今天又有点时间了,所以还是抽出点时间写点小东西吧。
其实关于Java中常用容器的知识点,我很早之前就有总结过,只不过在自己手写的笔记本上(忽然发现很久没手写笔记了啊 )趁着今天的机会,自己再整理一波,顺便给大家贴上来。
)趁着今天的机会,自己再整理一波,顺便给大家贴上来。
)趁着今天的机会,自己再整理一波,顺便给大家贴上来。
今天暂时只整理一下Map的东西,其他的容器,像List啊 Set啊 这些等有时间也会整理一下贴出来。
好了,首先先给大家贴一张图上来,这图是之前在网上看到的一张挺经典的图,很好的描述了Java中各容器之间的关系,我感觉还是比较清晰的,所以放上来给大家看一下。
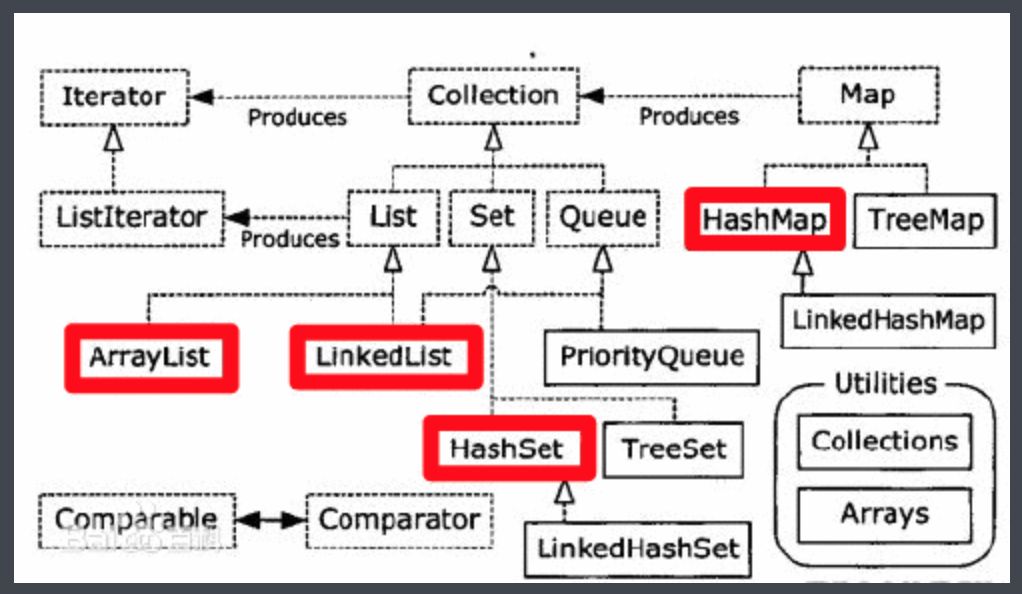
可以看到这个图很清晰描述了各个容器之间的关系,标红色的部分是大家常用到的
图上的东西还是挺多,像Iterator迭代器啊,Comparable接口啊, Comparator接口啊,这些有时间再讲。
先大概提一下,基本上只要涉及到和Tree相关的容器,也就是底层实现是二叉树的容器,基本上都会用到Comparable接口和Comparator接口,这两个接口一个是让放入容器中的元素具有比较性,另一个是让容器
刚一初始化容器本身就带有可比较元素的功能,好了,这个先不多说了,有时间具体讲。
看一个东西,要先看顶层的接口,再看其具体的实现类,因为顶层的接口里边都是这一类事物共同具有的共性的东西,所以大家先看下Map接口中的东西

因为是容器嘛,所以里边的操作必然是添加、删除、判断、加获取。
把上边的方法大概归一下类
1.添加
2.删除
clear()
3.判断
containsKey(Object key)containsValue(Object value)isEmpty()
4.获取
size()
values()entrySet()
keySet()
上边归类列出的是常用的方法,看字面意思也能知道都是什么意思,不多说了。
接口中共性的方法看完后,接下来就该看Map的小弟了
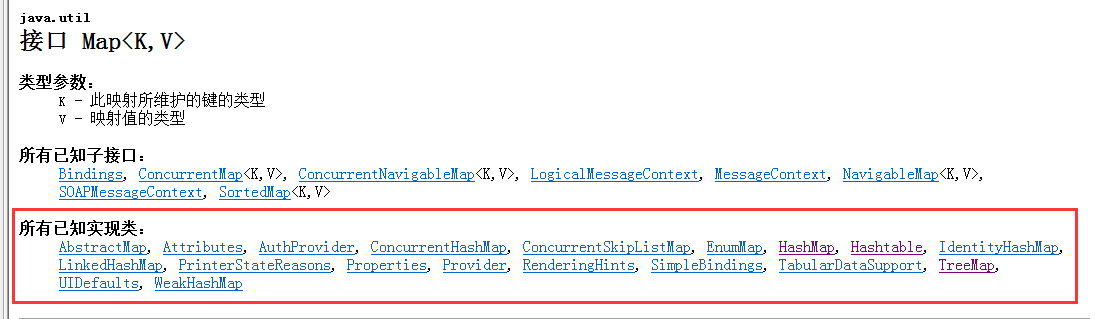
可以看到实现了Map接口的小弟有这么多,咱们常用的基本就三个
|--Hashtable:底层实现是哈希表数据结构,不可以存入null键和null值,JDK1.0出现的,是线程同步的
|--HashMap:底层实现是哈希表数据结构,允许存入null键和null值,JDK1.2出现的,是线程不同步的
