数据模型在djangoTestApp/models.py文件中定义表和表结构,之前已经定义了一个Student表,如下:
from django.db import models SEX_CHOICE = ( ('F','Female'), ('M','male') ) # Create your models here. class Student(models.Model): No = models.CharField('学号',max_length = 10) Name = models.CharField('姓名',max_length = 20) Sex = models.CharField('性别',max_length = 1,choices = SEX_CHOICE,default = 'M') Age = models.IntegerField('年龄')
字段类型主要有以下几种:
CharField:字符型
IntergerField:整型
DateField:日期型
DateTimeField:日期时间型
FloatField:浮点型
BooleanField:布尔型
BigIntergerField:大数据型
FileField:文件类型
...
当然类型也可以自定义
数据表创建好后在命令行中使用如下语句写入数据库:
python manage.py makemigrations
python manage.py migrate
命令行中输入如下命令可以进入数据库操作界面:
D:\PycharmProjects\untitled\MyTestProject\djangoTestPro>python manage.py shell
>>> from djangoTestApp import models
一、增加操作
在django中增加有如下4种方式:
1、直接使用create增加
>>>models.Student.objects.create(No='19001',Name='watertaro',Sex='M',Age=30)
2、先创建一个对象再保存
>>>p = models.Student(No='19002',Name='Mark',Sex='F',Age=27) >>>p.save
3、先创建一个对象,给对象的参数赋值后再保存
>>> p = models.Student() >>> p.No='19005' >>> p.Name='WangWU' >>> p.Sex='M' >>> p.Age=35 >>> p.save()
4、查看和增加,不存在则增加,存在则查询
>>> models.Student.objects.get_or_create(No='19006',Name='LiLiu',Sex='F',Age=21) (<Student: No:19006;Name:LiLiu;Sex:F;Age:21>, True)
返回一个元祖,第一个表示对象,第二个参数True表示新增,False表示查询
再次执行上述命令则返回的第二个参数为False(已经执行过一次,表示已经存在数据了)
二、查询操作
get()方法:
>>> models.Student.objects.get(No='19003') <Student: Student object (5)>
这里只显示查到了数据,可以使用__dict__(这里是俩个下划线)来查看(返回的是一个字典)
>>> models.Student.objects.get(No='19002').__dict__ {'_state': <django.db.models.base.ModelState object at 0x00000000041AD940>, 'id: 4, 'No': '19002', 'Name': 'Mark', 'Sex': 'F', 'Age': 27} >>> s = models.Student.objects.get(No='19002') >>> s.__dict__ {'_state': <django.db.models.base.ModelState object at 0x00000000041AD438>, 'id: 4, 'No': '19002', 'Name': 'Mark', 'Sex': 'F', 'Age': 27}
也可以在数据模型的类(即Student类)中增加一个__str__的返回值:
def __str__(self): return 'No:' + self.No + ';Name:' + self.Name + ';Sex:' + self.Sex + ';Age:' + str(self.Age)
使用exit()退出shell再重新进入,再次查询如下:
>>> models.Student.objects.get(No='19003') <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>
get()方法只能查询到有且只有一条数据的对象,如果没有查询到或者查询结果不止一条会报错,后面会讲到可以查询N条数据方法(filter)
all()方法
可以查询表中所有数据,如下:
>>> models.Student.objects.all()
<QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student:No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19006;Name:LiLiu;Sex:F;Age:21>]>
若只是查询前2条数据,可以使用类似列表中切片方法来查询(这里切片不支持负数)
>>> models.Student.objects.all()[:2]
<QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19002;Name:Mark;Sex:F;Age:27>]>
如果只需要显示Name,可以按照如下操作:
>>> t = models.Student.objects.all() >>> item = models.Student.objects.all() >>> for i in item: ... print(i.Name) ... watertaro Mark ZhangSan LiSi WangWU
filter()方法:
filter可以查询出多条或者空数据,这也是查询中使用最多的方法,下面介绍使用方法
1、精确查询(__exact)和不区分大小写的精确查询(__iexact)
>>> models.Student.objects.filter(No='190')#查询为空 <QuerySet []> >>> models.Student.objects.filter(No='19001')#查询到一条数据 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>]> >>> models.Student.objects.filter(Age=30)#查询到多条数据 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>]>
