-
构造正规表达式a(aa)*bb(bb)a(aa) 的NFA。
解: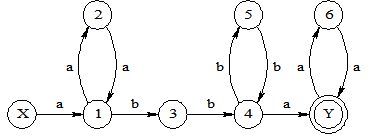
-
构造正规表达式((a|b)*|aa)*b的NFA。
解: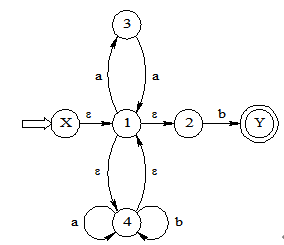
-
令文法G[N]为 G[N]: N→D|ND
D→0|1|2|3|4|5|6|7|8|9
给出句子568的最左、最右推导。
解:
最左推导:N–> ND–> NDD–> DDD–> 5DD–> 56D–> 568
最右推导:N–> ND–> N8–> ND8–> N68–> D68–> 568 -
给出字母表Σ={a,b}上的同时只有奇数个a和奇数个b的所有串的集合的正规文法;
解: G[S]:S→aA|bB
A→aS|bC|b
B→bS|aC|a
C→bA|aB|ε -
给定文法:S→(L) | a
L→L,S | S
请书写语义规则,求输出句子中每一个a的括号嵌套深度。
解:用继承属性depth表示嵌套深度,则
S’ → S S.depth = 0
S → (L) L.depth = S.depth + 1
S → a print(S.depth)
L → L(1), S L(1).depth = L.depth; S.depth = L.depth
L → S S.depth = L.depth
-
表达式a*b-c-d$e$f-g-h*i中,运算符的优先级由高到低依次为-、*、$,且均为右结合,请写出相应的后缀式。
第一步:按照运算符的优先级对所有的运算单位加括号~
式子变成拉:((a*(b-c-d))$(e$((f-g-h)*i)))
第二步:转换前缀与后缀表达式
后缀:把运算符号移动到对应的括号后面
则变成拉:((a(bcd)–)*(e((fgh)–i)*)$)$
把括号去掉:括号后缀式子出现
解: abcd- -*efgh- - i*$$ -
判断文法G[S]: S → BA
A → BS | d
B → aA| bS | c
是否为LL(1)文法.
解:对于该文法求其FIRST集如下:
FIRST(S) = {a, b, c}; FIRST(A) = {a, b, c, d}; FIRST(B) = {a, b, c}。
求其FOLLOW集如下:
FOLLOW(S) = {a, b, c, d, #}; FOLLOW(A) = {a, b, c, d, #}; FOLLOW(B) = {a, b, c, d, #}。
由A → BS | d 得:
FIRST(BS) ∩ FIRST(‘d’) = {a, b, c} ∩ {d} = Φ
由B → aA| bS | c 得
FIRST(aA) ∩ FIRST(bS) ∩ FIRST© = {a} ∩{b}∩ {c} =Φ
由于文法G[S]不存在形如β→ε的产生式,故无需求解形如FIRST(α) ∩ FOLLOW(A)的值,也即文法G[S]是一个LL(1)文法。 -
对于文法G[E]: E→E+T | T
T→T+P | P
P→(E) | i
写出句型P+T+(E+i)的所有短语、直接短语、句柄。
解:短语:P、P+T、i、E+i、(E+i )、P+T+(E+i );
直接短语:P、i;
句柄:P; -
已知文法
G[A]: A→aABl|a
B→Bb|d
试给出与G[A]等价的LL(1)文法G[A′];
解:
G[A′]:A→aA′
A′→ABl | ε
B→dB′
B′→bB′| ε -
将下面的语句翻译成四元式序列:
if (x>y) m= 1;
else m=0;
解:
1 (j>,x,y,3)
2 (j,_,_,5)
3 (=,1,_,m)