|-- TreeMap:底层实现是二叉树数据结构,JDK1.2出现的,线程不同步,因为是二叉树数据结构,
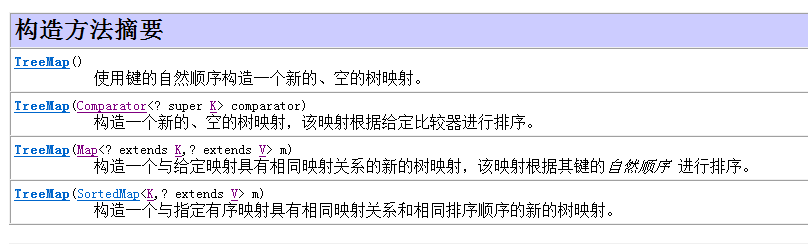
所以要想往该容器里存东西必须保证你存入的key是具有比较性的,或者是该容器自身
具备比较功能,所以大家可以看到下图里TreeMap的构造方法里都要求了键的比较性排序
如果你的键具有比较性,就可以放入该容器,这个称之为按照自然顺序放入;如果你的键
你没有让它具备比较性(也就是你没让你的键这个类实现Comparable接口),则你就得
让你的容器一构造出来就具备比较的功能,就是传入一个Comparator比较器,就是下图的
第二种构造方式,这种称为按照指定的比较顺序放入,而不是元素自身具体的自然排序
因为Map中的key是唯一的,所以必然会想到那各个实现的Map接口的实现类都是怎么保证key的唯一性呢?
Hashtable和
HashMap从名字就能看出,因为他们底层结构是哈希表实现的,所以他们判断唯一性的
标准是
首先根据hashCode方法判断,如果返回的hashCode值不一样它就直接判断为不重复;
如果返回的
hashCode
一样,它就会继续根据equals方法进行判断,如果equals返回true则认为重复,
如果返回false则认为不重复。
TreeMap从名字看出来底层是二叉树,二叉树判断元素的唯一性是根据元素的比较性,
实现了Comparable接口
以后,实现里边的compareTo方法,这个方法会返回 1、0、-1
如果返回0则认为两个元素相等,就是重复,
返回1,则会把比较的元素放到被比较元素的右边,
如果返回-1,则会
把比较的元素放到被比较元素的左边,
因为放入的时候是有规律的,
所以取出的时候也按照规律取出的话,这样放入二叉树结构容器里的元素就相当于
是排了序的。
因为你写的实体类在应用中很有可能就会被放到各种不同的容器里去,
所以最最正规的做法就是你写的实体类最好
去自己重写hashCode方法和equals方法,其次就是让你的实体实现Comparable接口,
就是让你的实体放到二叉树的,
容器中后可以自然排序。
大家可以随便看一个Java JDK里的类,基本上都实现了
C
omparable接口
随便看个String和Integer的吧
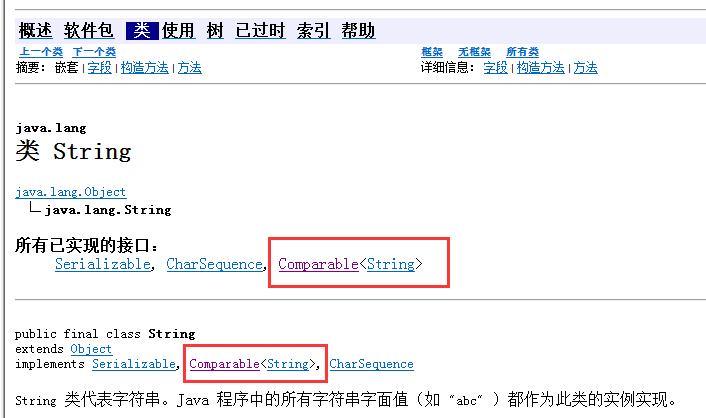
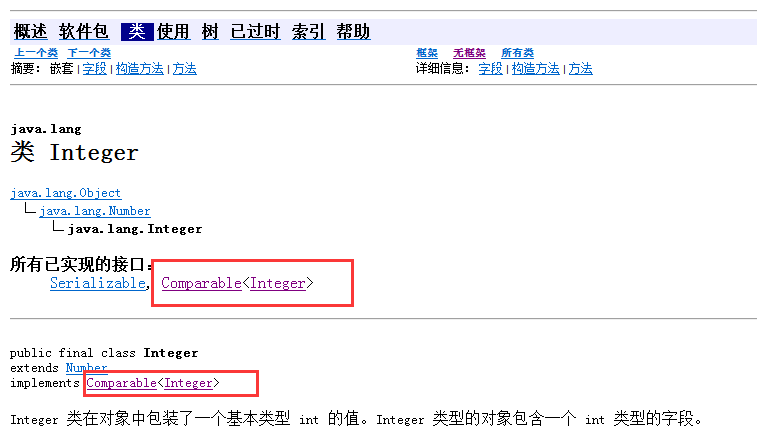