也可以使用No__exact(双下划线)来精确查询和直接查询的效果是一样的,如下:
>>> models.Student.objects.filter(No__exact='190')#查询为空 <QuerySet []> >>> models.Student.objects.filter(No__exact='19001')#查询到一条数据 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>]> >>> models.Student.objects.filter(Age__exact=30)#查询到多条数据 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>]>
之前Name中有watertaro,增加一个WaterTaro这个Name:
>>> models.Student.objects.create(No='19007',Name='WaterTaro',Sex='F',Age=29) <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>
这时使用如下查询语句可以看到后一个查询语句不区分大小写,但是精确匹配的:
>>> models.Student.objects.filter(Name='WaterTaro') <QuerySet [<Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]> >>> models.Student.objects.filter(Name__exact='WaterTaro') <QuerySet [<Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]> >>> models.Student.objects.filter(Name__iexact='WaterTaro') <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]>
3、包含某个字段的查询(__contains和__icontains)
>>> models.Student.objects.filter(Name__contains='watertaro') <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]> >>> models.Student.objects.filter(Name__icontains='watertaro') <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]>
老版本中__contains是区分大小写的,最新django不区分
4、正则表达式查询(__regex)和不分区大小写的正则表达式查询(__iregex)
我们增加一个Name为LuTao的同学:
>>> models.Student.objects.create(No='19008',Name='LuTao',Sex='F',Age=25)
<Student: No:19008;LuTao;Sex:F;Age:25>
此时查询以u结尾的名字
>>> models.Student.objects.filter(Name__regex='u$') <QuerySet [<Student: No:19006;Name:LiLiu;Sex:F;Age:21>]>
只能查到LiLiu,其实包含u和U的名字还有LuTao和WangWU,如果使用下面的语句,则可以查到LiLiu和WangWU
>>> models.Student.objects.filter(Name__iregex='u$') <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19006;Name:LiLiu;Sex:F;Age:21>]>
5、大于(gt)、大于等于(gte)、小于(lt)、小于等于(lte)
看下面查询的例子:
>>> models.Student.objects.filter(Age__gt=30)#查询Age大于30 <QuerySet [<Student:No:19005;Name:WangWU;Sex:M;Age:35>]> >>> models.Student.objects.filter(Age__gte=30)#查询Age大于等于30 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>]> >>> models.Student.objects.filter(Age__lt=29)#查询Age小于29 <QuerySet [<Student: No:19002;Name:Mark;Sex:F;Age:27>]> >>> models.Student.objects.filter(Age__lte=29) #查询Age小于等于29 <QuerySet [<Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]>
6、以某字段开始(startswith)、以某字段结束(endswith)
>>> models.Student.objects.filter(Name__startswith='wa')#以wa开始的Name(不区分大小写) <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]> >>> models.Student.objects.filter(Name__endswith='n')#以n结尾的Name(不区分大小写) <QuerySet [<Student: No:19003;Name:ZhangSan;Sex:F;Age:30>]>
7、与(&)、或(|)
>>> models.Student.objects.filter(Age=30) & models.Student.objects.filter(Sex='F')#查询Age=30并且Sex为F <QuerySet [<Student: No:19003;Name:ZhangSan;Sex:F;Age:30>]> >>> from django.db.models import Q >>> models.Student.objects.filter(Q(Age=30) & Q(Sex='F'))#等同于上面查询 <QuerySet [<Student: No:19003;Name:ZhangSan;Sex:F;Age:30>]> >>> models.Student.objects.filter(Age=30) | models.Student.objects.filter(Age=35)#查询Age为30或者35 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>]> >>> models.Student.objects.filter(Q(Age=30)|Q(Age=35))#等同于上面查询 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>]>