4 (j,_,_,6)
5 (=,0,_,m)
6:
- 将以下DFA 最小化。(8分)
解:
-
将状态分解为
– 终态集{Y}
– 非终态集{X,1,2} -
考察非终态集{X,1,2}接收a字符
– X接收a字符到1 (1属于非终态集)
– 1不接收字符
– 2接收a字符到1 (1属于非终态集)
故将非终态集{X,1,2},分为{X,2},{1} -
考察{X,2}接收b字符
– X接收不接受b
– 2接收不接受b -
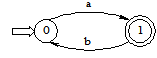
按顺序重新命名状态子集{X,2},{1},{Y}为0,1,2得到状态转换矩阵
| S | a | b |
|---|---|---|
| 0 | 1 | 空 |
| 1 | 空 | 0 |
| 2 |
- 根据状态转换矩阵绘制化简后的状态转换图
- 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f定义如下:
f(x,a)={x,y} f{x,b}={y}
f(y,a)=Φ f{y,b}={x,y}
试构造相应的确定有限自动机M′。(12分)
解:对照自动机的定义M=(S,Σ,f,So,Z),由f的定义可知f(x,a)、f(y,b)均为多值函数,因此M是一非确定有限自动机。
先画出NFA M相应的状态图,如下图所示。
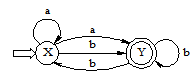
用子集法构造状态转换矩阵,如下表所示。
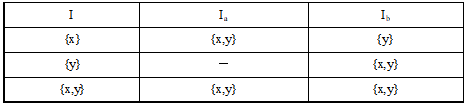
将转换矩阵中的所有子集重新命名,形成下表所示的状态转换矩阵,即得到

M′=({0,1,2},{a,b},f,0,{1,2}),
M′状态转换图如下图所示。
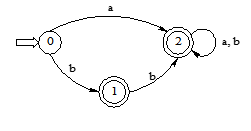
(注意:本题由于集合的命名和先后顺序不同,可能最终结果不同。)
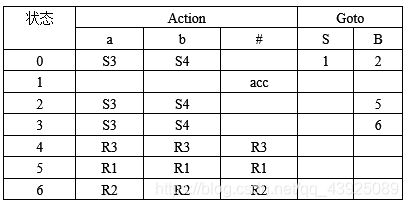
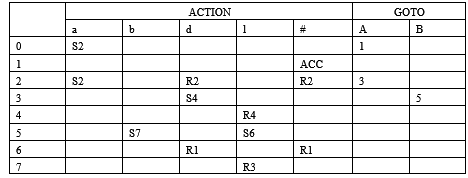
- 试构造下述文法的SLR(1)分析表。(13分)
G[A]: A→aABl|a
B→Bb|d
解:拓广文法
(0)S→A
(1)A→aABl
(2)A→a
(3)B→Bb
(4)B→d
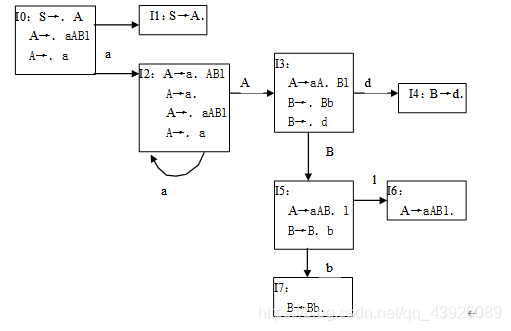
First(A)={a}follow(A)={#,d}
First(B)={d}follow(B)={l}
SLR(1)分析表如下:
13.将下面的语句翻译成四元式序列:(7分)
if (x>y) m= 1;
else m=x+y;
解:
1 (j>,x,y,3)
2 (j,_,_,5)
3 (=,1,_,m)
4 (j,_,_,7)
5 (+,x,y,T1)
6 (=, T1,_,m)
7:
-
试构造下述文法的LL(1)分析表。(15分)
G[S]: S→(L)|a
L→L,S|S
解:消除左递归:
G(S): S → (L) | a
L → SL’
L’ → , SL’| ε
构造FIRST集,如下:
(1)FIRST(S) = {(, a}
(2)FIRST(L) = {(, a}
(3)FIRST(L’) = {, , ε}
构造FOLLOW集如下:
(1)FOLLOW(S) = {#, , ,)}
(2)FOLLOW(L) = {)}
(3)FOLLOW(L’) = {)}

-
判断文法G[S]: S → BA
A → BS | d
B → aA| bS | c
是否为LL(1)文法.
