在爬虫实践当中,如果我们爬取的页面的编写没有做好板块的区分,或者我们选取的标签不合适,最终我们获得的结果会多提取到出一些奇怪的东西。
当使用用request获取的网页源代码里没有我们想要的数据时,需要重新思考。
一、认识Network
在网页空白处,点击右键-检查,第一个是Elements,往右看就能找到Network。
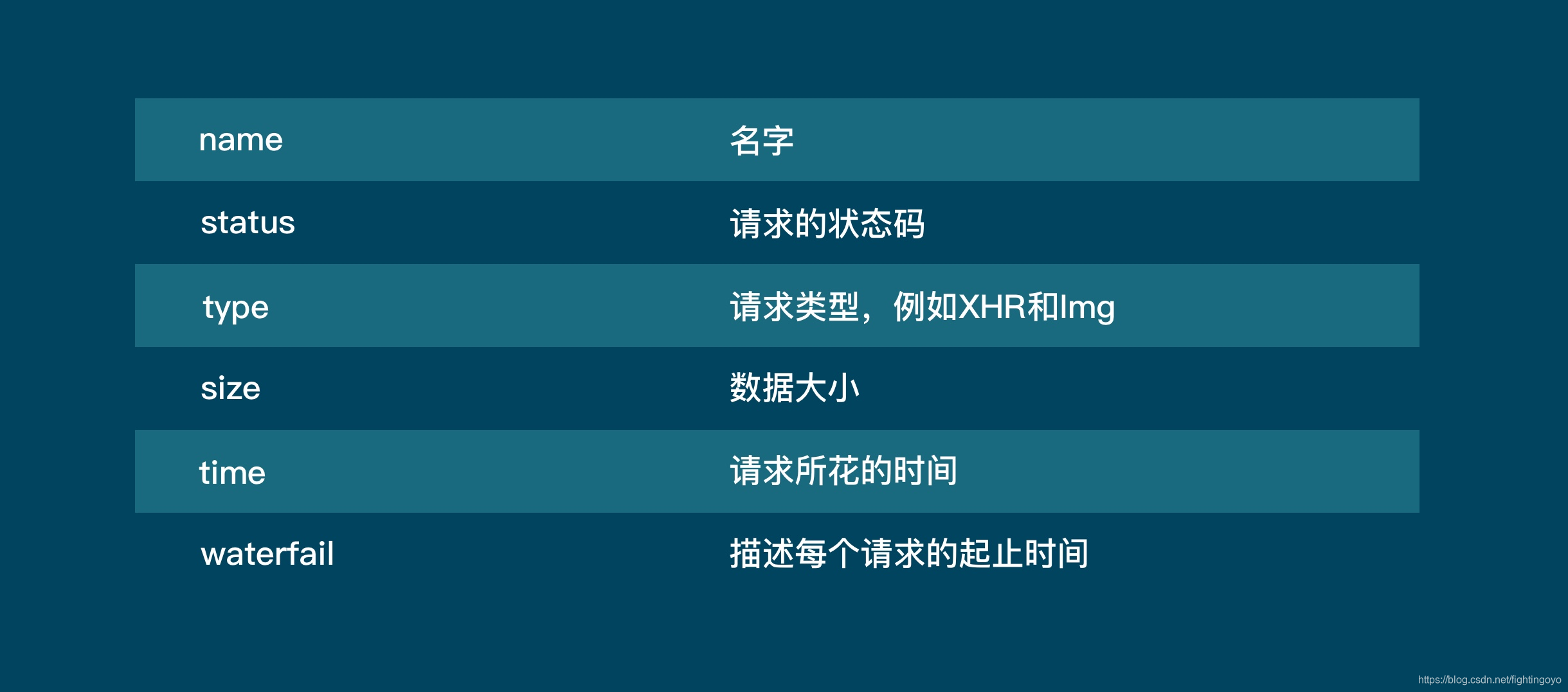
- Network的功能是:记录在当前页面上发生的所有请求。
现在看上去好像空空如也的样子,这是因为Network记录的是实时网络请求。现在网页都已经加载完成,所以不会有东西。
刷新一下页面,浏览器会重新访问网络,这样就会有记录。
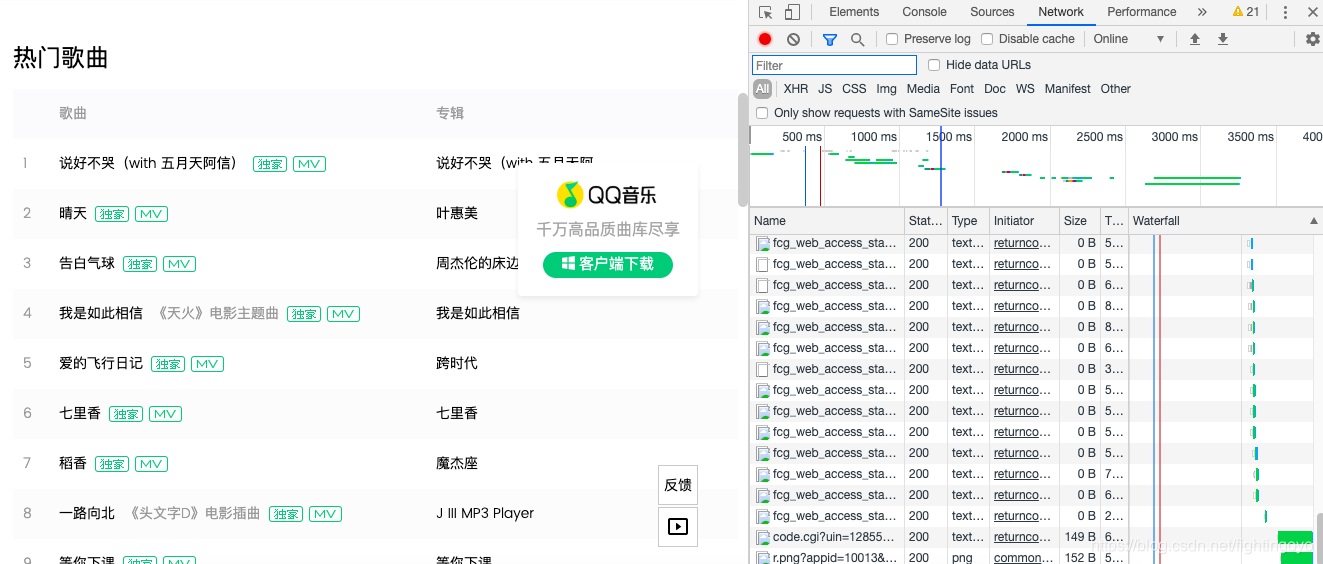
这正是浏览器工作的原理:它总是在向服务器发起请求。当这些请求完成,服务器就会返回我们在Elements中看到的网页源代码。 - 当我们使用requests.get(url)时,只是获取了请求中的第一个,当这个请求中不包含我们需要的代码时,那么,就需要在其他请求中查找。
- 为什么我们之前体验过的开课吧食堂和豆瓣都能够直接爬取我们需要的信息呢?
