零碎知识点
- 正规式等价是指两个正规式所识别的语言集相等
- 中间代码生成时所依据的是:语义规则
- 编译程序绝大多数时间花在管理表格上
- 词法分析器的输出结果是单词的种别编码和自身值
- 堆式动态分配申请和释放存储空间遵循任意原则
- 并不是每个文法都能改写成LL(1)文法
- LR分析器由三部分构成:总控程序、分析表、分析栈
- 自底而上语法分析方法的主要问题是什么?
- 什么是简单优先文法
- 什么是算符优先文法
- 文法G所描述的语言是由文法的开始符号推出的所有终结符号串的集合
- 非LL(1)文法变为LL(1)文法可以使用消除左递归、提取左公因子两种方法
- 三种级别的优化:局部优化、循环优化、全局优化
求文法的FIRST集、FOLLOW集、SELECT集并判断文法是否为LL(1)文法:
例题:
文法G[E]:
E->TE'
E'->+E|ε
T->FT'
T'->T|ε
F->PF'
F'->*F'|ε
P->(E)|a|b|^
一、求出能推算出ε的非终结符
创建表:
| 非终结符 | E | E’ | T | T’ | F | F’ | P |
|---|---|---|---|---|---|---|---|
| 多遍扫描后 | 否 | 是 | 否 | 是 | 否 | 是 | 否 |
二、求FIRST集
定义

设G=(VT,VN,S,P)是上下文无关文法 ,FIRST(α)={a|α能推导出aβ,a∈VT,α,β∈V*}
特别的,若α能推导出ε,则规定ε∈FIRST(α).
结果
FIRST(E)=FIRST(T)=FIRST(F)=FIRST(P)={(,a,b,^};
FIRST(E')={+,ε};
FIRST(T)=FIRST(F)=FIRST(P)={(,a,b,^};
FIRST(T')=FIRST(T)∪{ε}={(,a,b,^,ε};
FIRST(F)=FIRST(P)={(,a,b,^};
FIRST(F')=FIRST(P)={*,ε};
FIRST(P)={(,a,b,^};
三、求FOLLOW集
定义

结果
FOLLOW(E)={),#};
FOLLOW(E')=FOLLOW(E)={),#};
FOLLOW(T)=FIRST(E')∪FOLLOW(E)={+,),#};不包含ε
FOLLOW(T')=FOLLOW(T)=FIRST(E')∪FOLLOW(E)={+,),#};
FOLLOW(F)=FIRST(T')∪FOLLOW(T)={(,a,b,^,+,),#};//不包含ε
FOLLOW(F')=FOLLOW(F)=FIRST(T')∪FOLLOW(T)={(,a,b,^,+,),#};
FOLLOW(P)=FIRST(F')∪FOLLOW(F)={*,(,a,b,^,+,),#};//不包含ε
四、求SELECT集
定义

结果
SELECT(E->TE')=FIRST(T)={(,a,b,^};
SELECT(E'->+E)={+ };
SELECT(E'->ε)=FOLLOW(E/)={),#};
SELECT(T->FT')=FIRST(F)={(,a,b,^}
SELECT(T'->T)=FIRST(T)={(,a,b,^};
SELECT(T'->ε)=FOLLOW(T/)={+,),#};
SELECT(F->PF')=FIRST(P)={(,a,b,^};
SELECT(F'->*F')={*};
SELECT(F'->ε)=FOLLOW(F')={(,a,b,^,+,),#};
SELECT(P->(E))={(}
SELECT(P->a)={a}
SELECT(P->b)={b}
SELECT(P->^)={^}
五、判断是否为LL(1)文法

由四中的SELECT集可知,相同左部产生式的SELECT集交集为空,所以该文法为LL(1)文法。
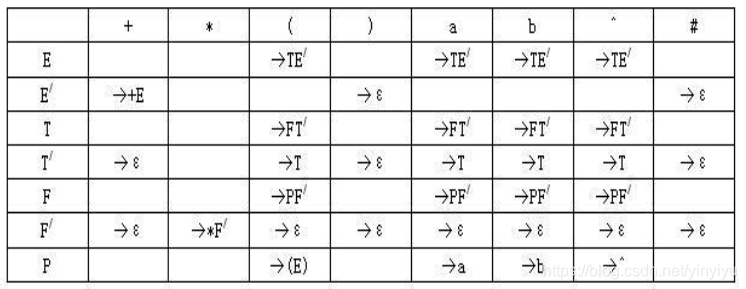
六、构造预测分析表
方法

结果