解:对于该文法求其FIRST集如下:
FIRST(S) = {a, b, c};
FIRST(A) = {a, b, c, d};
FIRST(B) = {a, b, c}
求其FOLLOW集如下:
FOLLOW(S) = {a, b, c, d, #};
FOLLOW(A) = {a, b, c, d, #};
FOLLOW(B) = {a, b, c, d, #}
由A → BS | d 得:
FIRST(BS) ∩ FIRST(‘d’) = {a, b, c} ∩ {d} = Φ
由B → aA| bS | c 得
FIRST(aA) ∩ FIRST(bS) ∩ FIRST( c ) = {a} ∩{b}∩ {c} =Φ
由于文法G[S]不存在形如β→ε的产生式,故无需求解形如FIRST(α) ∩ FOLLOW(A)的值,也即文法G[S]是一个LL(1)文法。 -
对于文法G[E]: E→E+T | T
T→T+P | P
P→(E) | i
写出句型P+T+(E+i)的所有短语、直接短语、句柄。
解:短语:P、i、E+i、(E+i )、T+(E+i )、P+T+(E+i );
直接短语:P、i;
句柄:P; -
已知文法G[S]: S→aSbS|bSaS|ε
试证明G[S]是二义文法
证明: 该文法产生的语言是a的个数和b的个数相等的串的集合。
该文法二义,例如句子abab有两种不同的最左推导。
S→aSbS→abS→abaSbS→ababS→abab
S→aSbS→abSaSbS→abaSbS→ababS→abab -
将下面的语句翻译成四元式序列:
while(a<b)
if (c>d) x=y+z
解:100 (j<,a,b,102)
101 (j,_,_,107)
102 (j>,c,d,104)
103 (j,_,_,106)
104 (+,y ,z ,t)
105 (=,t ,_ ,x)
106 (j,_,_,100)
107:
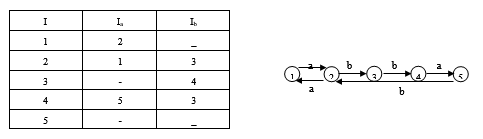
- 构造正规表达式a(aa)*bb(bb)*a 的最小化的确定有限自动机M′。
解: 先画出正规式相应的NFA M状态图,如下图所示。
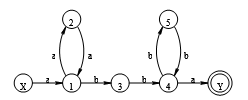
用子集法构造状态转换矩阵,如下表所示。

将状态分为终态集{Y}和非终态集{X,1,2,3,4,5}
因为{X,1,2,3,4,5}a={1,2,1,,Y,}
所以非终态集分为{X,1,2},{3,5},{4}
因为{X,1,2}b={,3,},所以分为
最后得到集合{X,2},{1},{3,5},{4},{Y}重新命名为1,2,3,4,5得到最小化的DFA M′状态转换矩阵和状态转换图如下图所示。
(注意:本题由于集合的命名和先后顺序不同,可能最终结果不同。) - 试构造下述文法的SLR(1)分析表。
G[A]: A→aABl|a
B→Bb|d
解:拓广文法
(0)S→A
(1)A→aABl
(2)A→a
(3)B→Bb
(4)B→d
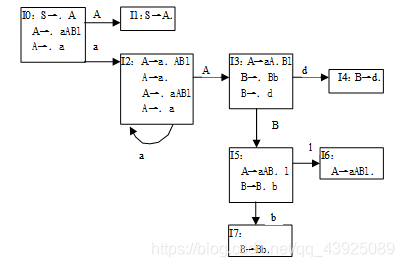
First(A)={a}follow(A)={#,d}
First(B)={d}follow(B)={l}
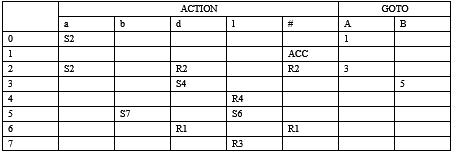
SLR(1)分析表如下:
- 画出编译程序的总体结构图,简述各部分的主要功能。
解:编译程序的总体框图如下所示:
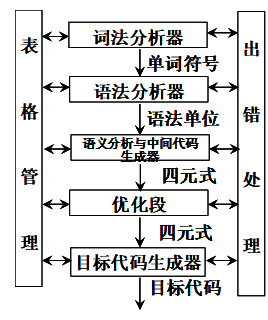
(1)词法分析器,又称扫描器,它接受输入的源程序,对源程序进行词法分析,识别出一个个单词符号,其输出结果是二元式(单词种别,单词自身的值)流。
(2)语法分析器,对单词符号串进行语法分析(根据语法规则进行推导或归约),识别出程序中的各类语法单位,最终判断输入串是否构成语法上正确的句子。
(3)语义分析及中间代码生成器,按照语义规则对语法分析器归约出(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间代码。编译程序可以根据不同的需要选择不同的中间代码形式,有的编译程序甚至没有中间代码形式,而直接生成目标代码。
(4)优化器对中间代码进行优化处理。一般最初生成的中间代码执行效率都比较低,因此要做中间代码的优化,其过程实际上是对中间代码进行等价替换,使程序在执行时能更快,并占用更小的空间。