可以看到String和Integer都实现了Comparable接口。
关于放入二叉树结构容器必须具有比较性啊,排序啊,这些问题到时候有时间我会整理一篇出来
这里就先不多说了。
接下来看看一个Map中常用,也比较重要的一个,就是怎么循环取出map中的多个元素
有两种方法
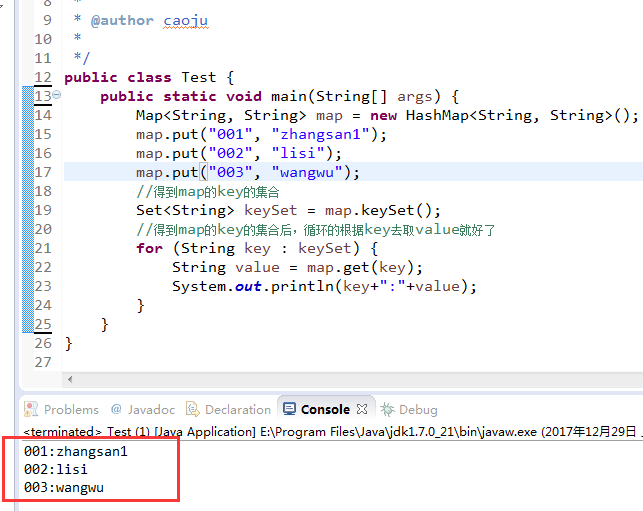
1.Map中有个方法 keySet()
这个方法是把map中的key转成set集合返回返回值就是set<K>,然后通过key找到value
这个方法是把map中的key转成set集合返回返回值就是set<K>,然后通过key找到value
举个生活中的例子,这个方式就相当于生活中通过老公(key)能找到妻子(value)似的,
举的这个例子会和下边的进行对比
下面代码写一下,实验一下
package com.cj.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
*
* @author caoju
*
*/
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("001", "zhangsan1");
map.put("002", "lisi");
map.put("003", "wangwu");
//得到map的key的集合
Set<String> keySet = map.keySet();
//得到map的key的集合后,循环的根据key去取value就好了
for (String key : keySet) {
String value = map.get(key);
System.out.println(key+":"+value);
}
}
}
2.Map中还有个方法entrySet()
返回此映射中包含的映射关系的set视图。这个是JDK API官方的解释
它的返回值是Set<Map.Entry<K,V>>看起来很诡异。但是Set是个集合那它泛型里边一定是个类型
所以Map.Entry<K,V>肯定是个类型,只不过写法很特殊。
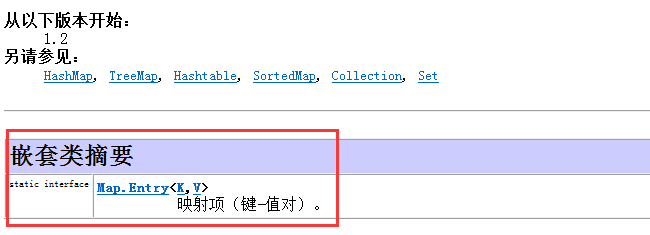
看文档可以知道,Map接口中有个内部接口叫Entry
看Map接口的源码也能出来

但是源码上是直接在Map接口中定义了一个interface Entry<K,V>,
为什么API文档上却写成了Map.Entry<K,V>呢?