- 这些网页直接把所有的关键信息都放在第1个请求里,我们用requests和BeautifulSoup就能解决它们。
二、如何使用Network
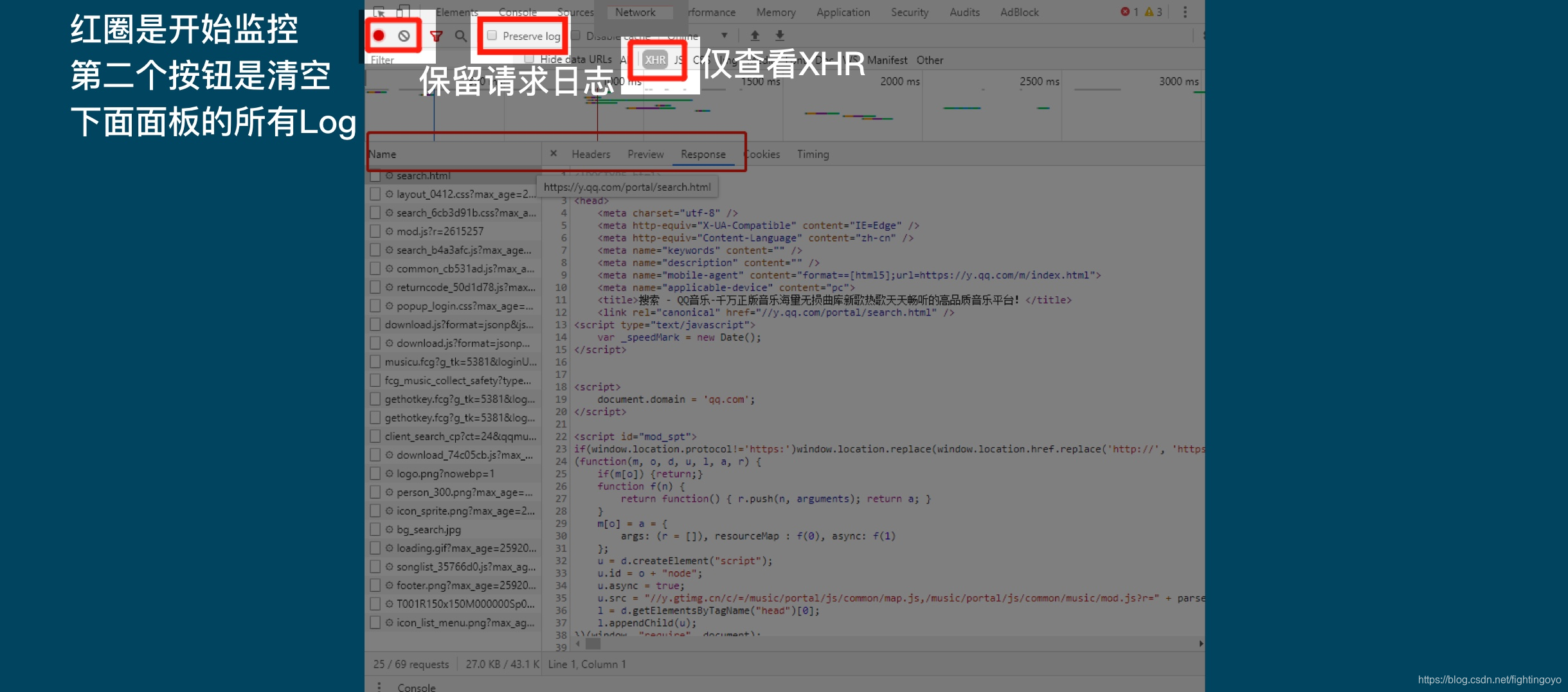
- 第1行的左侧,红色的圆钮是启用Network监控(一般浏览器默认是打开的,用高亮显示),灰色圆圈是清空面板上的信息。
- 右侧勾选框Preserve log,它的作用是“保留请求日志”。如果不点击这个,当发生页面跳转的时候,记录就会被清空。所以,我们在爬取一些会发生跳转的网页时,会点亮它。
- 第3行,是对请求进行分类查看。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR)/Doc(Document,第1个请求一般在这里,有时候也会看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。
- JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识。

- 图中我们还可以看到时间轴:记录什么时间,有哪些请求。而下一行,就是各个请求。
三、什么是XHR
我们平时使用浏览器上网的时候,经常有这样的情况:我们观察到浏览器的地址栏里面的网址并没有发生变化,但是网页却不断有新增的内容出现。
- 这个是Ajax技术。应用这种技术,好处是显而易见的——更新网页内容,而不用重新加载整个网页,又省流量又省时间。
- 这种技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现服务器和浏览器之间传输数据。