(5)目标代码生成器,把中间代码翻译成目标程序。中间代码一般是一种与机器无关的表示形式,只有把它再翻译成与机器硬件直接相关的机器能识别的语言,即目标程序,才能在机器上运行。
(6)表格管理模块保持一系列的表格,登记源程序的各类信息和编译各阶段的进展状况。编译程序各个阶段所产生的中间结果都记录在表格中,所需要的信息也大多从表格中获取,整个编译过程都在不断和表格打交道。
(7)出错处理程序对出现在源程序中的错误进行处理。如果源程序有错误,编译程序应设法发现错误,把有关错误信息报告给用户。编译程序的各个阶段都有可能发现错误,出错处理程序要对发现的错误进行处理、记录,并反映给用户。 - 对于文法G(S):
S → (L) | aS | a
L → L, S | S
(1) 画出句型(S, (a))的语法树。
(2) 写出上述句型的所有短语、直接短语和句柄。
解:
(1) 句型(S, (a))的语法树如下图所示:
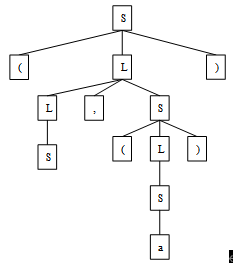
(2) 从语法树中可以找到(3分)
短语:a; (a); S; S,(a); (S, (a))
直接短语: a; S
句柄: S - 构造一文法,使其描述的语言L = {ω |ω ∈ (a, b)*,且ω中含有相同个数的a和b}。
解:
S→ ε| aA|bB
A→ b| bS| aAA
B→ a| aS| bBB - 分别给出表达式 –(a*(b-c))+d 的逆波兰表示和四元式表示。
解:
(1)逆波兰式: abc-*@d+ 其中使用@代表一目减运算
(2)四元式:
① (-, b, c, T1)
② (*, a, T1, T2)
③ (@, T2, _, T3)
④ (+, T3, d, T4)
- 把下列语句翻译为四元式序列:
while (A > B)
if (C > D)
X = Y * Z
else
X = Y + Z
解:
(1) (j>, A, B, 3)
(2) (j, _, _, 11)
(3) (j>, C, D, 5)
(4) (j, _, _, 8)
(5) (*, Y, Z, T1)
(6) (=, T1, _, X)
(7) (j, _, _, 1)
(8) (+, Y, Z, T2)
(9) (=, T2, _, X)
(10) (j, _, _, 1)
(11)
-
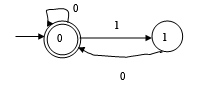
构造一个DFA,它接受Σ = {0, 1}上所有满足如下条件的字符串:每个1后面都有0直接跟在右边。
解:
(1)0*(0|10)0 或者 (0|10)*
(2)
①NFA (2分)
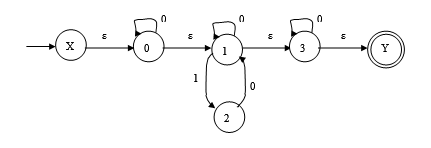
②子集法确定化
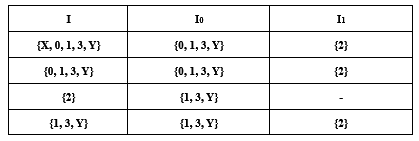
重新命名状态,即得:
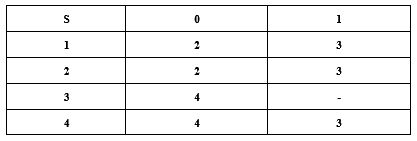
③ 最小化
首先分为终态集和非终态集 {3} {1, 2, 4} 因为10 = 2 20 = 2 40 = 4 状态均属于集合{1, 2, 4},所以对于输入符号0不能区分开1,2,4三个状态;11 = 3 21 = 3 41 = 3状态均属于集合{3},所以对于输入符号1也不能区分开1,2,4三个状态;因此最终的状态划分即为: {3} {1, 2, 4},其对应的DFA如下图所示:
-
已知文法G(S):
S→S*aP| aP| *aP
P→+aP| +a
(1) 将文法G(S)改写为LL(1)文法G’(S);
(2) 写出文法G’(S)的预测分析表。
解:(1)消除左递归,文法变为:
S→aPS’| *aPS’
S’→ aPS’ | ε
P→+aP| +a
提取公共左因子,文法变为G’(S):
S→aPS’| *aPS’
S’→ aPS’ |ε
P→+aP’
P’→P| ε
(2)计算每个非终结符的FIRST集和FOLLOW集:
FIRST(S) = {a, }
FIRST(S’) = {, ε}
FIRST§ = {+}
FIRST(P’) = {+, ε}
FOLLOW(S) = {#}
FOLLOW(S’) = {#}
FOLLOW§ = {, #}
FOLLOW(P’) = {, #}
构造该文法的预测分析表如下: (5分)

-
已知文法G(S):
S→aS | bS | a
(1) 构造识别该文法所产生的活前缀的DFA;
