前两回我们都在处理一些跟顺序有关的问题,第一回我们解决查找问题,就要把由无序元素组成的集合变为有序的集合然后进行查找。第二回我们解决路径问题,节点的前后序关系成为我们解决问题的重要依据。这回我们说一些跟顺序关系不大的问题,摆脱一些枯燥的代码实现以及数学符号,我们聊一聊算法的思想能为我们在生活中遇到的实际问题提供一些什么样的解决思路。
动态规划
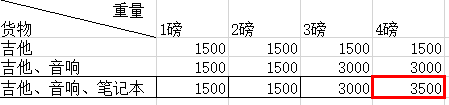
生活中遇到的问题往往不是能一步操作就能完成,你需要为解决这个问题的每一步做决策,去求得完成这个问题的最优解。举个例子,你有一个能容纳4磅的背包。背包能装的货物分别是,吉他重为1磅,价值1500;笔记本重为3磅,价值为2000;音响为4磅,价值为3000,问题是往背包里放置能容纳的最大价值。当我遇到这个问题的时候,很自然的就以穷举法去解决这个问题,但是当背包变大,货物变多,这种方法就显得力不从心了。
我们再重新审视这个问题,试图抓住它的本质,其实是要求当前货物集合的一个子集,这个子集内部货物的重量之和不大于4,而货物的价值之和最高。这个问题是能够分解成相互独立的子问题的,下面的列表就是把集合分解,把背包分解,一步步得到可靠的结论。列表值填写的逻辑是判断表格上一行同一列的值。以及包含新的货物之后,加上剩余空间最大价值的值(由以做出的表格值得出),两者取大值。是不是似曾相识?对,跟上一回Dijkstra算法有异曲同工之妙!
最长公共子序列
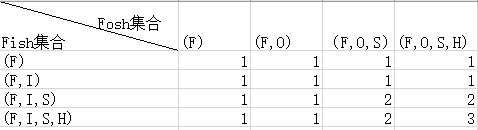
Git每次上传代码的时候,他都会帮你标志出你这次的修改跟仓库中的代码差异,这个功能作为提交之前最后代码检查很是有用,毕竟把你修改和你修改的理由直观的摆到你的面前,能够最大限度的帮你理出这次修改的正确与否以及是否有意义。Git实现这个功能,就是基于动态规划,找到了两个问题件的最长公共子序列,把其余的部分摘出来给你看。所谓最长公共子序列,举个例子,“Fish”与Fosh“之间的最长公共子序列为“fsh”,为三个字母。
要解决任意单词之间最长公共子序列的问题并不简单,因为最长的公共子序列可能在两个字符串任意位置开始不连续的重合。于是我们又要开始重新审视这个问题,问问自己,这个问题可以转化为不不相干的问题来解决吗,答案是肯定的,就上个例子而言,我们可以拆分成由“Fish”不同长度的字符串(诸如“F”,“Fi”,“Fis”,“Fish”)与“Fosh”不同长度的字符串最长公共子序列的问题,一步一步逼近问题。就有下面一个4*4的表格。表格中的每个数字都是两个当前字符串的最长公共子序列。每个单元格的求值方法也很简单(你可以从左往右一行行填写结果):1.如果当前单元格对应两个集合分别与左上角单元格(C[i-1][j-1])两个集合做差为同一个字符,则将当前的值取左上角单元格值加一。如果字符不一致,则取其上部单元格或者左部单元格中的最大值(集合分别少一个元素的最长公共子序列中的最大值)
K最近邻算法
你的Siri是否也是你的“soulmate”?,为什么你的手机助手总会推荐出你的心头好?这背后使用的就是K最近邻算法,道理也很简单,计算机将不同的用户分类,比如张三听的歌曲中,有百分之80是rap,百分之20是电音,李四听的歌曲中,有百分之70是电音,百分之30是rap,王五有百分之90听的是rap,百分之10是电音,那么我们就可以认为张三是王五的邻居,当王五把某个歌曲标记为喜欢的时候,系统就可以将这个歌曲推送给张三。在这个例子中,我们需要给不同的用户推荐其可能喜欢的歌曲,于是针对每个用户,我们提取合适的特征(对不同类型音乐的喜爱程度),特征可能是很多项,然后根据特征计算距离:可以使用毕达哥斯拉公式,来判断邻居,从而根据某个用户的邻居的行为来预测某个用户的行为。所以K最近邻算法做两件事:
- 分类:具有不同特征的元素进行编组
- 回归:预测结果。
机器学习的过程就是通过大量的样本数据提取特征,这个过程也称之为训练,这样机器当遇到新的样本,就能通过之前提取过的特征数据区分类,去指导下一步的动作。