XHR和Fetch并没有本质区别,只是Fetch出现得比XHR更晚一些,所以对一些开发人员来说会更好用,但作用都是一样的。
XHR怎么请求
我们在QQ音乐搜索”周杰伦“,我们想要找到周杰伦的歌曲列表,但在第一个请求中并没有找到我们要找的数据。
我们查看其他的请求,可以在xhr中搜索其中一首歌的歌曲名称,找到对应的请求:找到了client_search的请求。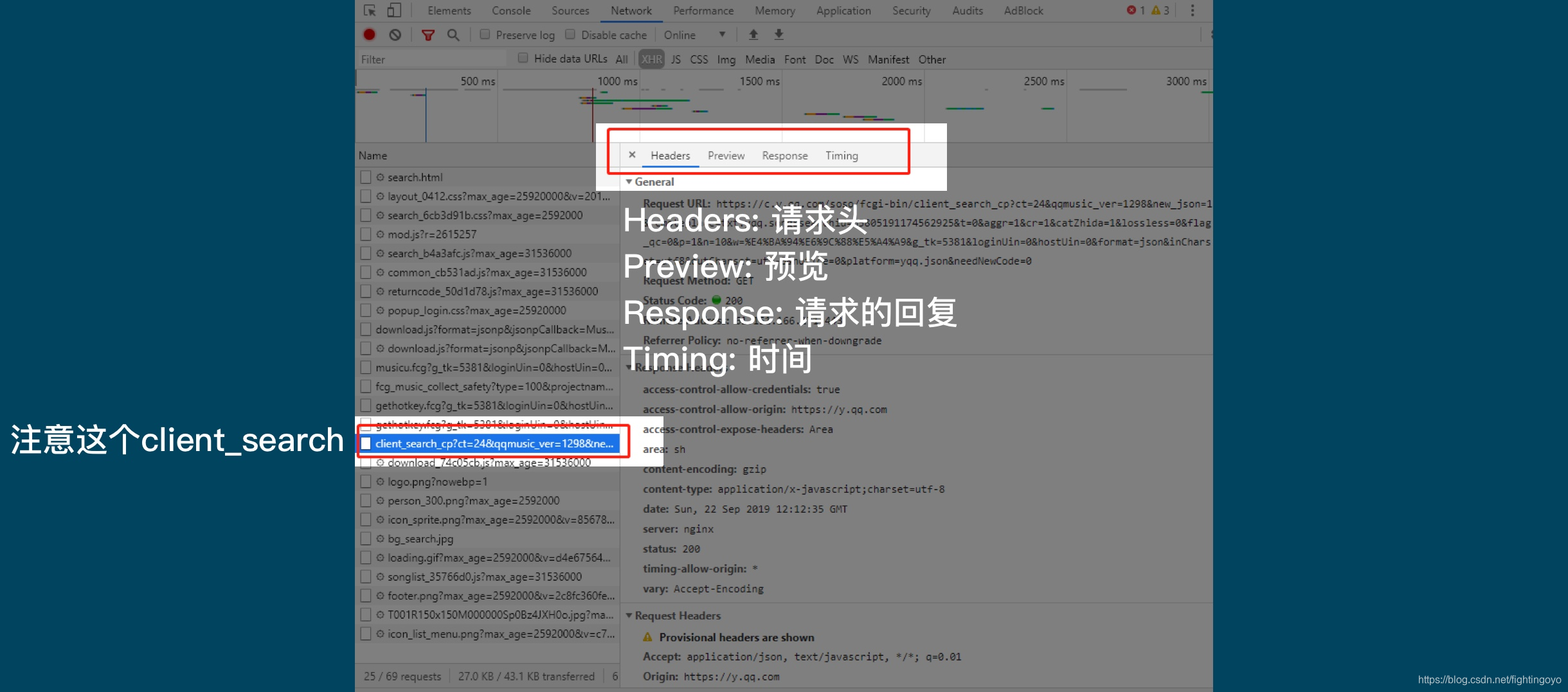
- 红框里面的内容,从左往右分别是:Headers:标头(请求信息)、Preview:预览、Response:原始信息、Timing:时间。
- 点击Preview,里面发现我们想要的信息:歌名就藏在里面!(只是有点难找,需要你一层一层展开:data-song-list-0-name,然后就能看到“知足”)。
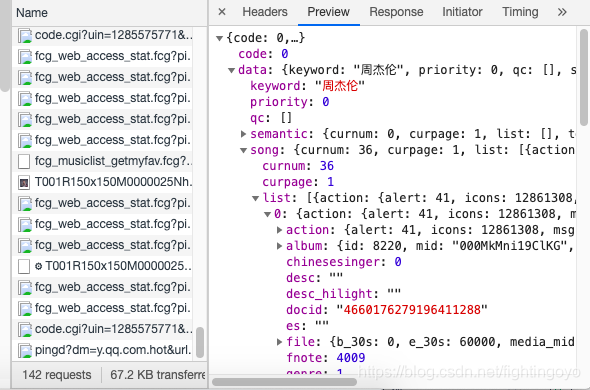
那如何把这些歌曲名拿到呢?这就需要我们去看看最左侧的Headers,点击它。如下所示,它被分为四个板块。
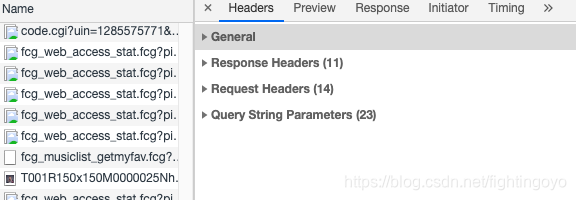
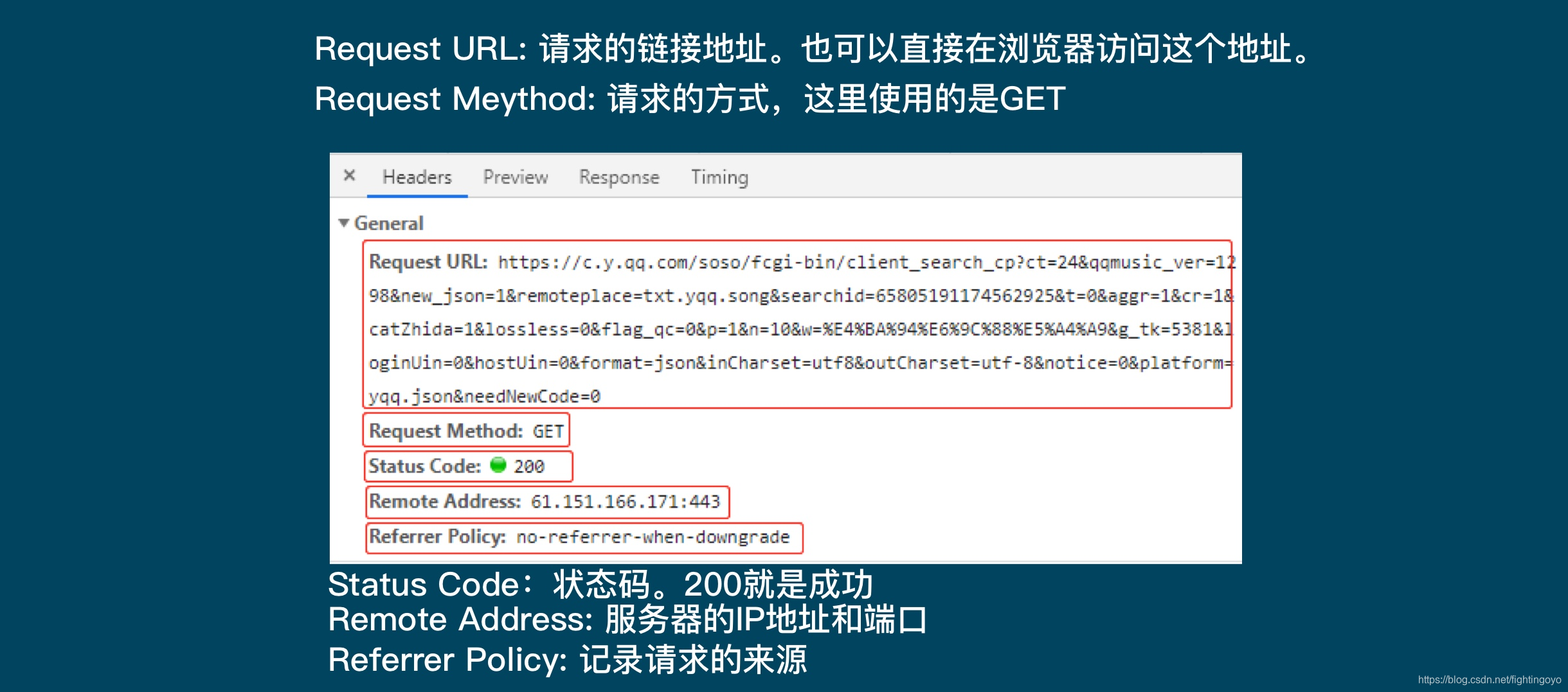
- General里的Requests URL就是我们应该去访问的链接。如果在浏览器中打开这个链接,你会看到一个让人绝望的结构:最外层是一个字典,然后里面又是字典,往里面又有列表和字典……

- 和我们在在Response里看到东西是一致的,回到原网址,直接用Preview来看就好。列表和字典在此都会有非常清晰的结构,层层展开。