(2) 判断该文法是LR(0)还是SLR(1),并构造所属文法的LR分析表。
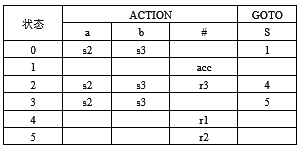
解:
(1)将文法G(S)拓广为G’(S’):
(0) S’→S
(1) S→aS
(2) S→bS
(3) S→a
识别该文法所产生的活前缀的DFA:
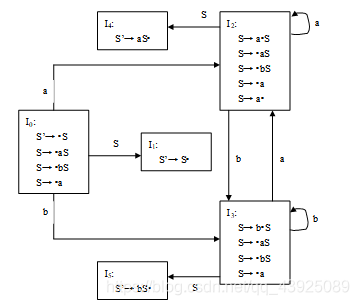
(2)在状态I2存在“移近-归约”冲突,因此该文法不是LR(0)文法。
计算S的FOLLOW集合:
FOLLOW(S)= {#}
I2中的冲突用FOLLOW集合可以解决,所以该文法是SLR(1)文法。
构造SLR(1)分析表如下:
-
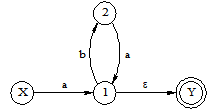
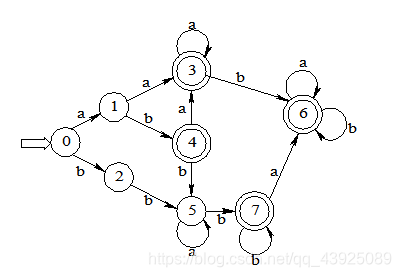
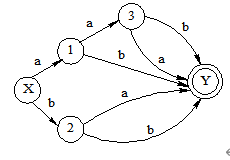
将下图所示的非确定有限自动机(NFA)变换成等价的确定有限自动机(DFA)。其中,X为初态,Y为终态。
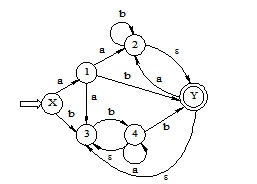
【解】 用子集法将NFA确定化,如图所示。
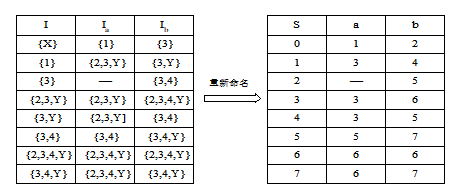
确定化的DFA如下图所示:
-
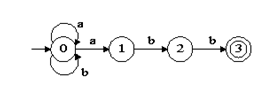
对正规式(a|b)*abb构造其等价的NFA。
【解】
-
下面的文法产生0和1的串,即二进制的正整数,请给出决定每个二进制数的值(十进制形式)的语法制导定义。
【解】定义值属性为.val,翻译方案如下:
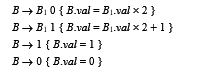
-
把算术表达式-(a + b)x(c + d) + (e+ f) 翻译成等价的四元式序列(序号从0开始)。
【解】
0(+,a, b ,T1)
1(uminus,T1,-,T2)
2(+,c, d , T3)
3(*,T2,T3,T4)
4(+,e,f,T5)
5(+,T4,T5,T6)
-
设有文法G[S]:

试给出句子(a,a,a)的最左推导。
【解】(1) (a,a,a)的最左推导
S=>(T) =>(T,S) =>( T,S,S) =>( S,S,S) =>(a,S,S) =>(a,a,S) =>(a,a,a) -
已知文法G: S → ( L | a
L → S , L | )
判断是不是LL(1)文法,如果是请构造文法 G 的预测分析表,如果不是请说明理由。
【解】
1)求各非终结符的 FISRT 集和 FOLLOW 集:
= { (, a )
FIRST(L) = { a } FIRST(S) = { (, ), a }
FOLLOW(S) = {, # }
FOLLOW(L) = FOLLOW(S) ={ , # }
FIRST(( L)∩{a}=Φ
FIRST(S , L)∩{)}=Φ
所以是LL(1)文法
2)预测分析表:

-
文法
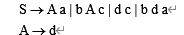
构造识别活前缀的DFA。请根据这个DFA来判断该文法是不是SLR(1)文法并说明理由。
【解】
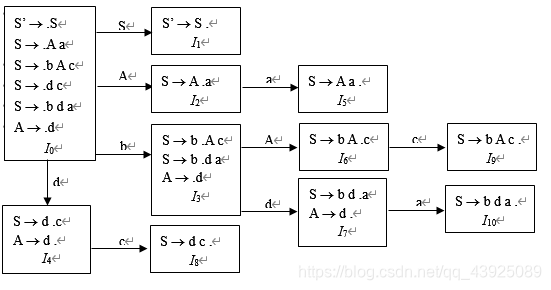
Follow(S)={#}
Follow(A)={a,c}
I4存在冲突且Follow(A)∩{c}={ c}
I7存在冲突且Follow(A)∩{a}={ a}
所以不是SLR(1)文法 -
将下图所示的确定有限自动机(DFA)最小化。其中,X为初态,Y为终态。
【解】 先划分为终态集{Y}和非终态集I={X,1,2,3}
X面对输入符号b时下一状态属于I,而1,2,3面对输入符号b时下一状态属于{Y},故划分为{X}、{1,2,3}
非终态2和非终态3面对输入符号a的下一状态相同,而1不同,即最简状态{X}、{1}、{2,3}、{Y}。按顺序重新命名为0、1、2、3,则得到最简DFA,
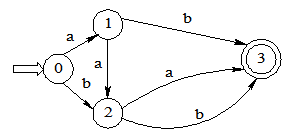
-
请画出识别无符号十进制整数的状态转换图
【解】
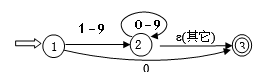
-
设有文法G[S]:
S→SS|S+S|(S)|i
该文法是否为二义文法,并说明理由?
