每天一点点,记录学习每一步
近期爬虫项目:
1:python 爬取菜鸟教程python100题,百度贴吧图片反爬虫下载,批量下载
3:python 爬虫爬取百度贴吧图片 urllib.request.urlretrieve图片批量下载函数
python爬取猫眼电影top100榜数据
目标url = 猫眼电影top100榜网址
1:确定抓取的数据字段:排名,海报,电影名字,主演,上映时间,评分;
2:分析页面html标签结构,找到数据所在位置;
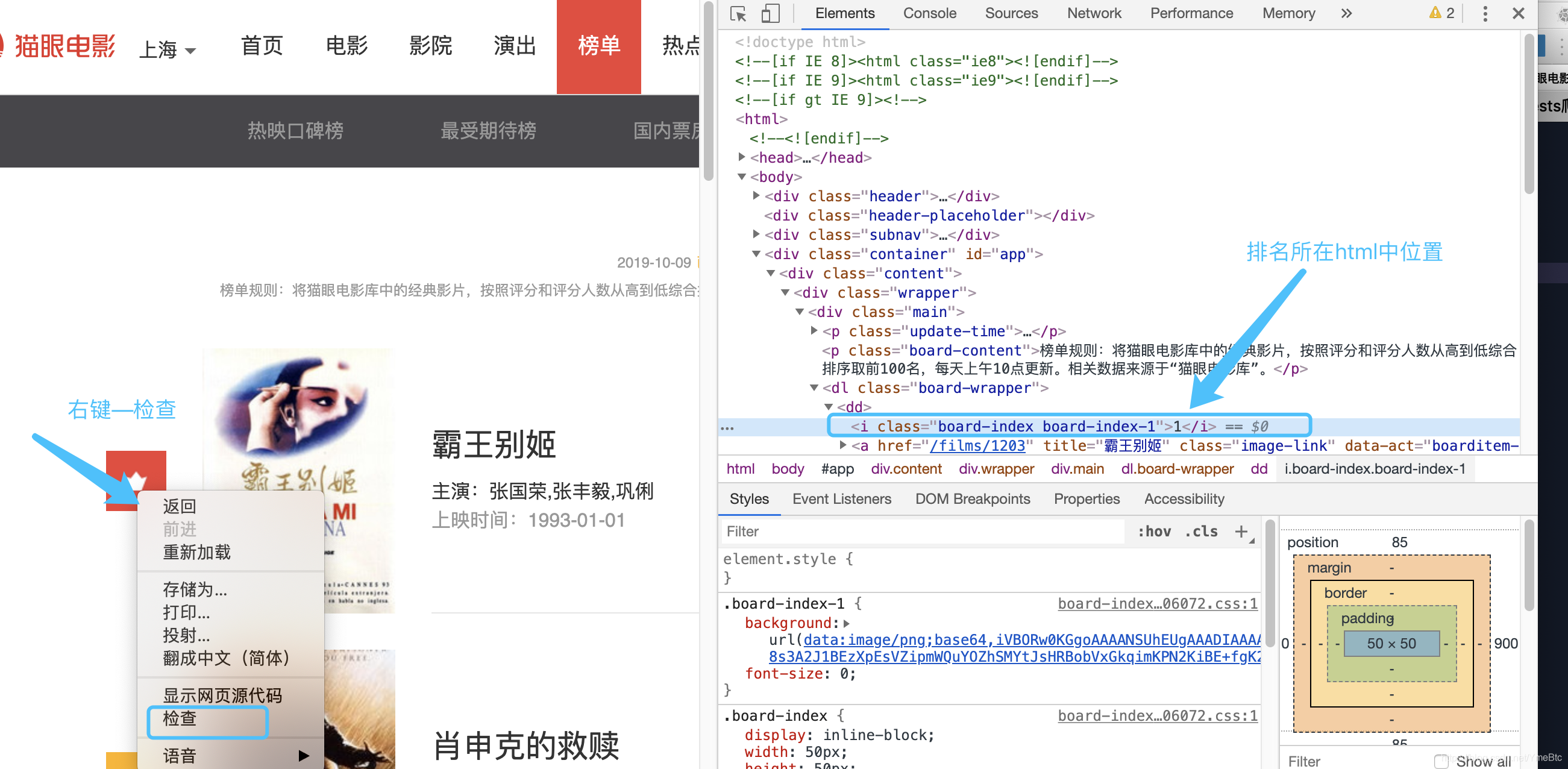
1:)排名所在html标签结构中的位置:
index = html.xpath('//dd/i/text()')