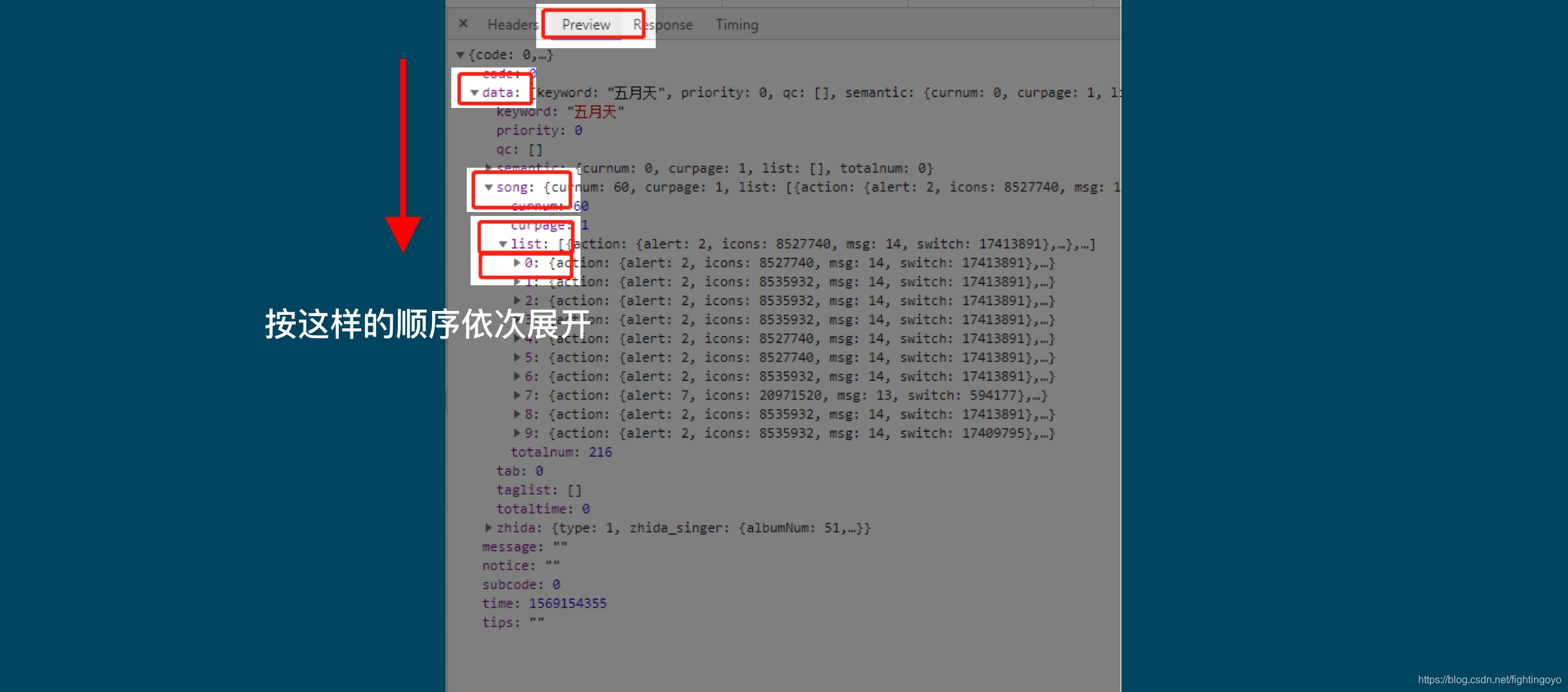
- 歌曲名就在这里,它的键是name。
这个XHR是一个字典,键data对应的值也是一个字典;在该字典里,键song对应的值也是一个字典;在该字典里,键list对应的值是一个列表;在该列表里,一共有20个元素;每一个元素都是一个字典;在每个字典里,键name的值,对应的是歌曲名。
此时,我们可以利用requests.get()访问这个链接,把这个字典下载到本地。然后去一层一层地解析,拿到歌曲名。
import requests
response = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
print(response.text)
输出结果源代码为字符串。
输出的内容为字符串,不是我们想要的字典或者列表,应该怎么办?
四、什么是json
在Python语言当中,json是一种特殊的字符串,这种字符串特殊在它的写法——它是用列表/字典的语法写成的。
# 这是字符串
a = '1,2,3,4,5'
# 这是列表
b = [1, 2, 3, 4, 5]
# 这是字符串,但这是用json格式写的字符串
c = '[1,2,3,4,5]'
这种特殊的写法决定了,json能够有组织地存储信息。
- json是一种组织数据的格式,长得和Python中的列表/字典非常相像。
- 它和html一样,常用来做网络数据传输。刚刚我们在XHR里查看到的列表/字典,严格来说其实它不是列表/字典,它是json。
json和XHR之间的关系:XHR用于传输数据,它能传输很多种数据,json是被传输的一种数据格式.