【解】该文法是二义文法,因为该文法存在句子ii+i,该句子有两棵不同的语法树如图所示。
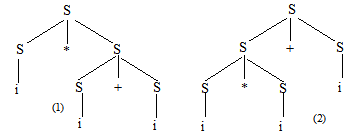
-
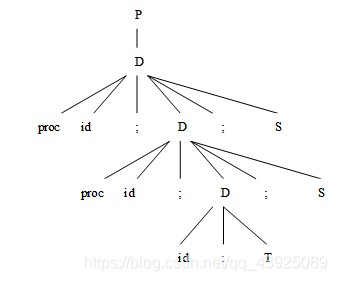
程序的文法如下:
P → D
D → D;D | id : T | proc id; D; S
写一语法制导定义,打印该程序一共声明了多少个id
【解】 属性num表示id个数
P → D print(D.num)
D → D(1);D(2) D.num = D(1).num + D(2).num
D → id : T D.num = 1
D → proc id; D(1); S D.num = D(1).num + 1
例:proc id; proc id; id : T; S; S(从语法树分析入手)
(注意:本例只是帮助学生理解题意,不是答案部分)
- 把下列语句翻译为四元式序列(四元式序号从1开始):
while (A > B)
if (C > D)
X = Y * Z
else
X = Y + Z
【解】(1) (j>, A, B, 3)
(2) (j, _, _, 11)
(3) (j>, C, D, 5)
(4) (j, _, _, 8)
(5) (*, Y, Z, T1)
(6) (=, T1, _, X)
(7) (j, _, _, 1)
(8) (+, Y, Z, T2)
(9) (=, T2, _, X)
(10) (j, _, _, 1)
(11)
- 构造下面文法的LL(1)分析表。

【解】
FIRST(T)={ int real } FOLLOW(T)={ id }
FIRST(L)={ id } FOLLOW(L)={ #}
FIRST(R)={ , } FOLLOW( R )={ #}
FIRST(D)={ int real } FOLLOW(D)={#}
因为FIRST(int)∩FIRST(real)=Φ
FIRST(, id R)∩FOLLOW( R )=Φ
所以是LL(1)文法,LL(1)分析表如下:

42. 给定文法S→aS|bS|a,下面是拓广文法和识别该文法所产生的活前缀的DFA。判断该文法是否是SLR(1)文法:如果是构造其SLR(1)分析表,如果不是请说明理由。
(1)将文法G(S)拓广为G(S’):
(0)S’→S
(1)S→aS
(2)S→bS
(3)S→a
(2)识别该文法所产生的活前缀的DFA如图1所示。
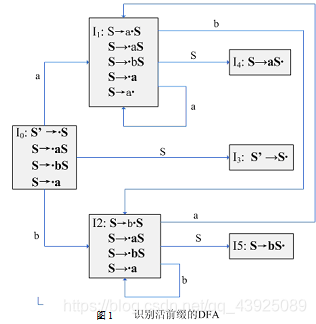
【解】注意到状态I1存在“移进-归纳”冲突,计算S的FOLLOW集合:
FOLLOW(S)={#}
{a}∩{b}∩FOLLOW®=Φ
可以采用SLR冲突消解法,得到如下的SLR分析表。
从分析表可以看出,表中没有冲突项,所以该文法是SLR(1)文法。
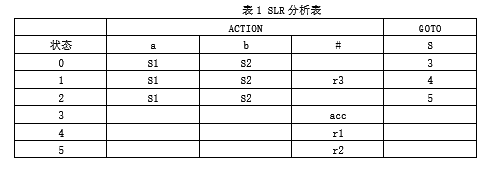
-
给出表达式-ab+bc+d/e的语法树和三元式序列。
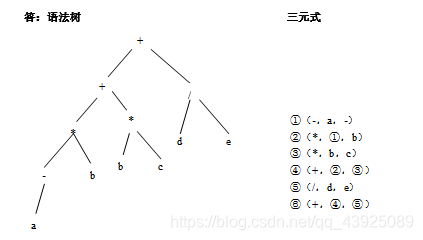
-
证明下面文法S→AaAb|BbBa A→ε B→ε,是LL(1)文法,但不是SLR(1)文法。
证明:
(1)first(AaAb)={a} first(BbBb)={b} ,有first(AaAb)∩first(BbBb)=Φ
所以根据LL(1)文法的定义,该文法是LL(1)文法。(2分)
(2)为了构造识别活前缀的DFA,初态集包含如下四个项目:S→.AaAb S→.BbBa A→. B→.