2:)海报所在html标签结构中的位置:
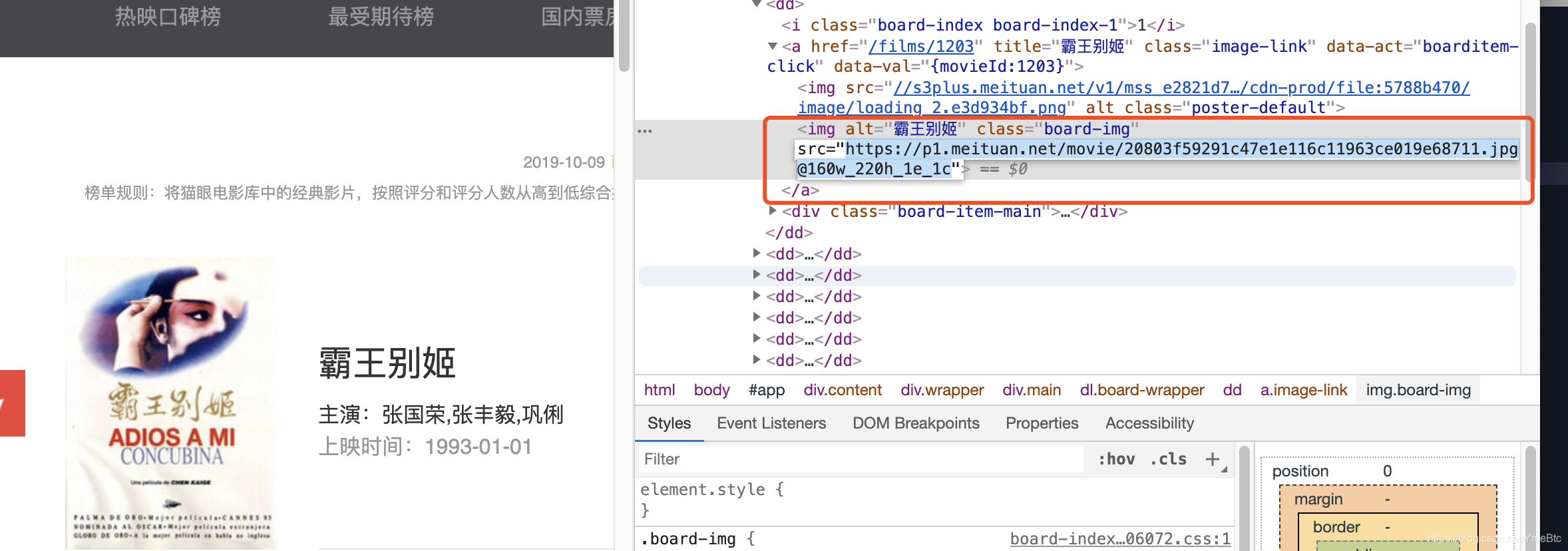
这样找到的海报图片是错误哒~~~~~正确的海报图片所在位置:
页面空白处,右键,查看网页源代码,ctrl + f 查找img ,可以看到有两个img信息,分别打开可以看到,第一个img是错误的,第二个img才是真正的海报信息
img = html.xpath('//a/img[@class="board-img"]/@data-src')

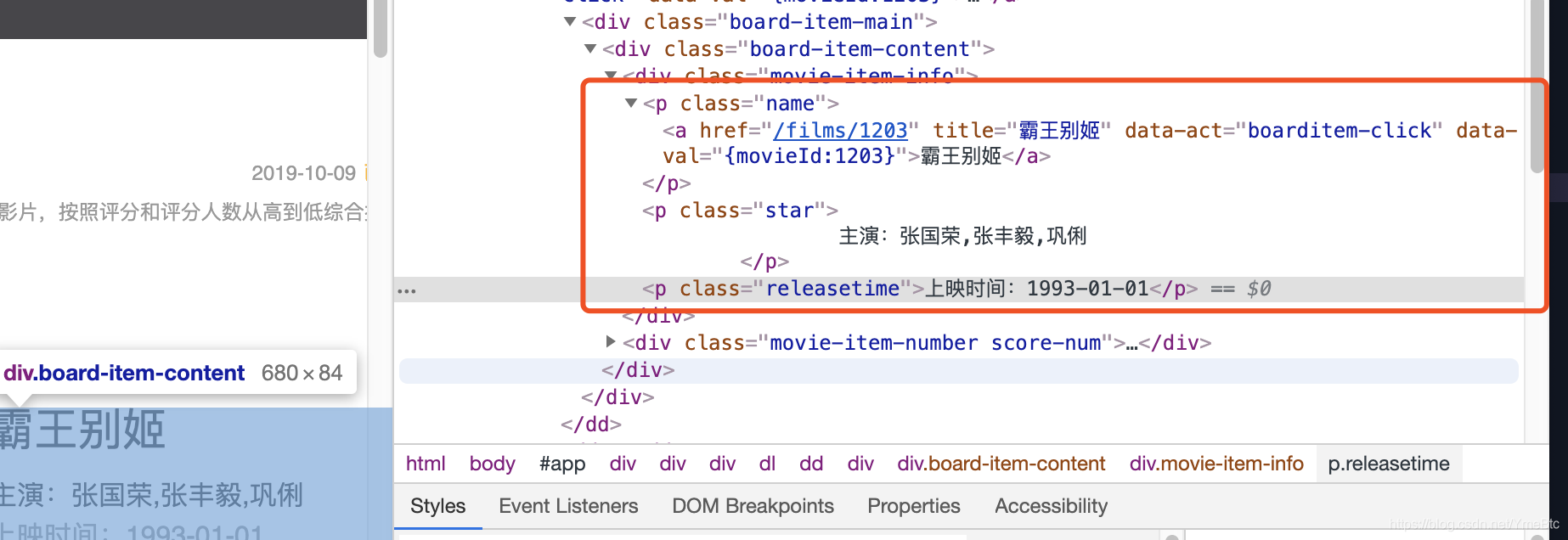
3:)电影名字,主演,上映时间所在html标签结构中的位置:
movie = html.xpath('//p[@class="name"]/a/title') #电影名字
yname = html.xpath('//p[@class="star"]/text()') #主演名字,需要去掉空格,换行符
stime = html.xpath('//p[class="releasetime"]/text()') #上映时间
4:)评分所在html标签结构中的位置:
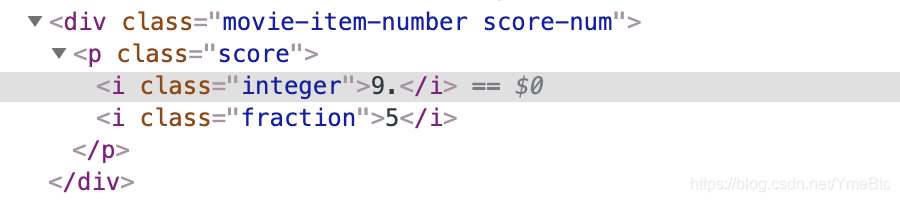
score1 = html.xpath('//p[@class="score"]/i[1]/text()') #评分分两部分,需要分别取出并相加
score2 = html.xpath('//p[@class="score"]/i[2]/text()')