如何解析json数据
import requests
response = requests.get(
'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
js_music = response.json()
print(type(js_music))
# 输出结果:
<class 'dict'>
通过json()方法实现数据格式的转换。
import requests
response = requests.get(
'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
js_music = response.json()
# 逐层展开字典,获得歌曲列表
list_music = js_music['data']['song']['list']
# 遍历列表,得到每首歌曲的名称
for music in list_music:
print(music['name'])
# 输出结果如下:
晴天
一路向北
七里香
搁浅
稻香
爱的飞行日记
告白气球
不能说的秘密
等你下课
夜曲
再扩展一下,能得到歌曲的其他信息
import requests
response = requests.get(
'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
js_music = response.json()
# 逐层展开字典,获得歌曲列表
list_music = js_music['data']['song']['list']
# 遍历列表,得到每首歌曲的信息
for music in list_music:
# 歌曲名称
name = music['name']
# 歌曲所属专辑
album = music['album']['name']
# 播放时长
time = str(music['interval'])+'秒'
# 播放链接
url = 'https://y.qq.com/n/yqq/song/'+music['mid']+'.html'
print(name+'\n'+album+'\n'+time+'\n'+url+'\n')
# 输出结果如下:
晴天
叶惠美
269秒
https://y.qq.com/n/yqq/song/0039MnYb0qxYhV.html
一路向北
J III MP3 Player
295秒
https://y.qq.com/n/yqq/song/001xd0HI0X9GNq.html
七里香
七里香
299秒
https://y.qq.com/n/yqq/song/004Z8Ihr0JIu5s.html
搁浅
七里香
240秒
https://y.qq.com/n/yqq/song/001Bbywq2gicae.html
稻香
魔杰座
223秒
https://y.qq.com/n/yqq/song/003aAYrm3GE0Ac.html
爱的飞行日记
跨时代
255秒
https://y.qq.com/n/yqq/song/003CxS6w14OQyM.html
告白气球
周杰伦的床边故事
215秒
https://y.qq.com/n/yqq/song/003OUlho2HcRHC.html
不能说的秘密
不能说的秘密 电影原声带
296秒
https://y.qq.com/n/yqq/song/002MXZNu1GToOk.html
等你下课
等你下课
270秒
https://y.qq.com/n/yqq/song/001J5QJL1pRQYB.html
夜曲
十一月的萧邦
226秒
https://y.qq.com/n/yqq/song/001zMQr71F1Qo8.html
五、小结
Network能够记录浏览器的所有请求。我们最常用的是:
- ALL(查看全部);
- XHR(仅查看XHR);
- Doc(Document,第1个请求一般在这里);
- 有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他);
- 最后,JS和CSS,则是前端代码,负责发起请求和页面实现;
- Font是文字的字体;
- 而理解WS和Manifest,需要网络编程的知识。

在Network,有非常重要的一类请求是XHR(或Fetch),因为有它的存在,人们不必刷新/跳转网页,即可加载新的内容。随着技术发展,XHR的应用频率越来越高,我们常常需要在这里找我们想要的数据。