8、查询集中的第一条数据(first())、查询集中的最后一条数据(last())
>>> models.Student.objects.all()#查询所有 <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student:No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]> >>> models.Student.objects.all().first()#获取第一条数据 <Student: No:19001;Name:watertaro;Sex:M;Age:30> >>> models.Student.objects.all().last()#获取最后一条数据 <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>
exclude()方法:
exclude是排除方法,即查询到的是排除给出的条件,比如我们要查询不带u的Name
>>> models.Student.objects.exclude(Name__contains='u') <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]>
查询结果中确实少了带u的3个同学:LuTao,LiLiu,WangWU
方法之间也可以连起来用,比如查询带u或U的名字但Age不为21的同学:
>>> models.Student.objects.filter(Name__contains='u').exclude(Age=21) <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19008;Name:LuTao;Sex:F;Age:25>]>
结果中少了Age=21的LiLiu同学
count()方法:
查询结果的条数
>>> models.Student.objects.all().count() 8 >>> models.Student.objects.exclude(Name__regex='u$').count() 7 >>> models.Student.objects.exclude(Name__iregex='u$').count() 6
因为查询结果是一个QuerySet集,是可以迭代的,所以条数也可以使用下面方法,但不建议使用:
>>> len(models.Student.objects.all()) 8 >>> len(models.Student.objects.exclude(Name__regex='u$')) 7 >>> len(models.Student.objects.exclude(Name__iregex='u$')) 6
reverse()方法:
前面说了数据库查询结果切片不支持负索引,那如果要查询最后一条数据就要用到reverser()方法了:
>>> models.Student.objects.all().order_by('Age')#根据Age排序 <QuerySet [<Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>, <Student: No :19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>]> >>> models.Student.objects.all().order_by('Age').reverse()#reverse()类似order_by('-Age') <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Stude nt: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>, <Student: No:19002;Name:Mark;Sex:F;Age:27>]> >>> models.Student.objects.all().order_by('Age').reverse()[0]#查询最后一条数据 <Student: No:19005;Name:WangWU;Sex:M;Age:35> >>> models.Student.objects.all().order_by('Age').reverse()[:1]#查询最后一条数据 <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:35>]> >>> models.Student.objects.all().order_by('Age').reverse()[:2]#查询最后俩条数据 <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19001;Name:watertaro;Sex:M;Age:30>]> >>> models.Student.objects.all().order_by('Age').reverse()[1]#查询倒数第二条数据 <Student: No:19001;Name:watertaro;Sex:M;Age:30>
query方法:
在每个执行语句中加一个.query即可查询,如下所示:
>>> print(str(models.Student.objects.all().query))#查看 SELECT "djangoTestApp_student"."id", "djangoTestApp_student"."No", "djangoTestApp_student"."Name", "djangoTestApp_student"."Sex", "djangoTestApp_student"."Age" FROM "djangoTestApp_student" >>> print(str(models.Student.objects.filter(Q(Age=30)&Q(Sex='F')).query))#查看 SELECT "djangoTestApp_student"."id", "djangoTestApp_student"."No", "djangoTestApp_student"."Name", "djangoTestApp_student"."Sex", "djangoTestApp_student"."Age" FROM "djangoTestApp_student" WHERE ("djangoTestApp_student"."Age" = 30 AND "djangoTestApp_student"."Sex" = F)
