识别融合框架研究[J/OL].计算机工程与应用:1-9[2020-02-18].http://kns.cnki.net/kcms/detail/11.2127.tp.20190311.1538.010.html.
残差网络在婴幼儿哭声识别中的应用
这篇论文是发表在电子信息学报,电子信息学报应该是比较难发的国内期刊。这篇论文的主要工作是使用了语义普结合残差网络进行婴儿哭声的识别。在这篇论文,他通过使用Github上的数据集。比较支持向量机卷积神经网络。滤波器,听觉谱残差网络和语谱图残差网络识别准确率。
相关工作: 作者引用了十篇论文。这10篇论文,有婴儿哭声声学分析,共轭梯度算法和神经网络提取梅尔平率倒谱系数。和线性预测到浦西数特征进行比较。提取KNN和短时能量基因频率在Knn分类算,剩下的论文是通过c嗯嗯和SVM进行比较,特征选取的是于谱图。最后作者引用了音频分析中的一些论文共三篇。使用听觉滤波器变化域特征和听觉谱。 结尾又说了,所以嗯嗯,模型的一些缺点以及残差网络可以更好地识别。
分析与建模: 首先对婴儿的哭声进行了分析。这一点我还看不懂。需要重点掌握一下。这里作者对常用的声学特征进行了分析。注意这里的声学特征指的是常用的一些信息参数,这些参数是可以直接从声学图上看出来的,在提取这些参数的时候,我们是使用短时傅里叶变换和听觉滤波模型两种时域分解方法。在这两种方法上可以进行扩展,从而得到一些其他的方法,但是其时域分解基本性质还是基于这两个方法。最后分析比较了建模方法,这里面就没有什么重点了都是一些模型的基本概念。
实验与分析: 首先介绍了实验的数据集,一共是1100条正样本数据。1100条反样本数据。规定了评价指标,这个评价指标相比较准确率单一评价更具有说服性。接下来就开始做实验,作者首先使用了SVM。卷积神经网络。随后又验证了卷积神经网络随着网络层数的增加,识别率在逐步降低。因此引用出来残差网络残差网络的架构,我就不在这里说了。作者直接使用了残差15残差19残差27,并且把它们分别放入语谱图特征和听觉普特征。得出了接近于满分的一个评价指标。最后分析的数据内容。对评价指标和实时性模型复杂度分别进行了放弃。并采用了模型复杂都相对中等的resonant19,
今后工作: 对哭声病理进行分析。
参考文献: 前面几篇是相关工作的论文。需要关注国外的这几个。还有就是作者使用的声学特征提取方法相关论文,也就是参考文献八九十。参考19文献时就是预处理的,重点看
论文疑问点:
- 音频识别的基本概念不熟悉:对于普图和滤波器听觉普。Mfcc,短时能量。傅里叶变换等概念均不熟悉。或者可以说,只知道单一的东西,但是无法把它们结合起来。所以要总结一下他们的关系。
- Fe评价指标不知道是什么?需要查看一下参考文献17。
- 相关工作引用的论文自己看了大部分了。但是放假后没怎么看,忘记了。需要重新看一下这篇论文引用的英文文献。
- 19年婴儿哭声相关的论文其实挺多的。大致有三篇,需要对比学习他们的异同点。
补充学习的知识:
- 语音信号处理流程。事先将语音化进行预处理,再进行端点检测,最后进行语音去噪,然后才放入业务中进行相应的的操作。
- 语音信号的特点:收到和声带是人的发声器官,从生带到嘴唇的呼吸通道我们称之为声道。圣诞是声音的激励,会形成浊音的激励脉冲。也被称为基因频率,这个频率会在60到450赫兹,根据声带的震动与否语音就会分为浊音和清音。I really的语音信号于其他摄影相比,因为发声器官的原因如升到升到不能发成图片,所以在相对短的时间内能发出的声音是时不。变信号。基于这个原因,我们在大部分语音处理中会把语音信号进行风筝处理。哎,这个真是十毫秒到30毫秒,这样就会把非线性确实变得语音信号转换成短时平稳的风筝信号。
- 清音和浊音在时域和频域都有一定的区别:浊音。具有周期性,并且在频率上具有共振峰。且存在于中低频段。爱奇艺在语音处理过程中,由于声带不发声震动,所以并没有周期性,而且能量较低,所以轻音和白噪声很像,并且在时域和频域上特征不明显。
- 声音的模拟信号转化为数字信号:要经过预滤波采样,量化和编码等几个部分。据滤波是为了防止呃信号的一个。突变。在这里会设置,评论发下限频率,这样就会去除噪音,交流电的噪音等信号。采样和量化就是对原始信号的模拟信号在时间轴上按照时间间隔相等的方式进行抽样取值。编码的摸底设防为了防止数据,编码的摸底设防为了防止数据在传输过程中会出错,并且会减少一定的冗余信息。
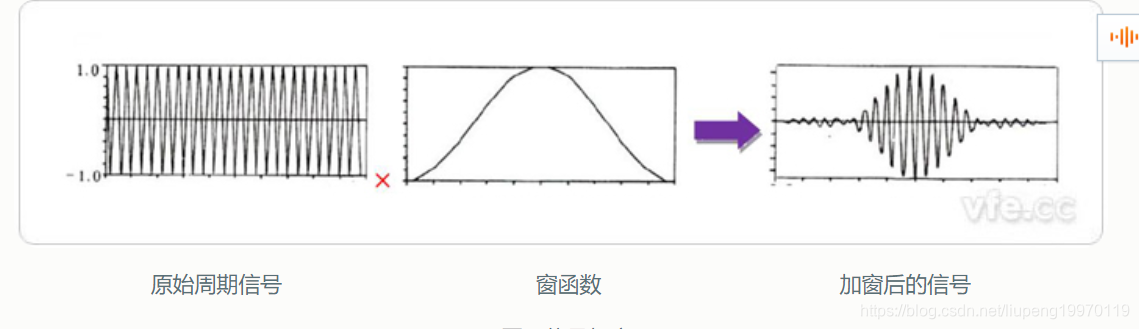
- 语音信号的预处理:预处理包括语音信号的预加重,风筝加窗这一环节对后续的算法性能影响较大。预加重是指在传输过程中高频信号会衰减比较大。而预加重操作就是为了每一弥补高频部分的衰减。语音的纷争是通过加窗实现的。为什么要分帧是因为要研究平稳的信号。常用的窗有矩形窗,海明窗,汉宁窗。不同窗函数的时域频率特性都存在愈加重。在中间的时候需要注意。如果我们只是按一节一节的方式去方舟的话,就会导致前后语音真的特征参数变化很大,没有连贯性,对后面的处理将会产生很大的影响,这时候我们需要采用交底加窗风筝方法对信号进行风筝。这时候需要确定。真的移动大小和帧的移动长度。
6.时域和频域的区别再讲波图当中x它的单位是th:。正弦波是平玉中唯一存在的波。

7. 语音信号特征:短时能量是指每一帧所有信号的能量之和。短时过零率是指一个信号通过时间做标准的次数。!梅尔频率倒谱系数可以很好的模拟人耳对声音能量的感知。