如何解析json数据?

import json
# 引入json模块
a = [1,2,3,4]
# 创建一个列表a。
b = json.dumps(a)
# 使用dumps()函数,将列表a转换为json格式的字符串,赋值给b。
print(b)
# 打印b。
print(type(b))
# 打印b的数据类型。
c = json.loads(b)
# 使用loads()函数,将json格式的字符串b转为列表,赋值给c。
print(c)
# 打印c。
print(type(c))
# 打印c的数据类型。
# 输出结果如下:
[1, 2, 3, 4]
<class 'str'>
[1, 2, 3, 4]
<class 'list'>
但以上的代码并没有解决我们的问题,我们想要的是周杰伦所有的歌曲,而不是只有只有10首歌,应该怎么办呢?
六、拿到周杰伦所有歌曲清单
首先看案例,爬取豆瓣电影:https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
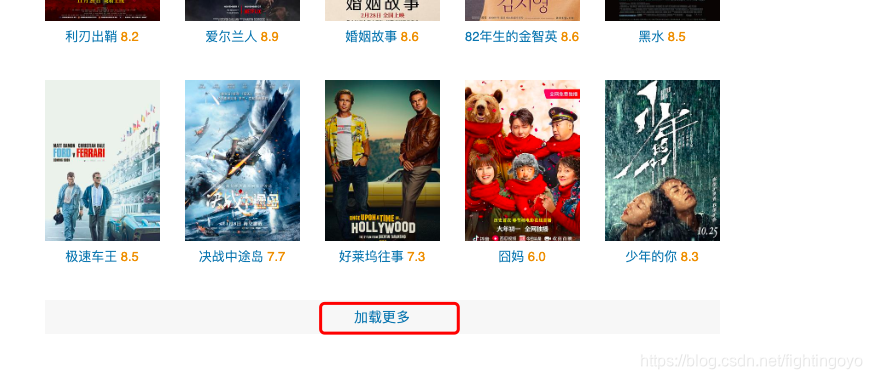
整个页面总共有20部电影,想要一次爬取到所有关于所有的电影名称是不可能的。也就是说,想要爬取更多的专辑数据的难点就在于加载更多了。
这种加载模式就是“动态加载”。在点击了相应的页码后,服务器就会根据新的XHR更新页面信息。
1. 带参数请求数据
观察刚刚给出的豆瓣的网址,能看到每个url都由两部分组成。
- 前半部分大多形如:https://xx.xx.xxx/xxx/xxx。
- 后半部分,多形如xx=xx&xx=xxxxxx&xx=xx&……
- 两部分使用“?”来连接。
当我们在具有搜索功能的网页上进行搜索的时候,你看到的结果基本这个形式一致。前半部分是所访问的网页地址。
而后半部分,就是我们说的请求参数,它告诉服务器,我们想要什么样的数据。这参数的结构,会和字典很像,有键有值,键值用=连接;每组键值之间,使用&来连接。
下面进入实操部分。
- 进入网址:https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0,清空记录后打开Network,选中All,点击刷新。
- 当我们点开第1个请求来看看(看Preview或Response都可以),可以明显的观察到这里的内容没有我们需要的信息。
- 接下来,我们观察XHR。
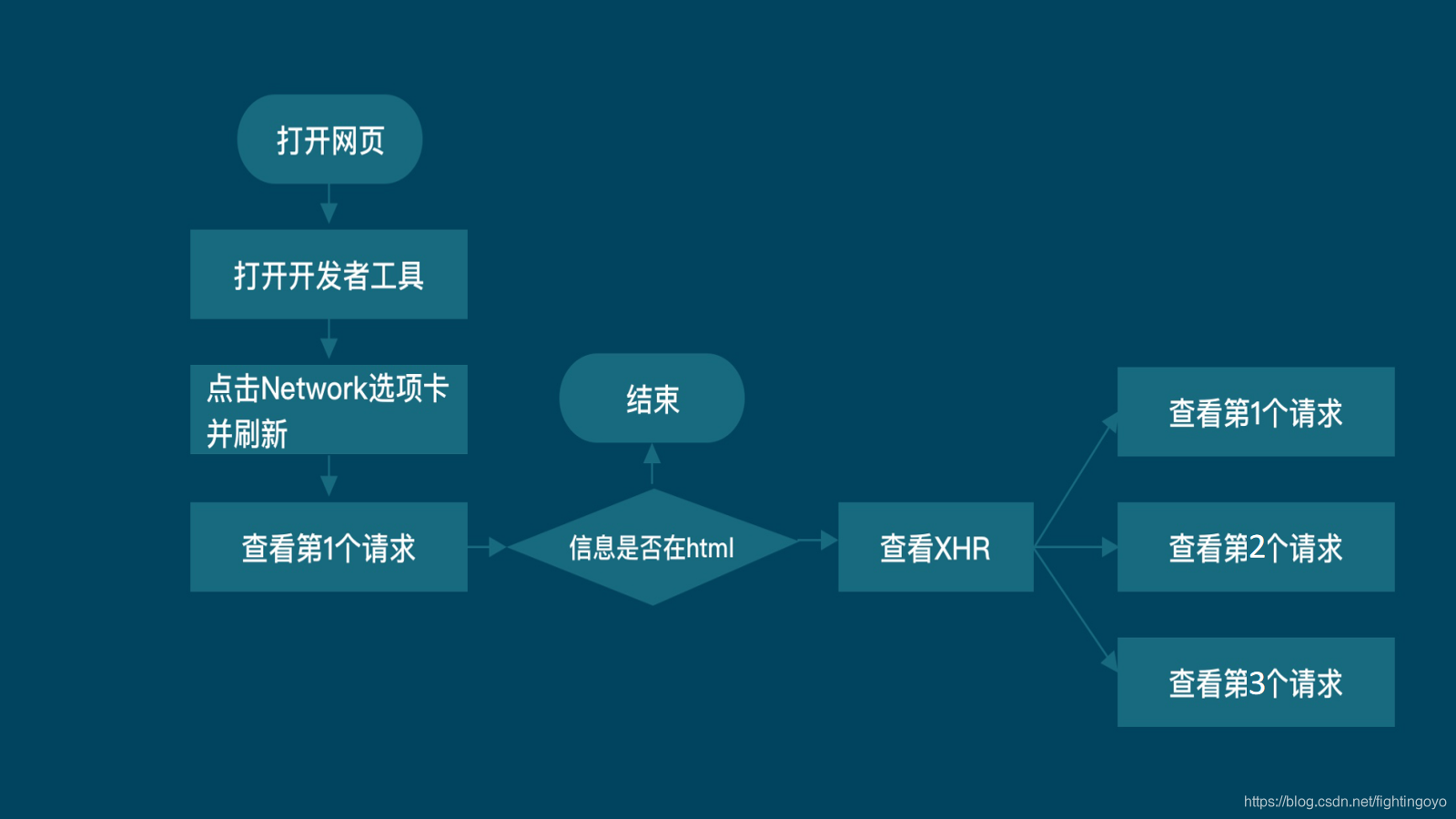
- 接着我们要对Preview中的内容进行查看,当我们点击其中一个时,能够在[‘subjects’][x][‘title’]里找到电影名称(x代表list中的顺序)。列表的每一个元素都是字典,字典里键title对应的值,就是我们要找的电影名称。
- 如此一来,我们就能在找到拥有电影名称的页面链接(请求的Headers栏:General中的Request URL):
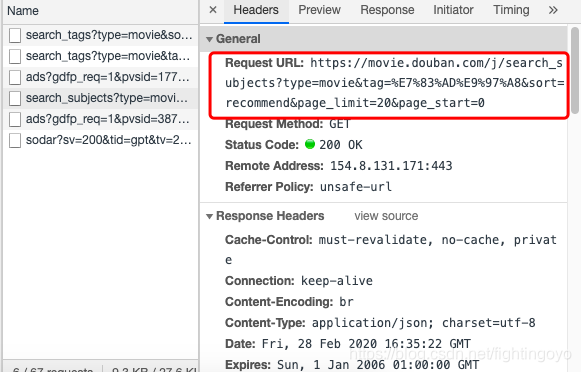
- 这样一长串的链接看起来真令人头大。别急,其实Network面板提供了一个更友好的查看方式。在General的下方,有一个没有展开的标签:Query String Parametres,让我们点开它看看里面的内容。
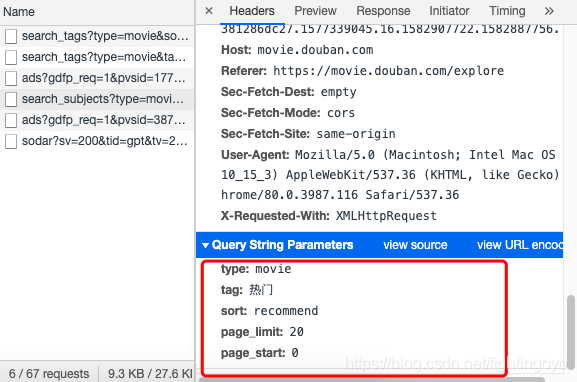
Query String Parametres的中文翻译就是:查询字符串参数。把里面的内容和上面的链接中的参数进行对比,我们可以发现是完全一致的(链接中data的值看起来和Query String Parametres中的值不一致是因为采用了UTF-8编码的原因,点击”view URL encoded“会看到相同的结果)。
这个面板用类似字典的形式,呈现了各个参数的键值。
2. 如何带参数请求数据
首先需要读懂参数。
读懂参数,有两个重要的方法是“观察”和“比较”。
- “观察”指的是阅读参数的键与值,尝试去理解参数的含义。
-
- “比较”指的是比较两个相近的XHR,例如选电影的初始页面和点击”加载更多“之后。看看它们的参数有哪些不同。
分别点开初始页面和点击加载更多后的页面,它们之间的Query String Parametres参数之间有什么不同。
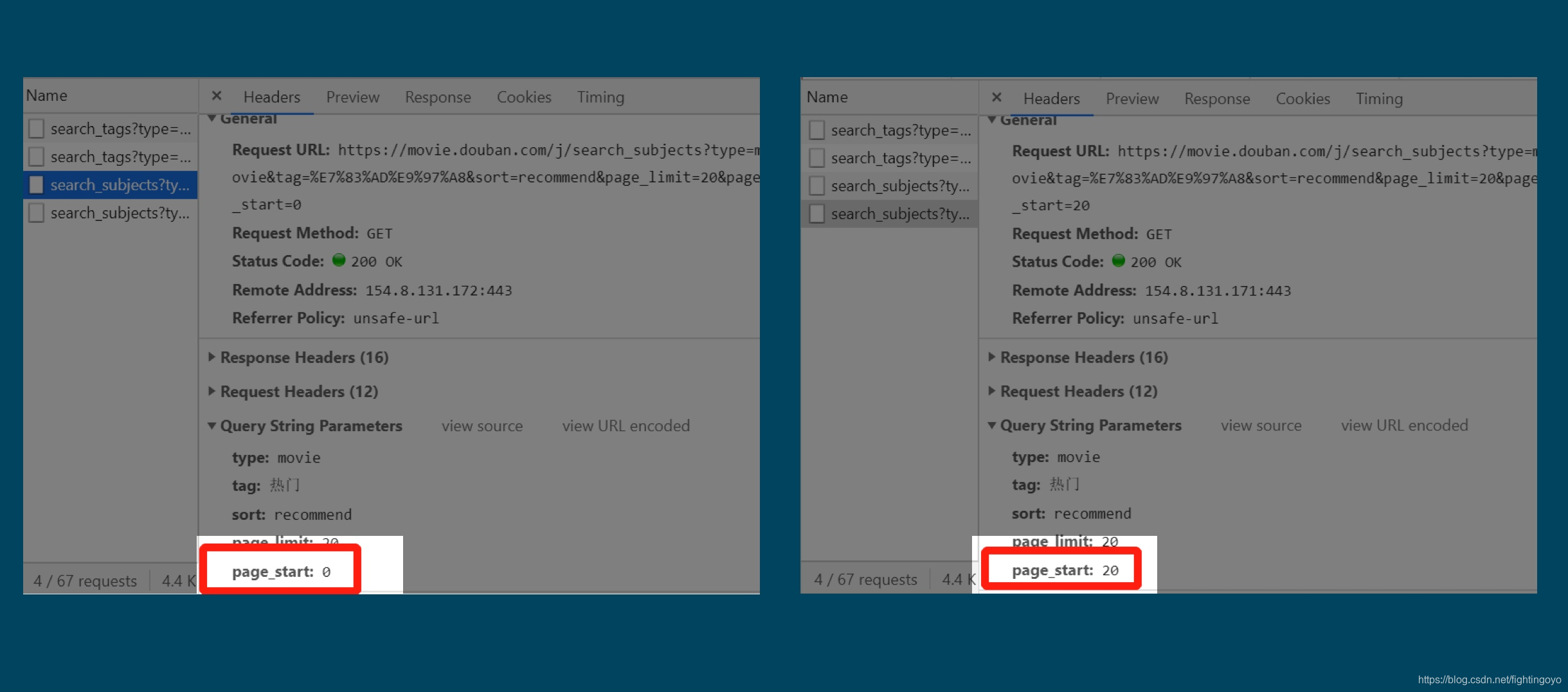