values方法和values_list方法:
values方法返回的是dict类型数据,values_list返回的是元祖型数据,如下所示
>>> models.Student.objects.values('No') <QuerySet [{'No': '19001'}, {'No': '19002'}, {'No': '19003'}, {'No': '19004'}, {'No': '19005'}, {'No': '19007'}]> >>> models.Student.objects.values_list('No') <QuerySet [('19001',), ('19002',), ('19003',), ('19004',), ('19005',), ('19007',)]> >>> models.Student.objects.values_list('No',flat=True)#使用flat直接显示单个字段,不需要元祖 <QuerySet ['19001', '19002', '19003', '19004', '19005', '19007']>
defer()方法
defer是不去查询某字段,如查询Student表,但不查询Age这个字段的值
>>> models.Student.objects.all().defer('Age').query.__str__() 'SELECT "djangoTestApp_student"."id", "djangoTestApp_student"."No", "djangoTestApp_student"."Name", "djangoTestApp_student"."Sex" FROM "djangoTestApp_student"'
可以查询类SQL语句中并没有查询Age这个字段
only()方法:
只查询某字段,如Student表中,只查询Name这个字段
>>> models.Student.objects.all().only('Name').query.__str__() 'SELECT "djangoTestApp_student"."id", "djangoTestApp_student"."Name" FROM "djangoTestApp_student"'
三、更新操作:
更新有俩种方法如下
>>> models.Student.objects.filter(Name__contains='u') <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19006;Name:LiLiu;Sex:F;Age:21>, <Student: No:19008;Name:LuTao;Sex:F;Age:25>]> >>> models.Student.objects.filter(Name__contains='u').update(Age=100) 3 >>> models.Student.objects.filter(Name__contains='u') <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:100>, <Student: No:19006;Name:LiLiu;Sex:F;Age:100>, <Student: No:19008;Name:LuTao;Sex:F;Age:100>]>
update之后返回的是更新的数据个数,这个适合多条数据的更新
>>> t = models.Student.objects.get(Name='WangWU') >>> t <Student: No:19005;Name:WangWU;Sex:M;Age:100> >>> t.Sex='F' >>> t.Age=35 >>> t <Student: No:19005;Name:WangWU;Sex:F;Age:35> >>> t.save() >>> t <Student: No:19005;Name:WangWU;Sex:F;Age:35>
上面这种方式是查询出一条数据,然后对其对象进行修改,最后一定记得要保存
四、删除操作:
删除关键字delete(),如下使用
>>> models.Student.objects.filter(Name__iexact='lutao') <QuerySet [<Student: No:19008;Name:LuTao;Sex:F;Age:25>]> >>> models.Student.objects.filter(Name__iexact='lutao').delete() (1, {'djangoTestApp.Student': 1}) >>> models.Student.objects.filter(Name__iexact='lutao') <QuerySet []>
或者如下先查询,再删除
>>> s = models.Student.objects.filter(Name__iexact='liliu') >>> s <QuerySet [<Student: No:19006;Name:LiLiu;Sex:F;Age:21>]> >>> s.delete() (1, {'djangoTestApp.Student': 1}) >>> s <QuerySet []>
五、排序操作:
和oracle一样关键字为order_by()
>>> models.Student.objects.all().order_by('Name') <QuerySet [<Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19 007;Name:WaterTaro;Sex:F;Age:29>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19001;Name:watertaro;Sex:M;Age:30>]> >>> models.Student.objects.all().order_by('-Name') <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>, <St udent: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>]>
字段前面加连接符(-)标识倒序查询
六、去重操作:
去重关键字distinct()
当前django版本在shell中使用|合并时已经进行了去重操作,所以这个关键字暂时用不着
