相亲旅游必备——决策树
决策树优缺点
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。既能用于分类,也能用于回归
- 缺点:可能会产生过度匹配问题
决策树的原理
返回顶部
如果以前没有接触过决策树,完全不用担心,它的概念非常简单。即使不知道它也可以通过简单的图形了解其工作原理。
相亲决策树
决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑:

id3算法
返回顶部
划分数据集的大原则是:将无序的数据变得更加有序。
我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。组织杂乱无章数据的一种方法就是使用信息论度量信息,信息论是量化处理信息的分支科学。我们可以在划分数据之前使用信息论量化度量信息的内容。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
集合信息的度量方式称为香农熵或者简称为熵,这个名字来源于信息论之父克劳德•香农。
entropy
熵定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类的事务可能划分在多个分类之中,则符号x的信息定义为:
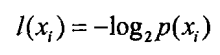
其中p(x)是选择该分类的概率
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:

其中n是分类的数目。
在决策树当中,设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
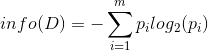
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
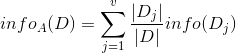
而信息增益即为两者的差值:
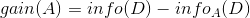
旅游决策树numpy计算
返回顶部
熵增益计算练习
根据天气(晴\阴\雨、气温、湿度、风)预测是否出去玩

是否出去玩的信息熵
import numpy as np
h_play = -((9. / 14) * np.log2(9. / 14) + (5. / 14) * np.log2(5. / 14))
round(h_play, 3)
0.94
天气的信息增益
h_sunny = -((2. / 5) * np.log2(2. / 5) + (3. / 5) * np.log2(3. / 5)) * (5. / 14)
h_overcast = -((1.) * np.log2(1.)) * (4. / 14)
h_rain = -((3. / 5) * np.log2(3. / 5) + (2. / 5) * np.log2(2. / 5)) * (5. / 14)
h_outlook = h_sunny + h_overcast + h_rain
round(h_outlook, 3)
0.694
r_outlook = round(h_play - h_outlook, 3)
r_outlook
0.247
气温的信息增益
h_hot = -((2. / 4) * np.log2(2. / 4) + (2. / 4) * np.log2(2. / 4)) * (4. / 14)
h_mild = -((4. / 6) * np.log2(4. / 6) + (2. / 6) * np.log2(2. / 6)) * (6. / 14)
h_cool = -((3. / 4) * np.log2(3. / 4) + (1. / 4) * np.log2(1. / 4)) * (4. / 14)
h_temp = h_hot + h_mild + h_cool
round(h_temp, 3)
0.911
r_temp = round(h_play - h_temp, 3)
r_temp
0.029
湿度的信息增益
h_high = -((3. / 7) * np.log2(3. / 7) + (4. / 7) * np.log2(4. / 7)) * (7. / 14)
h_norm = -((6. / 7) * np.log2(6. / 7) + (1. / 7) * np.log2(1. / 7)) * (7. / 14)
h_hum = h_high + h_norm
round(h_hum, 3)
0.788
r_hum = round(h_play - h_hum, 3)
r_hum
0.152
刮风的信息增益
h_wtrue = -((3. / 6) * np.log2(3. / 6) + (3. / 6) * np.log2(3. / 6)) * (6. / 14)
h_wfalse = -((6. / 8) * np.log2(6. / 8) + (2. / 8) * np.log2(2. / 8)) * (8. / 14)
h_wind = h_wtrue + h_wfalse
round(h_wind, 3)
0.892
r_wind = round(h_play - h_wind, 3)
r_wind
0.048
信息增益排名: r_outlook(0.247) > r_hum(0.152) > r_wind(0.048) > r_temp(0.029)
晴天的前提下,其它因素的信息增益
h_sunny_sunny = -((2. / 5) * np.log2(2. / 5) + (3. / 5) * np.log2(3. / 5))
round(h_sunny_sunny, 3)
0.971
晴天的前提下,气温的信息增益
h_hot_sunny = -((2. / 2) * np.log2(2. / 2)) * (2. / 5)
h_mild_sunny = -((1. / 2) * np.log2(1. / 2) + (1. / 2) * np.log2(1. / 2)) * (2. / 5)
h_cool_sunny = -((1. / 1) * np.log2(1. / 1)) * (1. / 5)
h_temp_sunny = h_hot_sunny + h_mild_sunny + h_cool_sunny
round(h_temp_sunny, 3)
0.4
r_temp_sunny = h_sunny_sunny - h_temp_sunny
round(r_temp_sunny, 3)
0.571
晴天的前提下,湿度的信息增益
h_high_sunny = -((3. / 3) * np.log2(3. / 3)) * (3. / 5)
h_norm_sunny = -((2. / 2) * np.log2(2. / 2)) * (2. / 5)
h_hum_sunny = h_high_sunny + h_norm_sunny
round(h_hum_sunny, 3)
-0.0
r_hum_sunny = h_sunny_sunny - h_hum_sunny
round(r_hum_sunny, 3)
0.971
晴天的前提下,刮风的信息增益
h_wtrue_sunny = -((1. / 2) * np.log2(1. / 2) + (1. / 2) * np.log2(1. / 2)) * (2. / 5)
h_wfalse_sunny = -((1. / 3) * np.log2(1. / 3) + (2. / 3) * np.log2(2. / 3)) * (3. / 5)
h_wind_sunny = h_wtrue_sunny + h_wfalse_sunny
round(h_wind_sunny, 3)
0.951
r_wind_sunny = h_sunny_sunny - h_wind_sunny
round(r_wind_sunny, 3)
0.02
晴天时,其它因素信息增益排名:
r_hum_sunny(0.971) > r_temp_sunny(0.571) > r_wind_sunny(0.02)
机器学习实现示例
返回顶部
根据天气预测是否出去玩