当我们多点击几次页面按钮,我们可以观察到众多参数中,只有一个参数在变化。这个参数是page_start,点击进入初始页面时它的值为0,点击一次加载更多时,它的值就变成了20,再点击一次加载更多,它的值就变成了40。
- “比较”指的是比较两个相近的XHR,例如选电影的初始页面和点击”加载更多“之后。看看它们的参数有哪些不同。
3. 代码实现
import requests
# 伪装请求头,避免反爬
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
# 使用requests.get()方法获取网页返回数据,并使用循环更改url的page_start参数
for i in range(4):
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=' + str(
i * 20)
response = requests.get(url, headers=headers)
# 使用json方法,将获取到的字符串数据转换为字典/列表
js_movie = response.json()
# 逐层展开字典,获取电影列表
list_movie = js_movie['subjects']
# 循环遍历列表,获取每个电影的信息
for movie in list_movie:
name = movie['title']
rating = movie['rate']
movie_url = movie['url']
print(name + '\n' + rating + '\n' + url + '\n')
切记,此处的URL不是网页网址处的URL,而是XHR内header处的URL,若搞错了,程序将会报错!
但,此处我们看到URL显得又臭又长,一方面是不方便观看,另一方面是不方便修改。要怎么才能优雅又美观的实现呢?
requests模块里的requests.get()提供了一个参数叫params,可以让我们用字典的形式,把参数传进去。
- 可以将Query String Parametres里的内容进行封装,把page_start键的值作为一个变量,传递给params。需要注意的是,我们要给字典里的键和值加上双引号,让他们成为字符串。
import requests
# 伪装请求头,避免反爬
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
# 使用requests.get()方法获取网页返回数据,并使用循环更改url的page_start参数
for i in range(4):
# 将"?"前的部分url提取出来
url = 'https://movie.douban.com/j/search_subjects'
# 封装字典网址请求参数
param = {'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '20',
'page_start': str(i * 20)}
response = requests.get(url,params=param,headers=headers)
# 使用json方法,将获取到的字符串数据转换为字典/列表
js_movie = response.json()
# 逐层展开字典,获取电影列表
list_movie = js_movie['subjects']
# 循环遍历列表,获取每个电影的信息
for movie in list_movie:
name = movie['title']
rating = movie['rate']
movie_url = movie['url']
print(name + '\n' + rating + '\n' + url + '\n')
再回到周杰伦的歌曲列表中,在我们之前的爬取过程中,QQ音乐的网页告诉我们:想要查看更多内容,请下载一个客户端。

观察URL:https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6
- 前半部分是https://y.qq.com/portal/search.html
- 后半部分是page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6
- 不过二者之间是用#连接,而不是用?。
- 其实,“#”替换成“?”,访问的效果是一样的(注意:用“?”分隔的url不一定可以用“#”代替)。
我们是否可以通过更改page的参数,而获得更多的歌曲呢?