>>> a = models.Student.objects.filter(Name__contains='u') >>> b = models.Student.objects.filter(Age=29) >>> c = models.Student.objects.filter(Sex='M') >>> a <QuerySet [<Student: No:19005;Name:WangWU;Sex:M;Age:35>]> >>> b <QuerySet [<Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19007;Name:W aterTaro;Sex:F;Age:29>]> >>> c <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>]> >>> abc = a | b |c >>> abc <QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student:No:19007;Name:WaterTaro;Sex:F;Age:29>]>
如上a、b、c中是有重复的,但合并为abc之后并没有看到重复项
七、起别名
和SQL类型,我们也可以使用as给每个字段起别名
>>> t = models.Student.objects.all().extra(select={'MyName':'Name'})#把字段Name起个名MyName
>>> t
<QuerySet [<Student: No:19001;Name:watertaro;Sex:M;Age:30>, <Student: No:19002;Name:Mark;Sex:F;Age:27>, <Student: No:19003;Name:ZhangSan;Sex:F;Age:30>, <Student
: No:19004;Name:LiSi;Sex:M;Age:29>, <Student: No:19005;Name:WangWU;Sex:M;Age:35>, <Student: No:19007;Name:WaterTaro;Sex:F;Age:29>]>
>>> t[0].Name
'watertaro'
>>> t[0].MyName#和Name一样
'watertaro'
>>> models.Student.objects.all().extra(select={'MyName':'Name'}).query.__str__()#查询类似SQL的语句
'SELECT (Name) AS "MyName", "djangoTestApp_student"."id", "djangoTestApp_student"."No", "djangoTestApp_student"."Name", "djangoTestApp_student"."Sex", "djangoTestApp_student"."Age" FROM "djangoTestApp_student"'
八、聚合计算
在models.py中增加一张分数表Score,用于聚合计算
class Score(models.Model): No = models.CharField('学号', max_length=10) Name = models.CharField('姓名', max_length=20) Course = models.CharField('学科',max_length = 10) Score = models.IntegerField('成绩',default = 0) def __str__(self): return 'No:' + self.No + ';Name:' + self.Name + ';Course:' + self.Course + ';Score:' + str(self.Score)
在命令行中执行如下语句
D:\PycharmProjects\untitled\MyTestProject\djangoTestPro>python manage.py makemigrations
D:\PycharmProjects\untitled\MyTestProject\djangoTestPro>python manage.py migrate
进入python shell增加数据如下:
D:\PycharmProjects\untitled\MyTestProject\djangoTestPro>python manage.py shell >>> from djangoTestApp import models >>> models.Score.objects.create(No='19001',Name='watertaro',Course='Chinese',Score=56) <Score: No:19001;Name:watertaro;Course:Chinese;Score:56> >>> models.Score.objects.create(No='19002',Name='Mark',Course='Chinese',Score=70) <Score: No:19002;Name:Mark;Course:Chinese;Score:70> >>> models.Score.objects.create(No='19003',Name='ZhangSan',Course='Chinese',Score=68) <Score: No:19003;Name:ZhangSan;Course:Chinese;Score:68> >>> models.Score.objects.create(No='19004',Name='LiSi',Course='Chinese',Score=91) <Score: No:19004;Name:LiSi;Course:Chinese;Score:91> >>> models.Score.objects.create(No='19005',Name='WangWU',Course='Chinese',Score=82) <Score: No:19005;Name:WangWU;Course:Chinese;Score:82> >>> models.Score.objects.create(No='19007',Name='WaterTaro',Course='Chinese',Score=66) <Score: No:19007;Name:WaterTaro;Course:Chinese;Score:66> >>> models.Score.objects.create(No='19001',Name='watertaro',Course='Math',Score=78) <Score: No:19001;Name:watertaro;Course:Math;Score:78> >>> models.Score.objects.create(No='19002',Name='Mark',Course='Math',Score=81) <Score: No:19002;Name:Mark;Course:Math;Score:81> >>> models.Score.objects.create(No='19003',Name='ZhangSan',Course='Math',Score=66) <Score: No:19003;Name:ZhangSan;Course:Math;Score:66> >>> models.Score.objects.create(No='19004',Name='LiSi',Course='Math',Score=80) <Score: No:19004;Name:LiSi;Course:Math;Score:80> >>> models.Score.objects.create(No='19005',Name='WangWU',Course='Math',Score=55) <Score: No:19005;Name:WangWU;Course:Math;Score:55> >>> models.Score.objects.create(No='19007',Name='WaterTaro',Course='Math',Score=78) <Score: No:19007;Name:WaterTaro;Course:Math;Score:78> >>> models.Score.objects.create(No='19001',Name='watertaro',Course='English',Score=70) <Score: No:19001;Name:watertaro;Course:English;Score:70> >>> models.Score.objects.create(No='19002',Name='Mark',Course='English',Score=51) <Score: No:19002;Name:Mark;Course:English;Score:51> >>> models.Score.objects.create(No='19003',Name='ZhangSan',Course='English',Score=59) <Score: No:19003;Name:ZhangSan;Course:English;Score:59> >>> models.Score.objects.create(No='19004',Name='LiSi',Course='English',Score=90 ) <Score: No:19004;Name:LiSi;Course:English;Score:90> >>> models.Score.objects.create(No='19005',Name='WangWU',Course='English',Score=73) <Score: No:19005;Name:WangWU;Course:English;Score:73> >>> models.Score.objects.create(No='19007',Name='WaterTaro',Course='English',Score=60) <Score: No:19007;Name:WaterTaro;Course:English;Score:60> >>> models.Score.objects.all() <QuerySet [<Score: No:19001;Name:watertaro;Course:Chinese;Score:56>, <Score: No:19002;Name:Mark;Course:Chinese;Score:70>, <Score: No:19003;Name:ZhangSan;Course:Chinese;Score:68>, <Score: No:19004;Name:LiSi;Course:Chinese;Score:91>, <Score:No:19005;Name:WangWU;Course:Chinese;Score:82>, <Score: No:19007;Name:WaterTaro;Course:Chinese;Score:66>, <Score: No:19001;Name:watertaro;Course:Math;Score:78>,<Score: No:19002;Name:Mark;Course:Math;Score:81>, <Score: No:19003;Name:ZhangSan;Course:Math;Score:66>, <Score: No:19004;Name:LiSi;Course:Math;Score:80>, <Score: No:19005;Name:WangWU;Course:Math;Score:55>, <Score: No:19007;Name:WaterTaro;Course:Math;Score:78>, <Score: No:19001;Name:watertaro;Course:English;Score:70>, <Score: No:19002;Name:Mark;Course:English;Score:51>, <Score: No:19003;Name:ZhangSan;Course:English;Score:59>, <Score: No:19004;Name:LiSi;Course:English;Score:90>, <Score: No:19005;Name:WangWU;Course:English;Score:73>, <Score: No:19007;Name:WaterTaro;Course:English;Score:60>]>
1、聚合计数:类似SQL中的group by字段,如下求各年龄的人数
>>> from django.db.models import Count
>>> models.Student.objects.values('Age').annotate(cnt=Count('Age')).values('Age','cnt')#以Age为分组,查询每个Age有几个人 <QuerySet [{'Age': 27, 'cnt': 1}, {'Age': 29, 'cnt': 2}, {'Age': 30, 'cnt': 2},{'Age': 35, 'cnt': 1}]>
使用query可以看到具体释义
>>> models.Student.objects.values('Age').annotate(cnt=Count('Age')).values('Age','cnt').query.__str__() 'SELECT "djangoTestApp_student"."Age", COUNT("djangoTestApp_student"."Age") AS "cnt" FROM "djangoTestApp_student" GROUP BY "djangoTestApp_student"."Age"'
