1.安装配套环境
(1)首先安装OCR字符识别库Tesseract 下载网址:https://digi.bib.uni-mannheim.de/tesseract/
下载下图对应的版本
下载后双击进行安装,这里因为我们要识别中文字符,所以在安装界面中需要进行额外的语言勾选,展开Additional language data

然后点击next安装即可(注意:在选择安装路径的时候不要出现中文,并且要记住这个安装路径)
接下来配置环境变量.路径添加到环境变量中
分别对用户变量PATH和系统变量Path添加刚才的安装目录 D:\toolplace\OCR\Tesseract-OCR; 这里注意各个变量之间隔开用英文的分号。
环境变量修改好之后验证下是否安装成功。打开cmd命令行工具 敲入命令:
Tesseract -v安装python环境
pip install Pillow==5.2.0
pip install pytesseract==0.2.4
pathSaveShot = “”
img = Image.open(pathSaveShot)
text = pytesseract.image_to_string(img, lang='chi_sim')
logging.info('[截取图片的识别结果:' + text + ']')
问题:
安装之后报错
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path

报错原因很明确: 没有找到 tesseract
解决方案:
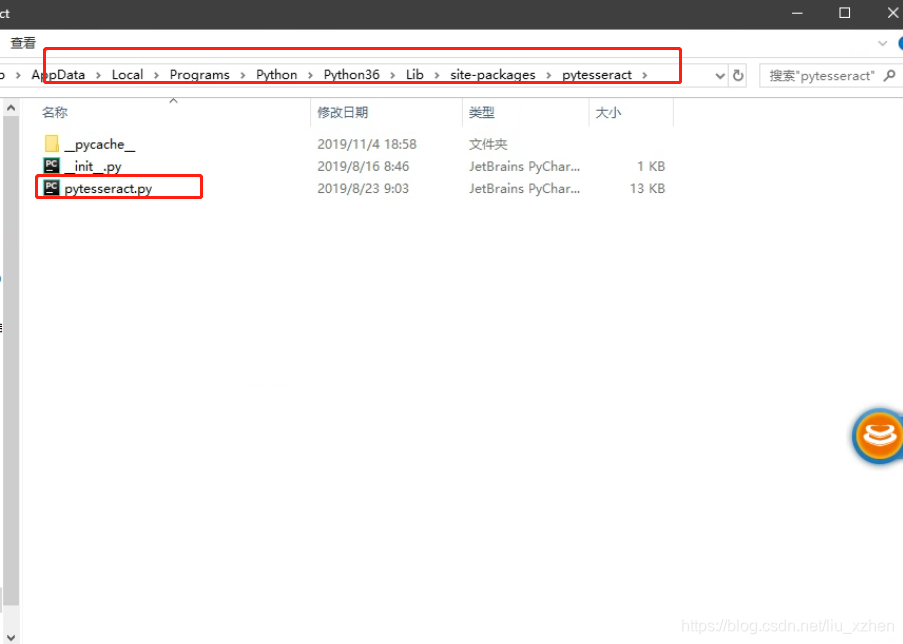
1.找到python的安装路径下的pytesseract: 例如我的是 E:\Python3.7.1\Lib\site-packages\pytesseract
2.用文本编辑器打开,查找tesseract_cmd
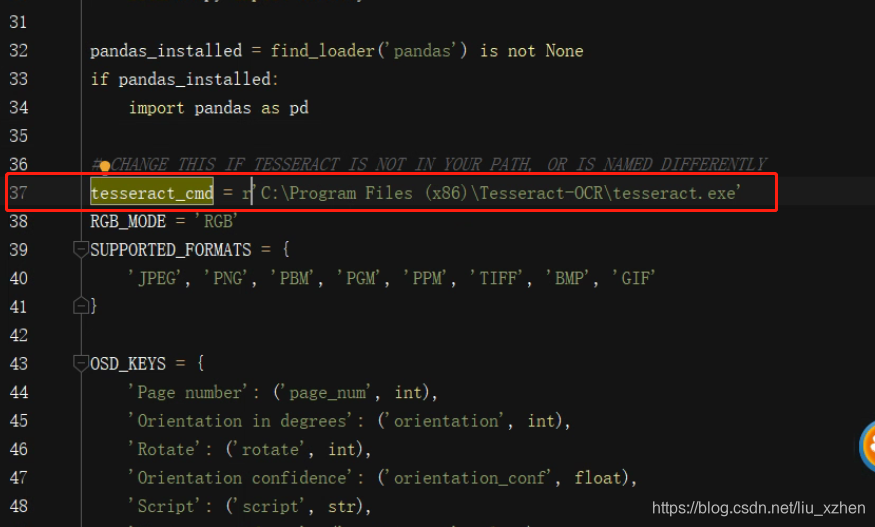
将原来的 tesseract_cmd = 'tesseract' 改为: tesseract_cmd = 'OCR的安装路径下的tessract.exe'
例如我的是 tesseract_cmd = 'C:\Program Files\Tesseract-OCR\\tesseract.exe'
注意有的地方需要转义 例如 \\tesseract.exe,或者也可直接加r转义
tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
报错问题2:
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:\\Program Files (x86)\\Tesseract-OCR\\/tessdata/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
解决方法:
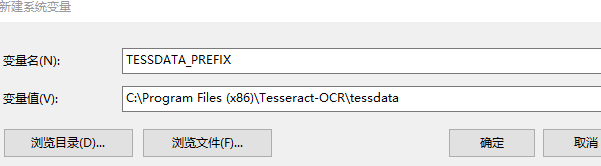
1.要设置环境变量 TESSDATA_PREFIX,它的值为tessdata目录
系统默认tessdata目录 :C:\Program Files (x86)\Tesseract-OCR\tessdata
2.设置完再次运行如果仍然报相同的错误,重启一下电脑即可。