但该项目中有两个可归约项目:A→. B→.,产生归约-归约冲突,而follow(A)={a,b},follow(B)={a,b},有follow(A)∩follow(B)≠Φ,所以使用向前看一个终结符的方法不能解决此冲突,所以该文法不是SLR(1)文法。(3分) -
现有文法G[S]
S→a|ε|(T)
T→T,S|S
请给出句子(a,(a,a))的最左、最右推导,并指出最右推导中每一个句型的句柄。
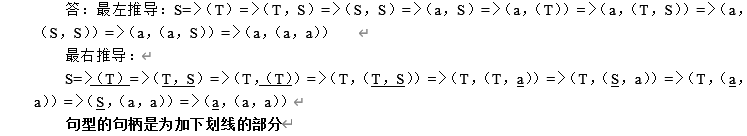
-
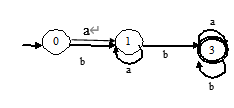
将下图的DFA最小化。
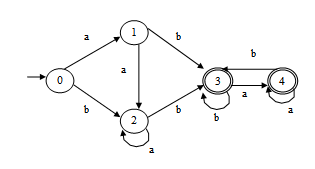
答:初始划分:II={{0,1,2},{3,4}}(1分)
(1)考查{0,1,2},1和2接受a,b后都转向相同的状态,且接受b后转向终态,而0接受b后转向非终态2,所以0与1,2可分,IInew={{0},{1,2},{3,4}}(1分)
(2)考查{3,4},接受a,b后都转向相同的状态,所以3,4不可分。IInew={{0},{1,2},{3,4}}(1分)
将1,2合并用1代表,3,4合并用3代表,最终的最小化DFA如下:
-
设有如下文法:P→D
D→D;D|id:T|proc id;D;
T→real|integer
给出一个语法制导定义,打印该程序一共声明了多少个id。
答:
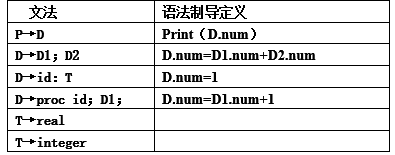
-
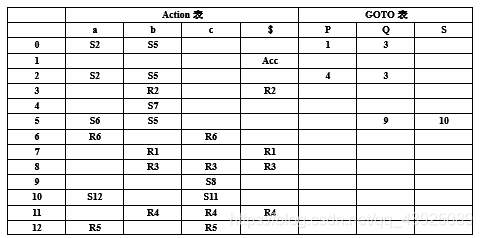
识别文法G的活前缀的DFA如下图所示,补充完成状态I2和I5,然后根据该图构造SLR(1)分析表。
G:(0) P’→P (1) P→aPb (2) P→Q (3) Q→bQc
(4) Q→bSc (5) S→Sa (6) S→a
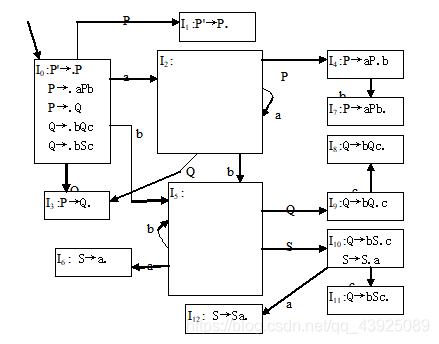
答:I2,I5分别如下图所示:

Follow(P)={b,$} 1分
Follow(Q)={ b,c,$} 1分
Follow(S)={c,a} 1分
SLR(1)分析表:
-
给出表达式(a+b)*(c+d/e)的语法树和四元式序列。
答:
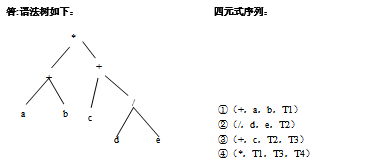
-
构造文法S→AaAb|BbBa A→ε B→ε,的预测分析表。
答:first(S)={a,b},First(AaAb)={a},First(BbBa )={b}
Follow(A)={a,b}
Follow(B)={a,b}

-
写出C语言标识符集(字母或下划线开头的由字母、数字、下划线构成的串)的正规式。
解答:用D表示数字0-9,用L表示字母a-z|A-Z,则C语言标识符的正规式为:
(L|)(L|D|)*
52.有一语法制导定义如下,其中+表示符号连接运算:
S→B print B.vers
B→a B.vers=a
B→b B.vers=b
B→Ba B.vers=a+B.vers
B→Bb B.vers=b+B.vers
若输入序列为abab,且采用自底向上的分析方法,则输出序列为(_baba)。
用分析树表示求解过程。
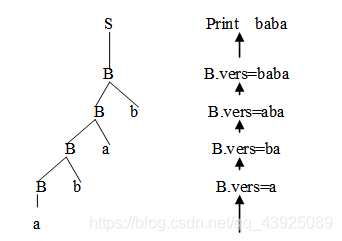
-
假设第一个四元式的序号是100,写出布尔表达式a<b∨c∧d>e的四元式序列。
100 (j<, a, b, 106)
101 (j, _, _ , 102)
102 (jnz, c, _ ,104)
103 (j,_ ,_ ,q)
104 (j>,d, e, 106)
105 (j,_ , _ , q )
T:106
……
F:q
…….