在page=1、page=2、page=3的三个client_search_cp…的请求中,唯一变化的参数只有p,它代表的就是页码。分析到这里,我们就应该能爬取到五月天所有的歌曲信息了。下面我们来爬取前三页的数据。
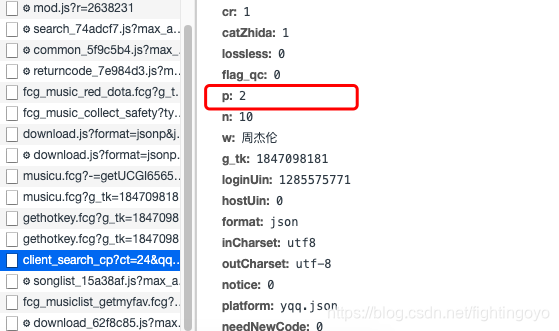
import requests
# 请求头,避免反爬
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
# 请求参数
for i in range(1,5):
param = {'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'txt.yqq.song',
'searchid': '56588131188165363',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': str(i),
'n': '10',
'w': '周杰伦',
'g_tk': '1847098181',
'loginUin': '1285575771',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
response = requests.get(url,params=param,headers=headers)
# 使用json()方法,将response对象,转为列表/字典
js_music = response.json()
# 逐层展开字典,获得歌曲列表
list_music = js_music['data']['song']['list']
# 遍历列表,得到每首歌曲的信息
for music in list_music:
# 歌曲名称
name = music['name']
# 歌曲所属专辑
album = music['album']['name']
# 播放时长
time = str(music['interval'])+'秒'
print(i)
print(name)
print(album)
print(time)
4. 什么是Rquests headers
其实我们打开每一个请求,都会有一个Requests Headers,一般我们称之为“请求头”。它里面会有一些关于该请求的基本信息,例如它会记录发出请求的设备和浏览器。
- 图中的user-agent(即用户代理)记录的就是我的电脑系统信息(Mac OS)和浏览器(谷歌浏览器)。

- origin和referer则是记录了这个请求的最初来源是哪个页面。
- 相比之下referer会比origin更长,这意味着referer会携带更多的信息。
根据Requests模块的官方文档,它是允许我们去修改Headers的值的:
- 与封装params非常类似,我们只需要将origin或referer一并作为字典写入headers就好。
import requests
# 引用requests模块
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'origin':'https://y.qq.com',
# 请求来源
'referer':'https://y.qq.com/n/yqq/song/004Z8Ihr0JIu5s.html',
# 请求来源
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
# 伪装请求头
param = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'sizer.yqq.song_next',
'searchid': '64405487069162918',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': 1,
'n': '10',
'w': '五月天',
'g_tk': '5381',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
res_songs= requests.get(url, params=param, headers=headers)
要使用这个字典,我们只需要再request函数中将它赋值给headers参数就好了。
七、练习
- 拿到周杰伦前三页歌曲的歌词
import requests
# 伪装歌曲请求头
headers = {'orgin': 'https://y.qq.com',
'referer': 'https://y.qq.com/portal/search.htm',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
# 歌曲请求的网址
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
# 循环更新页码
for i in range(1,4):
# 歌曲请求参数
param_song = {'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'txt.yqq.song',
'searchid': '67279455817994118',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': i,
'n': '10',
'w': '周杰伦',
'g_tk': '1987388883',
'loginUin': '1285575771',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'}
# 使用requests.get(),获取返回的数据
response = requests.get(url,params=param_song,headers=headers)
# 使用json(),将字符串转为列表/字典
js_music = response.json()
# 层层展开字典,获取歌曲列表
list_musci = js_music['data']['song']['list']
# 遍历歌曲列表,获取每首歌曲的信息
for music in list_musci:
title = music['name']
id = music['id']
album = music['album']['name']
time = music['interval']
link = 'https://y.qq.com/n/yqq/song/'+music['mid']+'.html'
# 伪装歌词请求头
headers_lyric = {'origin': 'https://y.qq.com',
'referer': 'https://y.qq.com/n/yqq/song/{}.html'.format(music['mid']),
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
# 歌词url
url_lyric = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg'
# 歌词请求参数
param_lyric = {'nobase64': '1',
'musicid': id,
'-': 'jsonp1',
'g_tk': '1847098181',
'loginUin': '1285575771',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
response_lyric = requests.get(url_lyric,params=param_lyric,headers=headers)
js_lyric = response_lyric.json()
lyric = js_lyric['lyric']
print('页码:'+str(i))
print('歌名:'+title)
print('歌曲ID:'+str(id))
print('专辑名:'+album)
print('播放时长:'+str(time)+'秒')
print('播放链接:'+link)
print('歌词:'+lyric)
- 可以输入任意歌手的名称,获取前三页的歌曲信息和歌词。
import requests
# 输入歌手名称
singer = input('请输入歌手名字:')
# 伪装歌曲请求头
headers = {'orgin': 'https://y.qq.com',
'referer': 'https://y.qq.com/portal/search.htm',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
# 歌曲请求的网址
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
# 循环更新页码
for i in range(1,4):
# 歌曲请求参数
param_song = {'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'txt.yqq.song',
'searchid': '67279455817994118',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': i,
'n': '10',
'w': singer,
'g_tk': '1987388883',
'loginUin': '1285575771',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'}
# 使用requests.get(),获取返回的数据
response = requests.get(url,params=param_song,headers=headers)
# 使用json(),将字符串转为列表/字典
js_music = response.json()
# 层层展开字典,获取歌曲列表
list_musci = js_music['data']['song']['list']
# 遍历歌曲列表,获取每首歌曲的信息
for music in list_musci:
title = music['name']
id = music['id']
album = music['album']['name']
time = music['interval']
link = 'https://y.qq.com/n/yqq/song/'+music['mid']+'.html'
# 伪装歌词请求头
headers_lyric = {'origin': 'https://y.qq.com',
'referer': 'https://y.qq.com/n/yqq/song/{}.html'.format(music['mid']),
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
# 歌词url
url_lyric = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg'
# 歌词请求参数
param_lyric = {'nobase64': '1',
'musicid': id,
'-': 'jsonp1',
'g_tk': '1847098181',
'loginUin': '1285575771',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
response_lyric = requests.get(url_lyric,params=param_lyric,headers=headers)
js_lyric = response_lyric.json()
lyric = js_lyric['lyric']
print('页码:'+str(i))
print('歌名:'+title)
print('歌曲ID:'+str(id))
print('专辑名:'+album)
print('播放时长:'+str(time)+'秒')
print('播放链接:'+link)
print('歌词:'+lyric)
