一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取软件之家软件下载排行榜
2.主题式网络爬虫爬取的内容:爬取软件下载排名、下载次数
3.主题式网络爬虫设计方案概述
实现思路:访问目标网页的源代码,使用get请求和BeautifulSoup解析工具爬取数据并采集保留,然后进行数据清洗和处理,数据分析与可视化,画出散点图,用最小二乘法分析两个变量间的二次 拟合方程和绘制拟合曲线。
技术难点:对库的正确认识与应用以及数据分析
二、主题页面的结构特征分析
1.主题页面的结构与特征分析:观察发现,爬取所需数据都在<li class="m-list-item m-list-item-ictive>中,软件排名标签为"class=title()",名称标签为"class=sces''",下载次数标签为"class=sdate"。
2.Htmls
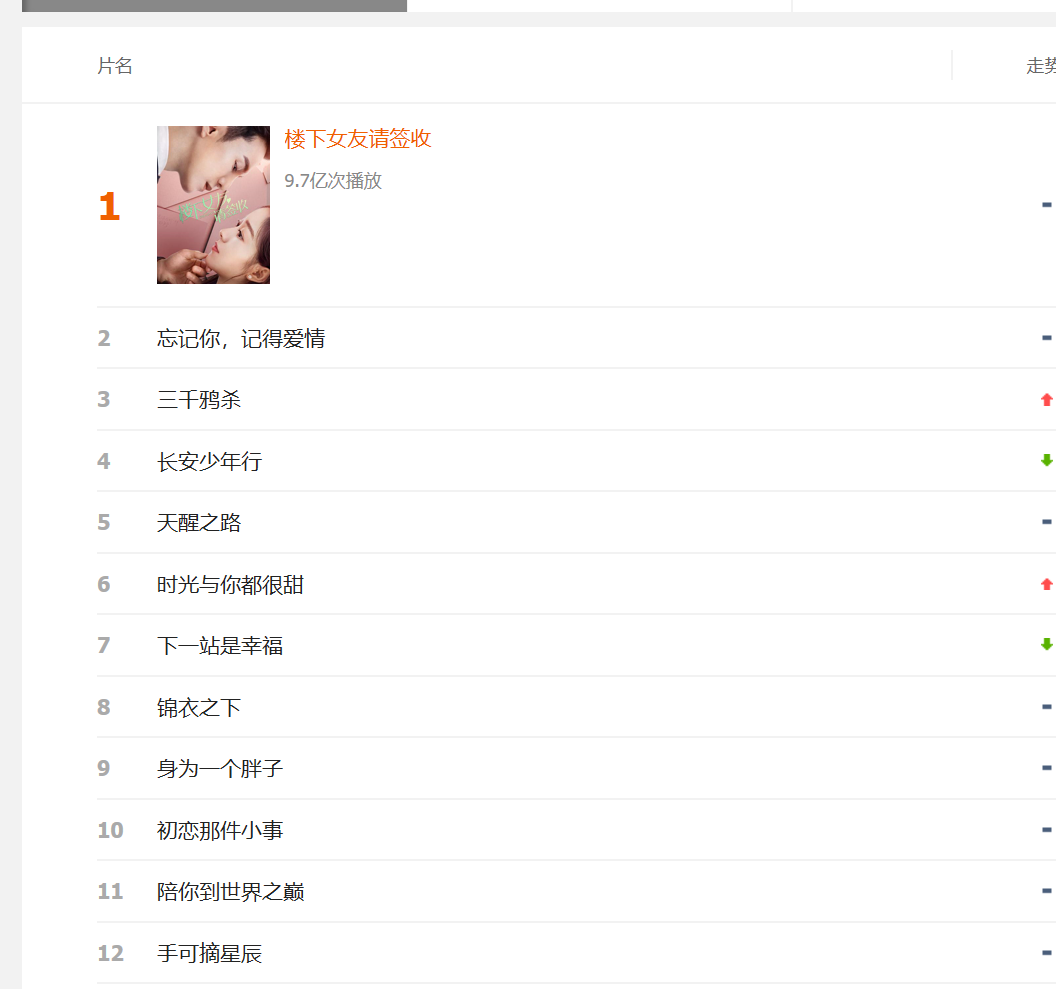

3.节点(标签)查找方法与遍历方法
for child in soup.body.contents: print(child)
soup.select('title')
三、网络爬虫程序设计
1.数据爬取与采集
import requests from bs4 import BeautifulSoup import pandas as pd #对url发出get请求 url='https://www.mgtv.com/top/tv/' headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'} r = requests.get(url, headers=headers,timeout=10) def getHTMLText(url,timeout = 30): try: r = requests.get(url, timeout = 30) #用requests抓取网页信息 r.raise_for_status() #可以让程序产生异常时停止程序 r.encoding = r.apparent_encoding #设置编码标准 return r.text except: return '产生异常' #获取源代码 html=r.text soup=BeautifulSoup(html,'html.parser') title = soup.find_all('span',class_="title") desc= soup.find_all('span', class_='desc') print('{:^35}'.format('芒果TV电视剧排行榜')) print('{:^8}\t{:^8}\t{:^8}'.format('排名', '标题', '播放次数(亿次)')) #创建空列表 a=[] for i in range(30): print('{:^5}\t{:^15}\t{:^20}'.format(i+1,title[i].string,desc[i].string)) a.append([i+1,title[i].string,desc[i].string]) df = pd.DataFrame(list, columns=['排名','标题','播放次数(亿次)']) print(df)
2.对数据进行清洗和处理
#读取csv文件 df=pd.DataFrame(pd.read_excel('abc.xlsx')) df
#删除无效列与行 df.drop('剧名', axis=1, inplace = True) df
# 查找重复值 df.duplicated()
# 删除重复值
df = df.drop_duplicates()
df
#查找空值
df['播放量'].isnull().value_counts()
df
#若有则删除缺失值
df[df.isnull().values==True]
df.corr()
#查找异常值 df.describe() df
3.文本分析
# 构建线性回归预测模型 from sklearn.linear_model import LinearRegression X = df.drop("播放量", axis = 1) predict_model = LinearRegression() predict_model.fit(X, df['播放量']) print("回归系数为:", predict_model.coef_)
4.数据分析与可视化
#绘制排名与评分的回归图 matplotlib.rcParams['font.sans-serif']=['SimHei'] sns.regplot(df.排名,df.播放量)
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)
def main(): colnames=["排名","剧名","播放量"] df=pd.read_csv('芒果TV电视剧排行榜.csv',skiprows=1,names=colnames) X=df.排名 Y=df.剧名 def func(p,x): k,b=p return k*x+b def error_func(p,x,y): return func(p,x)-y p0=[1,20] Para = leastsq(error_func,p0,args = (X,Y)) k,b = Para[0] print("k=",k,"b=",b) plt.figure(figsize=(10,8)) plt.scatter(X,Y,color="blue",label=u"播放量分布",linewidth=2) x=np.linspace(0,30,25) y=k*x+b plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("芒果TV电视剧排名和播放量关系图") plt.xlabel('排名') plt.ylabel('播放量(单位:亿次)') plt.legend() plt.show() main()