这里的Count是对查询出的Age条数进行统计,不一定为Age。cnt即为
2、聚合求和:类似SQL中的sum字段,如下求所有同学的所有课程的总分
>>> from django.db.models import Sum #导入Sum >>> models.Score.objects.values('No','Name').annotate(sum_score=Sum('Score')).values('No','Name','sum_score')#查询同学的总分 <QuerySet [{'No': '19001', 'Name': 'watertaro', 'sum_score': 204}, {'No': '19002', 'Name': 'Mark', 'sum_score': 202}, {'No': '19003', 'Name': 'ZhangSan', 'sum_score': 193}, {'No': '19004', 'Name': 'LiSi', 'sum_score': 261}, {'No': '19005','Name': 'WangWU', 'sum_score': 210}, {'No': '19007', 'Name': 'WaterTaro', 'sum_score': 204}]>
结合前面的排序,以总分从高到低排序如下
>>> models.Score.objects.values('No','Name').annotate(sum_score=Sum('Score')).values('No','Name','sum_score').order_by('-sum_score') <QuerySet [{'No': '19004', 'Name': 'LiSi', 'sum_score': 261}, {'No': '19005', 'Name': 'WangWU', 'sum_score': 210}, {'No': '19001', 'Name': 'watertaro', 'sum_score': 204}, {'No': '19007', 'Name': 'WaterTaro', 'sum_score': 204}, {'No': '19002', 'Name': 'Mark', 'sum_score': 202}, {'No': '19003', 'Name': 'ZhangSan', 'sum_score': 193}]>
3、聚合求平均数:类似SQL中的avg字段,如下求每门课程的平均分
>>> from django.db.models import Avg #导入Avg >>> models.Score.objects.values('Course').annotate(avg_course=Avg('Score')).values('Course','avg_course') <QuerySet [{'Course': 'Chinese', 'avg_course': 72.16666666666667}, {'Course': 'English', 'avg_course': 67.16666666666667}, {'Course': 'Math', 'avg_course': 73.0}]> >>> models.Score.objects.values('Course').annotate(avg_course=Avg('Score')).values('Course','avg_course').query.__str__() 'SELECT "djangoTestApp_score"."Course", AVG("djangoTestApp_score"."Score") AS "avg_course" FROM "djangoTestApp_score" GROUP BY "djangoTestApp_score"."Course"'
从上可以看到各门课程的平均值,查看执行的类SQL语句,意思都差不多,只是写法稍微不同
4、聚合求最小值:类似SQL中的min字段,如下求每门课程的最低分数
>>> from django.db.models import Min#导入Min >>> models.Score.objects.values('Course').annotate(min_course=Min('Score')).values('Course','min_course') <QuerySet [{'Course': 'Chinese', 'min_course': 56}, {'Course': 'English', 'min_course': 51}, {'Course': 'Math', 'min_course': 55}]>
5、聚合求最大值:类似SQL中的max字段,如下求每门课程的最高分数
>>> from django.db.models import Max#导入Max >>> models.Score.objects.values('Course').annotate(min_course=Max('Score')).values('Course','min_course') <QuerySet [{'Course': 'Chinese', 'min_course': 91}, {'Course': 'English', 'min_course': 90}, {'Course': 'Math', 'min_course': 81}]>
九、字段聚合显示
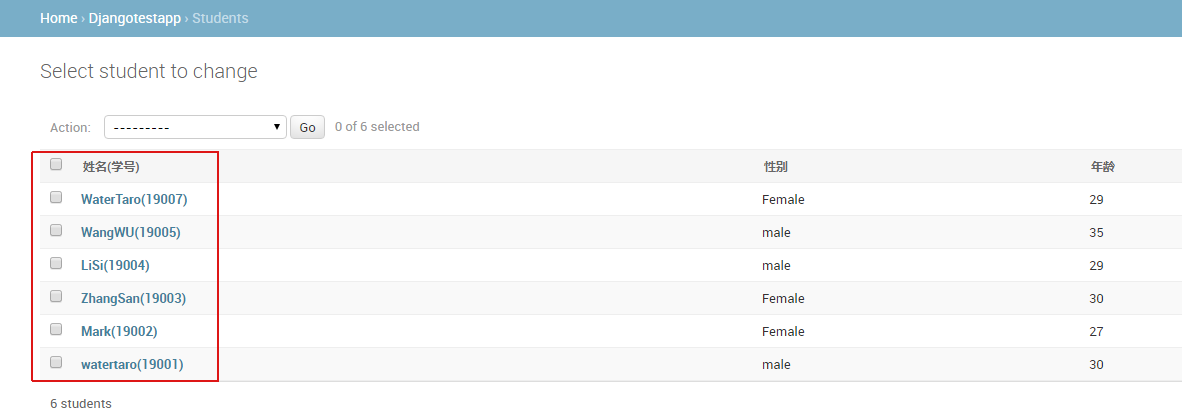
比如Student表中,如果想把姓名(Name)和学号 (No)合并显示为Name(No),比如No=19001显示为watertaro(19001),可以如下操作
1、在Student表类中增加如下代码
class Student(models.Model): No = models.CharField('学号',max_length = 10) Name = models.CharField('姓名',max_length = 20) Sex = models.CharField('性别',max_length = 1,choices = SEX_CHOICE,default = 'M') Age = models.IntegerField('年龄') def name_no(self): return self.Name + '(' + self.No + ')' name_no.short_description = '姓名(学号)' NameNo = property(name_no)
2、在admin.py中修改显示字段
class StudentAdmin(admin.ModelAdmin): list_display = ('NameNo','Sex','Age',)
此时刷新界面就会显示如下样式:
完结!