对内部类比较熟悉的的话,对这个写法应该不会觉得懵逼。
咱们平常要想直接访问内部类中的东西,那肯定得new一个内部类出来,才能访问其内容。
所以咱们会这么写,Outer.Inner inner = new Outer().new Inner();
所以上边的Outer.Inner就是一种类型,这个类型就是指内部类类型,
那Map.Entry<K,V>
和这个不是同样的道理吗
也就是说,如果interface Entry<K,V> 这个接口不是在Map内部,那写它的类型的时候直接
就可以写成Entry<K,V>,
但是它现在是Map的内部接口,所以就得写成Map.
Entry<K,V>。
估计小伙伴么会有疑问?为什么这么写呢,这么麻烦。。。
其实这么写也是有原因的,因为如果其他接口中也有个
叫
Entry<K,V>的内部接口,
那你直接写Entry<K,V>,你到底是指谁里边的Entry<K,V>呢,是不是就有歧义了,
所以写内部类或者内部接口的类型时需要在前边带上它的外部类的类名。
但是Map.Entry<K,V>中玩意是个接口,Map中的entrySet()的返回值Set<Map.Entry<K,V>>
里边的Map.Entry<K,V>
肯定不是一个接口了,
肯定是个实现了
Map.Entry<K,V>这个接口
的具体实现类,
具体怎么返回的,不需要咱们管,不同的具体Map他们
自己里边
的
entrySet()方法肯定会有具体的实现的。
但是Map中为什么要定义interface Entry<K,V>这个接口呢?
我觉得是因为Map里不是存的key value关系的数据吗?
Entry<K,V>这个接口就是描述key value之间的这个关系。
Java认为一切皆对象嘛,所以它就把这个关系也封装成个接口了。
上边第一种方法举了个生活中老公妻子的例子
现在再举个生活中的例子,还是刚才的老公和妻子,
Entry<K,V>就相当于生活中的结婚证书,
这个证书描述了老公和妻子之间的关系。
entrySet()的返回值Set<Map.Entry<K,V>>就相当于返回的这个Set集合里
装了一堆结婚证书(也就是一堆Entry<K,V>)
第一个例子是通过老公(key)找到妻子(value),现在这种就是通过结婚证书能找到结婚证上
的老公和老婆。大家可以看下图,Entry<K,V>类里边getKey()和getValue()都有
(这栗子不知道恰当不恰当。。。)
但是具体不同的Map他们各自对这个关系描述的实现也不一样,
就是说实现了Map接口的这些小弟们,像
Hashtable、HashMap、TreeMap他们内部
也都具体的实现了
interface Entry<K,V>这个接口。举个HashMap例子的截图,
大家可以看下边的图是HashMap中对这个内部接口的具体实现
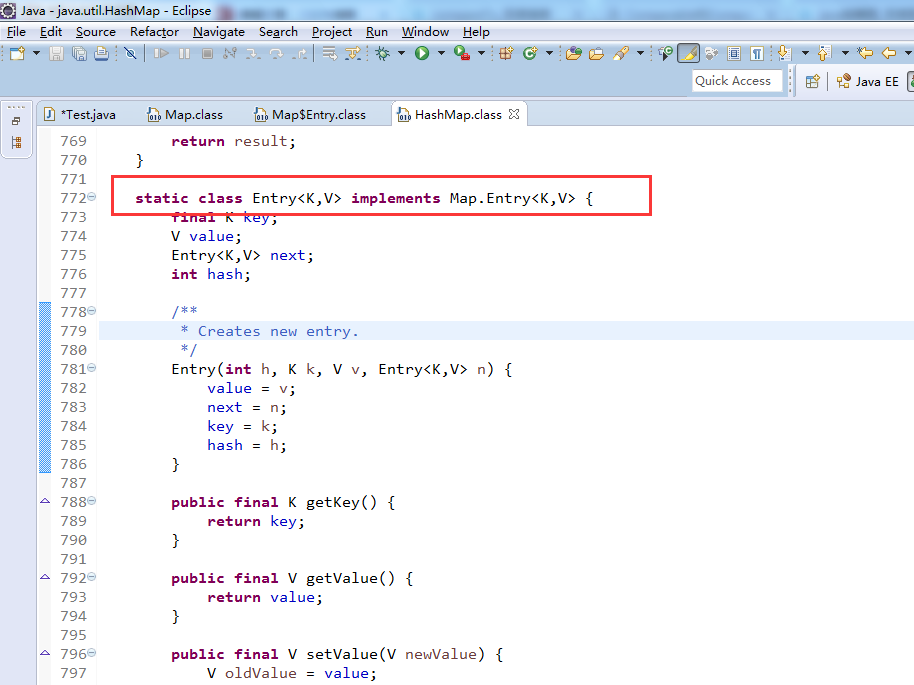
但是为什么这么做呢,我的理解是,因为得容器里先有元素(也就是key,value)才有关系,
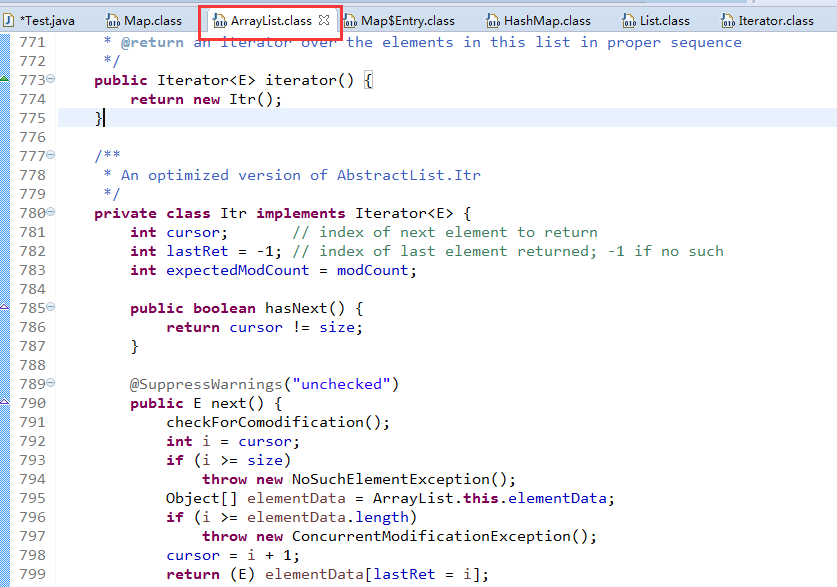
而且具体的到底怎么取出这个关系,具体的容器它自己最清楚,所以就定义在了容器的内部,我觉得这个和Collection接口里的Iterator迭代器原理差不多,迭代器估计从JDK1.5以后出现了高级for以后大家用的少了,有时间大家可以看看,我觉得刚才说的那个和Collection接口和它内部的Iterator迭代器很类似。看下边的图,去ArrayList源码看一下,里边也是有一个内部类实现了Iterator接口的。
我理解的就是Map和Map.Entry<K,V>的关系就和LIst和Iterator的关系一样。我是这么理解的。
我理解的就是Map和Map.Entry<K,V>的关系就和LIst和Iterator的关系一样。我是这么理解的。
好啦,多的不说了,下面代码演示一下
package com.cj.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
*
* @author caoju
*
*/
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("001", "zhangsan1");
map.put("002", "lisi");
map.put("003", "wangwu");
Set<Map.Entry<String, String>> es = map.entrySet();
for (Map.Entry<String, String> e : es) {
String key = e.getKey();
String value = e.getValue();
System.out.println(key+":"+value);
}
}
}
可以看到两种方式结果一样的,但是在Map的内部它具体的实现是不一样的。
好了,今天就到这儿吧
以上写的仅仅是自己的理解,供大家参考,若有错误的地方希望大家包涵并及时指出,3Q
晚安