- 设有如下文法:
G[E]:E→EWT|T
T→T/F|F
F→(E)|a|b|c
W→+|-
证明符号串a/(b-c)是句子。
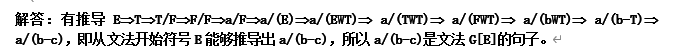
- 对于下列文法
G[S]: S→Sb|bA
A→aA|a
(1)构造一个与G等价的LL(1)文法G′。
(2)对于文法G′,构造相应的LL(1)分析表。
解:(1)(5分)
G′:S→bAS′
S′→b S′|ε
A→aA′
A′→A|ε
(2)(1分)
FIRST(S)={ b }
FIRST(S′)={ b,ε}
FIRST(A)={a}
FIRST(A′)={a,ε}
FOLLOW(S)={#}
FOLLOW(S′)={#}
FOLLOW(A)={b,#}
FOLLOW(A′)=(b,#)
LL(1)分析表:
| 空 | a | b | # |
|---|---|---|---|
| S | S→bAS′ | ||
| S′ | S′→b S′ | S′→ε | |
| A | A→aA′ | ||
| A′ | A′→A | A′→ε | A′→ε |
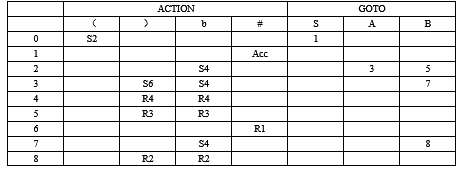
- 构造下述文法的SLR(1)分析表。
G[S]:S→(A)
A→ABB|B
B→b
解:拓广文法:(1分)
S′→S (0)
S→(A) (1)
A→ABB (2)
A→B (3)
B→b (4)
识别活前缀的DFA:(4分)
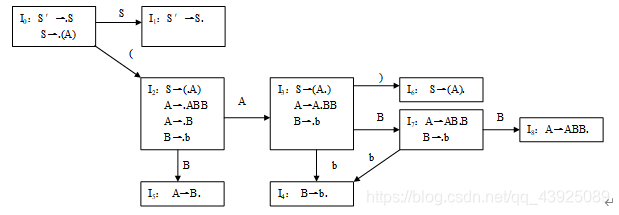
FIRST集和follow集:(1分)
First(S)={(,c} follow( S)={#}
First(A)={b} follow(A)={b,)}
First(B)={b} follow(B)={b,)}
SLR(1)分析表:(4分)
- 有一语法制导定义如下:
S→bAb print “1”
A→(B print “2”
A→a print “3”
B→aA) print “4”
若输入序列为b(a(a(aa)))b,且采用自下而上的分析方法,则输出序列为(34242421__)。
- 写出赋值语句X= -(a+b)/(c-d)-(a+b*c)的逆波兰表示。
Xab±cd-/abc*±= - 为文法
G[S]:S→(L)|a
L→L,S|S
写一语法制导定义,它输出句子中括号嵌套的最大层次数。
解: 使用num属性描述括号的嵌套最大层次数
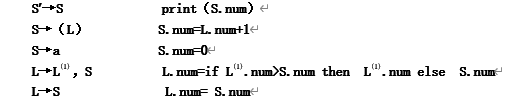 每个式子1分。
每个式子1分。 - 设有文法G[S]:
S→aAcB|Bd
A→AaB|c
B→bScA|b
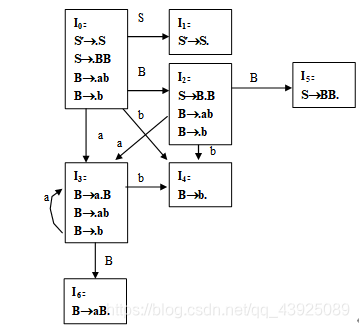
该文法句型aAcbBdcc的句柄是_______Bd_____________。 - 已知文法G[S]如下:构造该文法的LR(0)分析表。
G[S]:S→BB
B→aB|b
解:拓广文法:(1分)
识别活前缀的DFA 如下:
LR(0)分析表如下: