1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
1)随着模型训练的进行,模型的复杂度会增加,此时模型在训练数据集上的训练误差会逐渐减小,但是在模型的复杂度达到一定程度时,模型在验证集上的误差反而随着模型的复杂度增加而增大。此时便发生了过拟合,即模型的复杂度升高,为了防止过拟合,我们需要用到一些方法,如:early stopping、数据增强、正则化、Dropout等对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
2)正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
2.用logiftic回归来进行实践操作,数据不限。
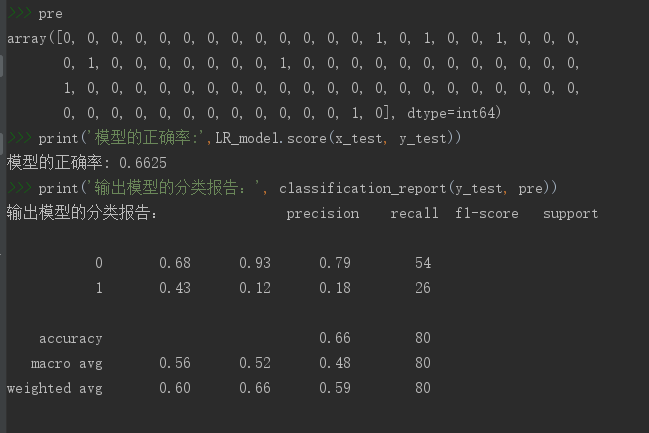
#案列:使用逻辑回归算法预测研究生入学考试是否会被录取 import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report #(1)数据读取与预处理 data = pd.read_csv('./data/LogisticRegression.csv') x = data.iloc[:, 1:] y = data.iloc[:, 0] x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=5) #(2)构建模型 LR_model = LogisticRegression() #(3)训练模型 LR_model.fit(x_train, y_train) #(4)预测模型 pre = LR_model.predict(x_test) print('模型的正确率:',LR_model.score(x_test, y_test)) print('输出模型的分类报告:', classification_report(y_test, pre))