今天主要讲了两块内容,第一块是正则表达式,第二块是列表
先来说说列表吧,毕竟比正则表达式容易理解
1.列表也是一种数据类型,在Python中,列表是有序的。列表使用中括号来定义 [ ]它可以作为一个方括号内的逗号分隔值出现。
#列表的数据项不需要具有相同的类型,同一个列表中可以同时存在字符串、数字等不同类型的值
mylist=["zyw",1998]
print(mylist)以上实例输出结果为
["zyw",1998]
2.列表中也可以使用切片,和字符串切片用法相同,直接输入索引可以对列表进行切片操作。
mylist=["hello","world","zyw",1998,1,2018]
print(mylist[:])#等价于print(mylist)
print(mylist[1:3])#输出索引为1-3的元素但不会取到3,所以只会输出两个值,索引为1和索引为2的值以上实例运行结果为:
["hello","world","zyw",1998,1,2018]
["world","zyw"]
3.接下来就是列表的增删改查
增:insert append extend
insert是给一个列表的指定索引位置添加元素,基本语法为list.insert(索引位置,要添加的值)
append是在一个列表的最后面添加元素,基本语法为list.append(要添加的元素)
extend比较特殊,他是把一个列表的元素迭代添加到另一个列表中。基本语法为list1.extend(list2),就是把列表2的元素添加到列表1中。它和list1.append(list2)的区别是append会把整个列表2添加到列表1中,而extend会把列表2的每个元素进行迭代分别添加到列表1中。
list1=["hello"]
list2=[521]
list1.insert(0,"world")#向列表1中索引值为0的地方添加“world”
print(list1)
list2.append("zyw")#在列表2的最后面添加“zyw”
print(list2)
list1.extend(list2)#它和list1.append(list2)是有区别的
print(list1)以上代码运行结果为:
["world","hello"]
[521,"zyw"]
["world","hello",521,"zyw"]
如果是list1.append(list2)
运行结果会是["world","hello",[521,"zyw"]]
删:del pop() remove()
del比较简单,直接del list[要删除元素的索引值]就可以
pop()是把最后一个删除,也可以删除指定的下标,和del不同的是它再删除的时候会返回这个删除的值,如果把这个被删除的值赋给一个变量,以后还可以调用这个被删除的值。
remove(“”)删除括号中指定的列表内的内容,如果有多个,只会删除一个。list=["world","hello","hello",521,"zyw","zyw"] del list[0]#删除索引值为0的那个值 a=list.pop()#删除最后一个元素,括号里也可以直接写索引删除指定索引的值 list.remove("hello")#删除列表中的“hello”,如果有多个,只会删除一个 print(a) print(list)以上代码运行结果为:
zyw
["hello",521,"zyw"]
改:改就比较简单了,直接
list[要改的值的索引]=要改成的新值就可以了list=[1,2,3] list[0]=2#把索引为0的那个值改成2 print(list)所以运行结果为:
[2,2,3]
查:index() in 或者 not in
list.index(“1”)括号中写一个值,查找这个值在列表中的索引,如果要查找的值不在列表中会报错
in 或者 not in 查找方法和字符串中查找字符的用法基本相同,如果一个元素在一个列表中则返回True,否则则返回False扫描二维码关注公众号,回复: 1891332 查看本文章
list=[1,2,3] print(list.index(2))#查找并打印2在列表中的索引值,没有2则程序会报错 if 4 in list: print("4在列表中") else: print("4不在列表中")以上代码运行结果为:
1
4不在列表中
接下来就是让人头痛的正则表达式了
1.正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
2.正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
3.正则表达式的各种符号含义:
在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,
\w可以匹配一个字母或数字,所以:
00\d可以匹配007,但无法匹配00A;
\d\d\d可以匹配010;
\w\w\d可以匹配py3;
.可以匹配任意字符,所以:
py.可以匹配pyc、pyo、py!等等。
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符:
来看一个复杂的例子:\d{3}\s+\d{3,8}。
我们来从左到右解读一下:
\d{3}表示匹配3个数字,例如010;
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配’ ‘,’ ‘等;
\d{3,8}表示3-8个数字,例如1234567。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配010-12345这样的号码呢?由于-是特殊字符,在正则表达式中,要用\转义,所以,上面的正则是\d{3}\-\d{3,8}。
但是,仍然无法匹配010 - 12345,因为带有空格。所以我们需要更复杂的匹配方式。
要做更精确地匹配,可以用[]表示范围,比如:
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线;
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如a100,0_Z,Py3000等等;
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配Python或者python。
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。
你可能注意到了,py也可以匹配python,但是加上^py$就变成了整行匹配,就只能匹配py了。
其中,\d \w \s可以用大写\D \W \S,就是表示匹配一个非数字字符。等价于 [^0-9],匹配任何非单词字符。等价于 [^A-Za-z0-9_]和匹配任何非空白字符。等价于 [^ \f\n\r\t\v]
4.re.match(正则表达式,要匹配的文本)
匹配成功re.match方法返回一个匹配的对象,否则返回None。
import re print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配以上代码运行结果为:
(0,3)
None
5.re.search(正则表达式,要匹配的文本)
re.search 扫描整个字符串并返回第一个成功的匹配
import re print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配以上代码运行结果为:
(0, 3)
(11, 14)
6.re.findall(正则表达式,要匹配的字符)
在字符串中找到正则表达式所匹配的所有字串,并返回一个列表,如果没有找到匹配的,则返回空列表。
import re m=re.findall(r'a.*?c',"abbcabcandddc") print(m)以上代码执行结果为:
["abbc","abc","andddc"]
7.re.match与re.search和re.findall的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配为止;re.findall返回的是一个列表,而match和search都只匹配一次,findall可以匹配多次
8.re.spilt(正则表达式,要切分的字符串[起始索引:结束索引])
正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
'a b c'.split(' ')以上切分结果为:
['a', 'b', '', '', 'c'],无法识别连续的空格,用正则表达式试试:import re re.split(r'\s+', 'a b c')结果为
['a', 'b', 'c'],无论多少个空格都可以正常切分
还可以这么用:import re re.split(r'[\s\,\;]+', 'a,b;; c d')结果也是
['a', 'b', 'c', 'd']
9.正则表达式分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345') m.group(0) #输出结果为'010-12345' m.group(1) #输出结果为'010' m.group(2) #输出结果为'12345'如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
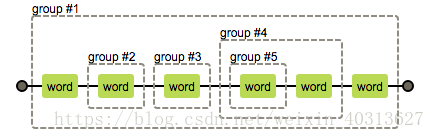
(\w(\w)(\w)((\w)\w)\w)其组号分配如图所示:
10.贪婪匹配和非贪婪匹配
最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
re.match(r'^(\d+)(0*)$', '102300').groups() ('102300', '')由于
\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:re.match(r'^(\d+?)(0*)$', '102300').groups() ('1023', '00')如下所示:
import re m=re.findall(r'a.*c',"abbcabcandddc") print(m)这个输出的结果是:
["abbcabcandddc"],因为采用了默认的贪婪匹配,所以a.*c会匹配到整个的字符串,如果不想让它匹配整个字符串的话就得让.*尽可能少的匹配,所以改成:import re m=re.findall(r'a.*?c',"abbcabcandddc") print(m)输出结果就会变成:
["abbc","abc","andddc"]