6.数据持久化
data.to_csv('mgtv.csv')
7.将以上各部分的代码汇总,附上完整程序代码
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib import seaborn as sns #对url发出get请求 url='https://www.mgtv.com/top/tv/' headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'} r = requests.get(url, headers=headers,timeout=10) def getHTMLText(url,timeout = 30): try: r = requests.get(url, timeout = 30) #用requests抓取网页信息 r.raise_for_status() #可以让程序产生异常时停止程序 r.encoding = r.apparent_encoding #设置编码标准 return r.text except: return '产生异常' #获取源代码 html=r.text soup=BeautifulSoup(html,'html.parser') title = soup.find_all('span',class_="title") desc= soup.find_all('span', class_='desc') print('{:^35}'.format('芒果TV电视剧排行榜')) print('{:^8}\t{:^8}\t{:^8}'.format('排名', '标题', '播放次数(亿次)')) #创建空列表 a=[] for i in range(30): print('{:^5}\t{:^15}\t{:^20}'.format(i+1,title[i].string,desc[i].string)) a.append([i+1,title[i].string,desc[i].string]) df = pd.DataFrame(list, columns=['排名','标题','播放次数(亿次)']) print(df) data.to_csv('mgtv.csv') #读取csv文件 df=pd.DataFrame(pd.read_excel('abc.xlsx')) #删除无效列与行 df.drop('剧名', axis=1, inplace = True) # 查找重复值 df.duplicated() # 删除重复值 df = df.drop_duplicates() #查找空值 df['播放量'].isnull().value_counts() #若有则删除缺失值 df[df.isnull().values==True] df.corr() #查找异常值 df.describe() # 构建线性回归预测模型 from sklearn.linear_model import LinearRegression X = df.drop("播放量", axis = 1) predict_model = LinearRegression() predict_model.fit(X, df['播放量']) print("回归系数为:", predict_model.coef_) #绘制排名与评分的回归图 matplotlib.rcParams['font.sans-serif']=['SimHei'] sns.regplot(df.排名,df.播放量) def main(): colnames=["排名","剧名","播放量"] df=pd.read_csv('芒果TV电视剧排行榜.csv',skiprows=1,names=colnames) X=df.排名 Y=df.剧名 def func(p,x): k,b=p return k*x+b def error_func(p,x,y): return func(p,x)-y p0=[1,20] Para = leastsq(error_func,p0,args = (X,Y)) k,b = Para[0] print("k=",k,"b=",b) plt.figure(figsize=(10,8)) plt.scatter(X,Y,color="blue",label=u"播放量分布",linewidth=2) x=np.linspace(0,30,25) y=k*x+b plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("芒果TV电视剧排名和播放量关系图") plt.xlabel('排名') plt.ylabel('播放量(单位:亿次)') plt.legend() plt.show() main()
四、结论
1.经过对芒果TV电视剧排行榜的数据分析和可视化,可以清楚看出各排名电视剧的具体播放量,播放量越多,排名越高,对数据有了更深切的了解和更直观的感受。
2.小结:通过此次任务,更清楚的看到了自己对这门课程没有掌握的地方,发现了自己的许多不足,并在这次任务的过程中,逐渐学到了更多,对这门课程的了解也更深入了。