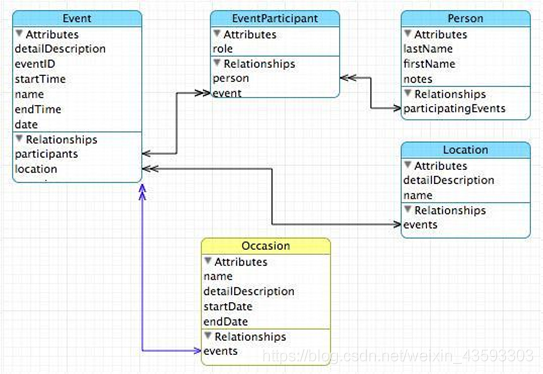
本章的引入:这是一个开发数据库的schema,表面上看可能十分复杂,但实际上它是由许许多多的table以及若干column以及连接构成的。这就是数据模型。
知识点1:构建数据模型(data model)的基本准则
不要放相同的字符串数据两次,应该新建一个表格并用关系进行连接,这一点之后会详细解释。
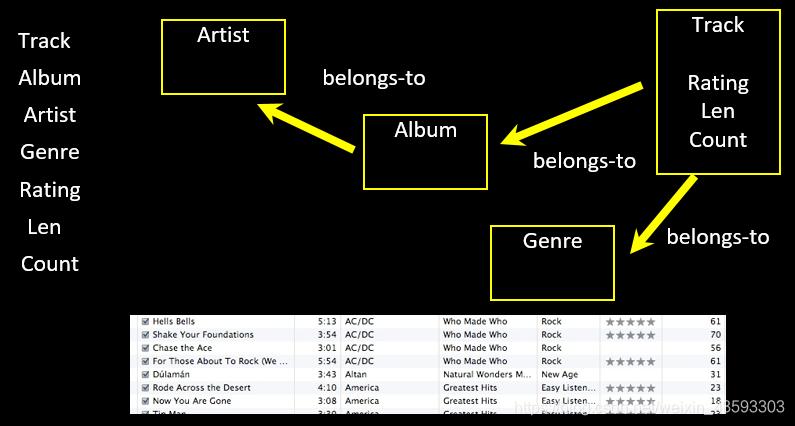
以上就是“我们的小公司”在做音乐APP数据库之间数据建模的过程。
知识点2:在表中表示数据模型(Representing a Data model in Tables)

主要由Table(表格)、Primary key(主键)、Logical key(逻辑键)和Foreign key(外键)组成,外键可能有不止一个。根据图中的对应关系,一般来说,主键id就是别的表格指向的点,外键是某个表格指向别的表格的起始点。逻辑键可以理解为用于查找该行的指标依据,可以简化理解为查找搜索功能,因此在编写数据库的时候,我们可能会用上WHERE加上逻辑键的方法。
以下展示一个完整的数据模型,同样以音乐软件为例:
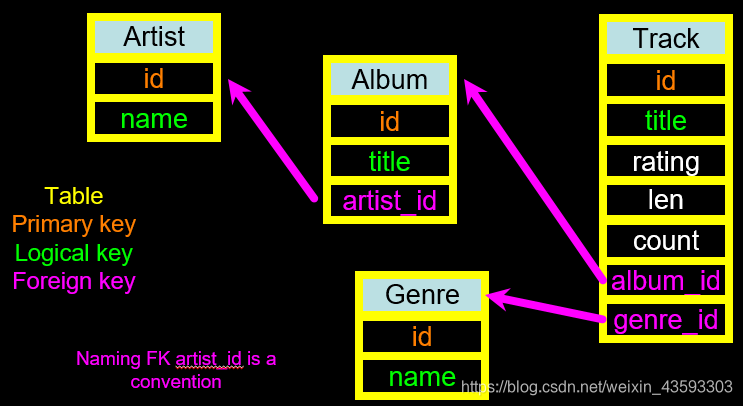
在SQLite当中构建数据库:
CREATE TABLE "Artist" (
"id" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
"name" TEXT
);
CREATE TABLE Genre (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE, #这是赋予数字并自动递增的含义
name TEXT
);
CREATE TABLE Album (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT
);
CREATE TABLE Track (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
title TEXT,
album_id INTEGER,
