使用request、xpath爬取网址
》爬取该网址:猫眼电影之经典影片
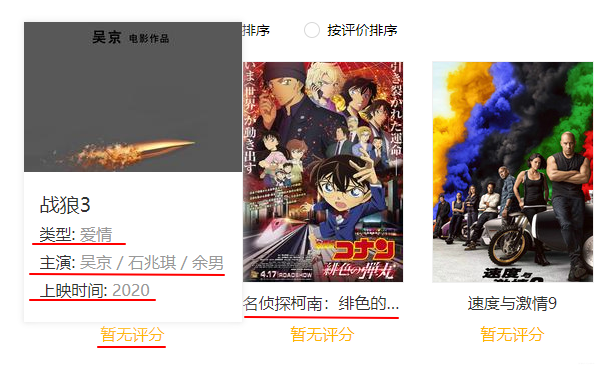
》爬取内容,如图所示:
主要爬取:电影类型、主演、时间、片名和评分
》代码如下:
import requests
from lxml import etree
url = "https://maoyan.com/films?showType=3"
headers = {
"Cookie": "_lxsdk_s=17188754dc5-9bf-d80-9e6%7C%7C9",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60"
}
response = requests.get(url=url, headers=headers)
response.encoding = "utf-8"
html = etree.HTML(response.text)
dd_list = html.xpath("//dl[@class='movie-list']//dd")
for item in dd_list:
info = {}
info["mv_title"] = item.xpath("./div[@class='channel-detail movie-item-title']/a/text()")[0]
info["mv_tag"] = item.xpath(".//div[@class='movie-hover-title'][2]/text()")[1].strip()
info["mv_star"] = item.xpath(".//div[@class='movie-hover-title'][3]/text()")[1].strip()
info["mv_date"] = item.xpath(".//div[@class='movie-hover-title movie-hover-brief']/text()")[1].strip()
if not item.xpath("./div[@class='channel-detail channel-detail-orange']//i[1]/text()"):
info["mv_score"] = "暂无评分"
else:
first_p = item.xpath("./div[@class='channel-detail channel-detail-orange']//i[1]/text()")
second_p = item.xpath("./div[@class='channel-detail channel-detail-orange']//i[2]/text()")
info["mv_score"] = "".join(first_p) + "".join(second_p) + "分"
print(info)
# mv_list.append(info)
#解析:
1)熟练使用request,结合xpath获取爬虫内容;
2)猫眼电影网址有反爬策略,提取相关的cookie值带入即可正常返回网页源代码;
3)第18行,使用xpath语句获取字段,并使用列表索引获取数据;
4)第19行,.strip()方法用于去除数据中左右两边的空格;
5)第22行,对xpath语句进行判断某字段是否存在。用if not xpath语句进行判断;
6)第27行,将获取到的评分数据,从列表格式转化成字符串格式。使用python中的join()方法
ps:
关于 join()方法 的使用:
》概述:join()方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
》语法:str.join(sequence)。其中str表示需要用什么字符进行分割;sequence 表示要连接的元素序列
》示例:
mylist=['a','b','2','s']
res="".join(mylist)
print(res)
# 输出结果为:ab2s
# 若使用"|"字符,那么输出结果将为:a|b|2|s
end:
附上其他博主的文章:https://www.cnblogs.com/hongweijiang/p/12047927.html (Python列表与字符串相互转换的几种操作)
该join()方法参考自该文章
另外!将数据保存到csv中(csv文件可以用excel打开)
代码如下:
import csv
# 定义表格标题
title = ['mv_title', 'mv_tag', 'mv_star', 'mv_date', 'mv_score']
# 需要显示如下样式才能往csv文件添加数据:
# rows = [('开国将帅授勋1955', '爱情', '吴京/石兆琪/余男', '2020', '暂无评分'),
# ('开国将帅授勋1955', '爱情', '吴京/石兆琪/余男', '2020', '暂无评分'),
# ('开国将帅授勋1955', '爱情', '吴京/石兆琪/余男', '2020', '暂无评分'),
# ]
row_list = []
for item in mv_list:
# 遍历mv_list,获取字典中的value值,再转化为元组格式,最后添加到新列表中
row_list.append(tuple(item.values()))
with open('maoyan.csv', 'w', newline="", encoding="utf-8-sig") as f:
# newline="" 让每条插入的数据不会间隔一行
# 注意需要使用"utf-8-sig"进行编码格式,否则会出现乱码
f_csv = csv.writer(f)
f_csv.writerow(title)
f_csv.writerows(row_list)