导入数据
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
df = pd.read_csv('./dtree.csv')
df
| Outlook | Temperature | Humidity | Windy | Play | |
|---|---|---|---|---|---|
| 0 | sunny | 85 | 85 | False | no |
| 1 | sunny | 80 | 90 | True | no |
| 2 | overcast | 83 | 86 | False | yes |
| 3 | rainy | 70 | 96 | False | yes |
| 4 | rainy | 68 | 80 | False | yes |
| 5 | rainy | 65 | 70 | True | no |
| 6 | overcast | 64 | 65 | True | yes |
| 7 | sunny | 72 | 95 | False | no |
| 8 | sunny | 69 | 70 | False | yes |
| 9 | rainy | 75 | 80 | False | yes |
| 10 | sunny | 75 | 70 | True | yes |
| 11 | overcast | 72 | 90 | True | yes |
| 12 | overcast | 81 | 75 | False | yes |
| 13 | rainy | 71 | 91 | True | no |
df.columns
Index(['Outlook', 'Temperature', 'Humidity', 'Windy', 'Play'], dtype='object')
data = df.loc[:, ['Outlook', 'Temperature', 'Humidity', 'Windy']].to_dict(orient = 'record')
target = df.loc[:, ['Play']].to_dict(orient = 'record')
训练数据向量化
dt_vect_data = DictVectorizer(sparse = False)
vect_data = dt_vect_data.fit_transform(data)
vect_data
array([[85., 0., 0., 1., 85., 0.],
[90., 0., 0., 1., 80., 1.],
[86., 1., 0., 0., 83., 0.],
[96., 0., 1., 0., 70., 0.],
[80., 0., 1., 0., 68., 0.],
[70., 0., 1., 0., 65., 1.],
[65., 1., 0., 0., 64., 1.],
[95., 0., 0., 1., 72., 0.],
[70., 0., 0., 1., 69., 0.],
[80., 0., 1., 0., 75., 0.],
[70., 0., 0., 1., 75., 1.],
[90., 1., 0., 0., 72., 1.],
[75., 1., 0., 0., 81., 0.],
[91., 0., 1., 0., 71., 1.]])
数据向量化: 天气分成了3个特征
标记数据向量化
dt_vect_target = DictVectorizer(sparse = False)
vect_target = dt_vect_target.fit_transform(target)
dt_tree = DecisionTreeClassifier()
dt_tree.fit(vect_data, vect_target)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
print('属性重要性', dt_tree.feature_importances_)
属性重要性 [0.28 0.22222222 0. 0. 0.49777778 0. ]
测试数据向量化
new_data = {'Outlook': 'sunny', 'Temperature': 60, 'Humidity': 90, 'Windy': True}
vect_new_data = dt_vect_data.transform(new_data)
vect_new_data
array([[90., 0., 0., 1., 60., 1.]])
预测
dt_vect_target.inverse_transform(dt_tree.predict(vect_new_data))
[{'Play=yes': 1.0}]
总结
决策树真是相亲、旅游必备。
欢迎关注,敬请点赞!
返回顶部