genre_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);
分别是创建数据库的几个指令,需要注意的是NN\PK\AL\U的意思分别是:
- NN代表不是空值
- PK代表这是一个主键
- AL代表自动递增,程序员没有指定这个值,但是它会自动赋特定的值,1,2,3,4,5递增
- U代表无符号
此外还需要注意的是创建Table的顺序,一般都是从外向里创建,从叶子往枝丫创建,所以这里的顺序是Artist>Genre>Album>Track。
知识点2:在建的表中插入数据
例如要在Artist的表格中插入数据,使用如下的执行语句:
insert into Artist (name) values ('Led Zepplin');
insert into Artist (name) values ('AC/DC')
执行后的结果如下图所示:
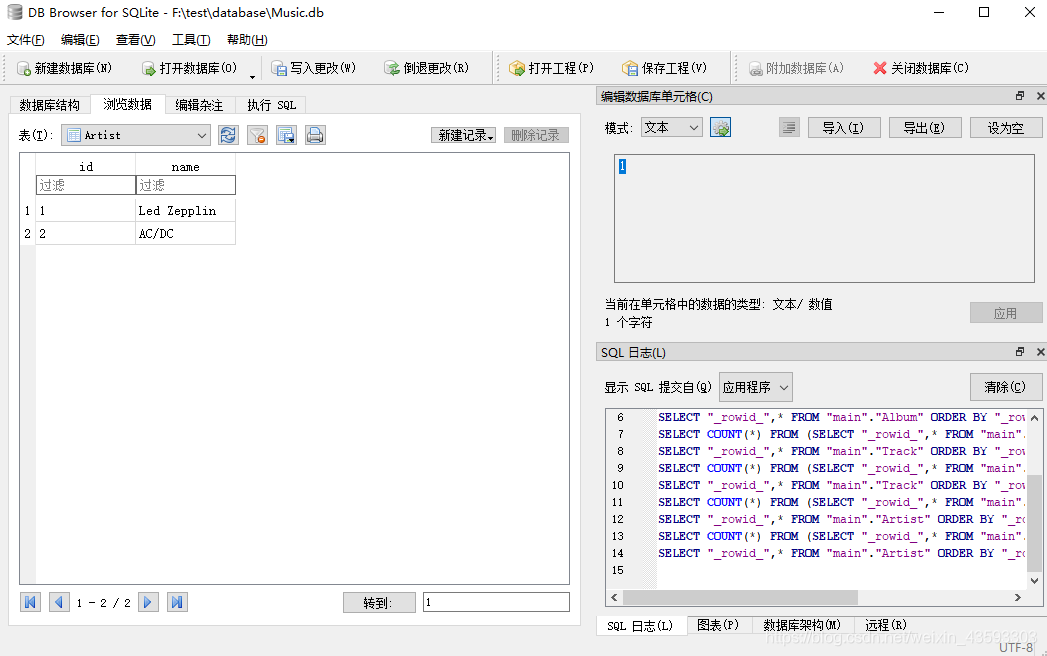
采用这两行sql的代码主要有两个用处,一方面是将数据插入到了Artist之中,另一方面是给每一个数据都赋予了一个id(自动递增的1、2、3…)
接下来添加Genre表的数据,具体sql代码如下所示:
insert into Genre (name) values ('Rock');
insert into Genre (name) values ('Metal')
接下来添加Album表的数据,这个表示首次牵涉到foreign key的表格,具体sql代码如下所示:
insert into Album (title, artist_id) values ('Who Made Who', 2);
insert into Album (title, artist_id) values ('IV', 1)
执行后的结果如下图所示:
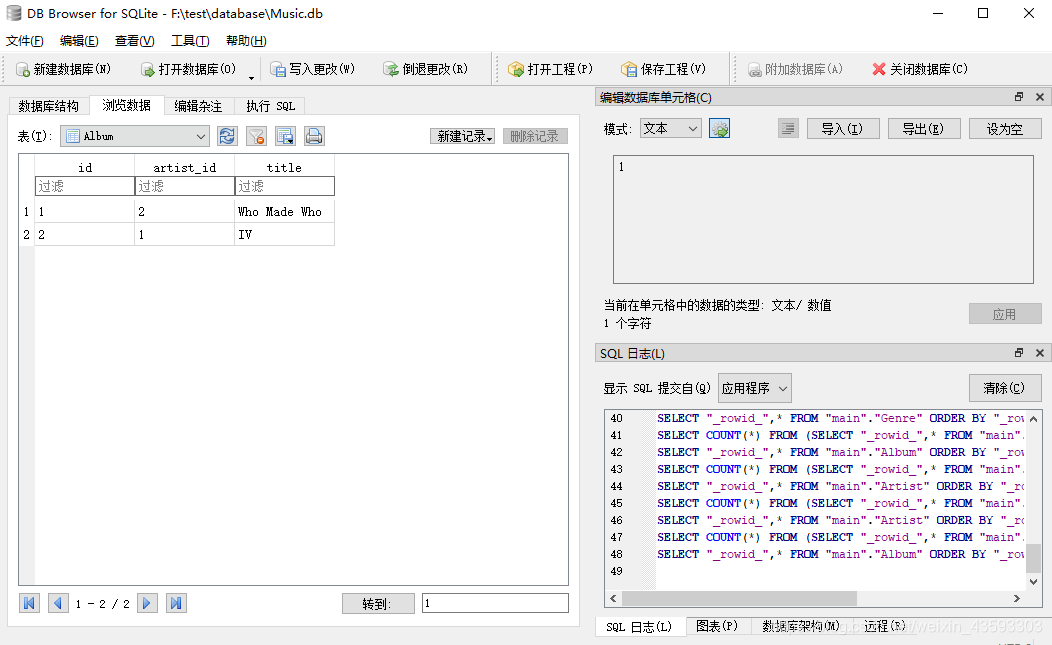
由于Genre的foreign key是指向Artist的,所以这里会有artist_id的外键,表示与作者之间的对应关系。

接下来添加Track的数据,这里有两个外键,具体的sql执行语句如下所示:
insert into Track (title, rating, len, count, album_id, genre_id)
values ('Black Dog', 5, 297, 0, 2, 1);
insert into Track (title, rating, len, count, album_id, genre_id)
values ('Stairway', 5, 482, 0, 2, 1);
insert into Track (title, rating, len, count, album_id, genre_id)
values ('About to Rock', 5, 313, 0, 1, 2);
insert into Track (title, rating, len, count, album_id, genre_id)
values ('Who Made Who', 5, 207, 0, 1, 2)
知识点3:用JOIN重建数据
JOIN是sql语言中的一个功能,简单形容其功能就是:
- JOIN操作作为选择操作的一部分可跨多个表进行连接;
- 必须需要告诉JOIN如何通过使用ON子句在表之间建立连接
下面通过举例来进行说明:
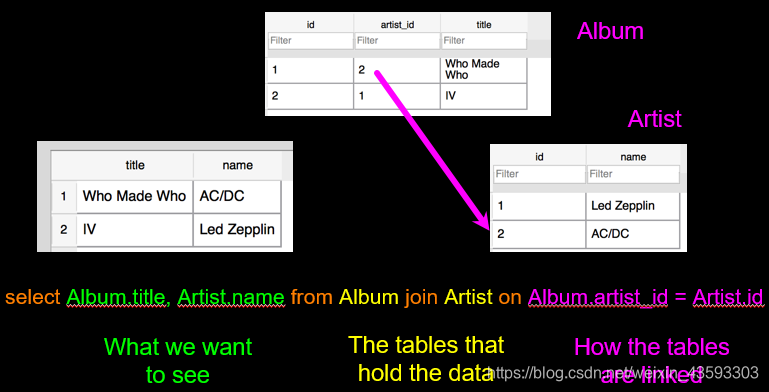
在这个例子当中,我们想要选中两列,一列是Album表格中的title,一列是Artist表格中的name,所以可以用如下的代码进行选取:
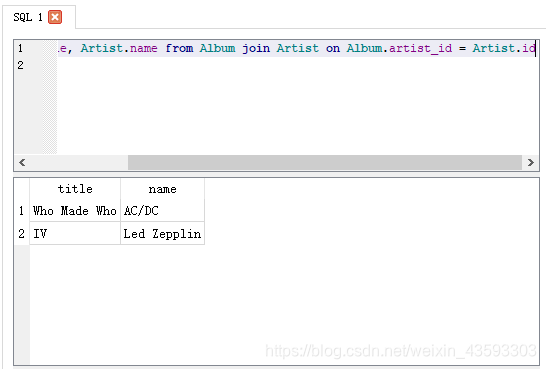
select Album.title, Artist.name from Album join Artist on Album.artist_id = Artist.id
从代码中可以看出,这一段代码包含三块内容,分别是:
- 我们想要选取的部分;
- 想要选取的部分所在的表格;
- 相应表格之间的连接关系。
执行结果如下图所示:
接下来剖析其中的关系:
select Album.title, Album.artist_id, Artist.id,Artist.name
from Album join Artist on Album.artist_id = Artist.id
如果执行以上这一条语句得到的结果是:
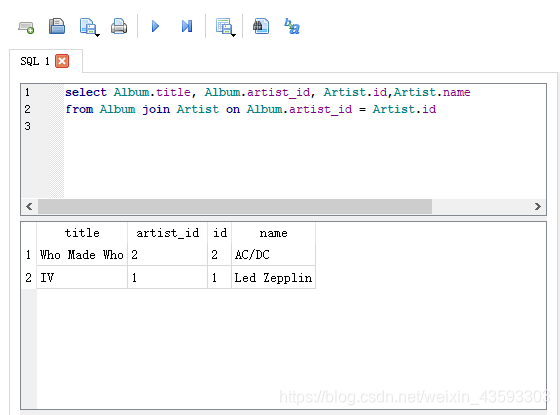
这个结果其实是对上一条代码的剖析,显示了两个表格块连接的过程,之所以能够那样显示,是因为外键与主键之间的对应关系。
再举一个例子:
select Track.title, Genre.name from Track join Genre on Track.genre_id = Genre.id
执行后的结果为:
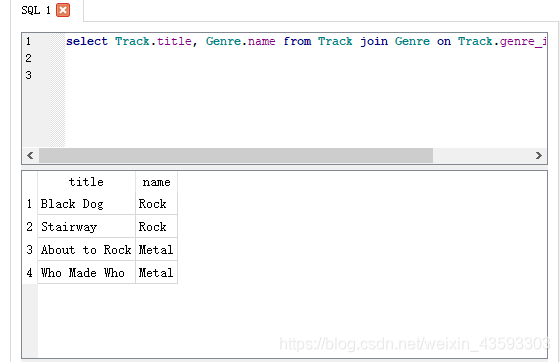
做一个有趣的小实验,如果只执行一下这段代码:
select Track.title, Genre.name from Track join Genre
也就是说,如果不加on后面的外键与主键的连接关系,那么程序执行后的结果为:
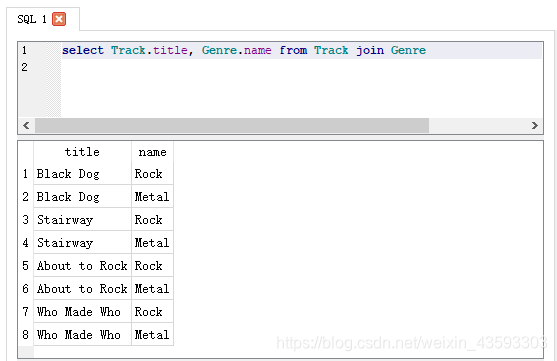
缺少了对应关系,结果显示就是一个简单的组合叠加,就没有匹配关系了,同样剖析其原因,结果如下图所示:
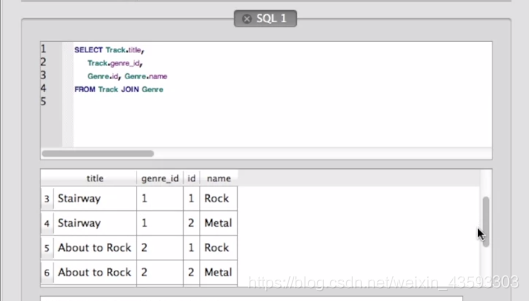
所以总结一下:on的作用就是筛掉所有组合中不匹配的,抓取匹配的条目进行输出。
让工作更复杂一些,将所有的内容整合到一起:

执行以下代码:
select Track.title, Artist.name, Album.title, Genre.name from Track join Genre join Album join Artist on Track.genre_id = Genre.id and Track.album_id = Album.id and Album.artist_id = Artist.id
输出结果如上图所示,在on语句中,不同的连接关系之间用and来相连。
截止目前,我们成功重构了数据模型,重构后的结果也就是展现在用户面前的界面了。
在work example当中有需要注意的是:
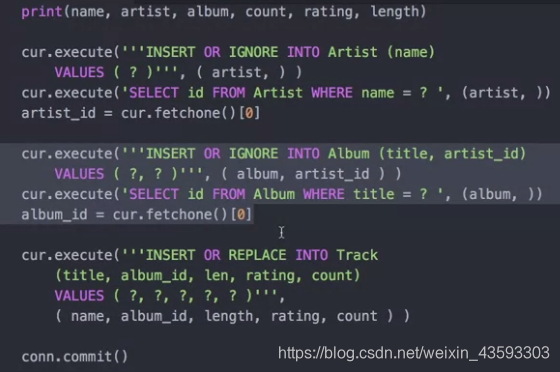
在图中,INSERT OR REPLACE和INSERT OR IGNORE这种写法是插入要么更新,插入要么替代,这种写法在官方SQL当中是没有的,但是在SQLite当中是存在的。
