1. SparkStreaming简介
SparkStreaming是流式处理框架,7*24小时运行。是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理;
实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。
最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
总的来说,流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低。因此,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎。对于一个流计算系统来说,它应达到如下需求。
* • 高性能。处理大数据的基本要求,如每秒处理几十万条数据。
* • 海量式。支持TB级甚至是PB级的数据规模。
* • 实时性。必须保证一个较低的延迟时间,达到秒级别,甚至是毫秒级别。
* • 分布式。支持大数据的基本架构,必须能够平滑扩展。
* • 易用性。能够快速进行开发和部署。
* • 可靠性。能可靠地处理流数据。
目前,市场上有很多流计算框架,比如Twitter Storm和Yahoo! S4等。Twitter Storm是免费、开源的分布式实时计算系统,可简单、高效、可靠地处理大量的流数据;Yahoo! S4开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统。
流计算处理过程包括数据实时采集、数据实时计算和实时查询服务。
* 数据实时采集:数据实时采集阶段通常采集多个数据源的海量数据,需要保证实时性、低延迟与稳定可靠。以日志数据为例,由于分布式集群的广泛应用,数据分散存储在不同的机器上,因此需要实时汇总来自不同机器上的日志数据。目前有许多互联网公司发布的开源分布式日志采集系统均可满足每秒数百MB的数据采集和传输需求,如Facebook的Scribe、LinkedIn的Kafka、淘宝的TimeTunnel,以及基于Hadoop的Chukwa和Flume等。
- 数据实时计算:流处理系统接收数据采集系统不断发来的实时数据,实时地进行分析计算,并反馈实时结果。
- 实时查询服务:流计算的第三个阶段是实时查询服务,经由流计算框架得出的结果可供用户进行实时查询、展示或储存。
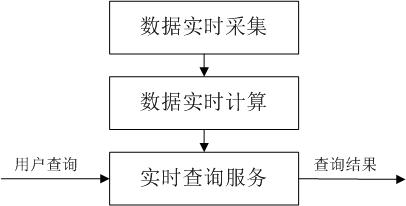
图 流计算的数据处理流程
2. SparkStreaming与Storm的区别
1. Storm是纯实时的流式处理框架,SparkStreaming是准实时的处理框架(微批处理即:处理存储一段时间的数据并不是完全实时流处理)。
因为微批处理,SparkStreaming的吞吐量比Storm要高。
2. Storm 的事务机制要比SparkStreaming的要完善。
3. Storm支持动态资源调度。(SparkStreaming1.2之后也支持)
4. SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总型计算。
Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应。
3.Spark Streaming的基本原理
是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据,执行流程如下图所示。
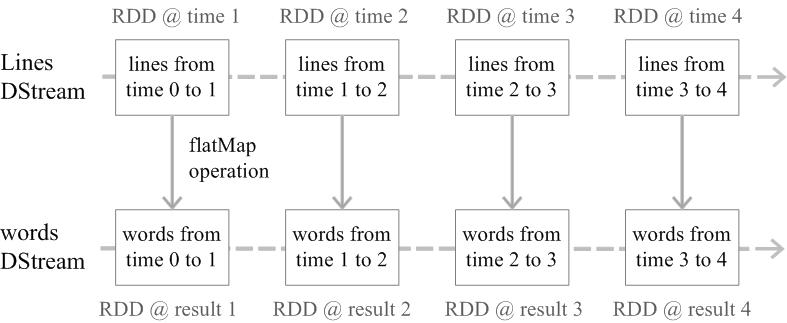
Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段的DStream,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终转变为对相应的RDD的操作。例如,下图展示了进行单词统计时,每个时间片的数据(存储句子的RDD)经flatMap操作,生成了存储单词的RDD。整个流式计算可根据业务的需求对这些中间的结果进一步处理,或者存储到外部设备中。
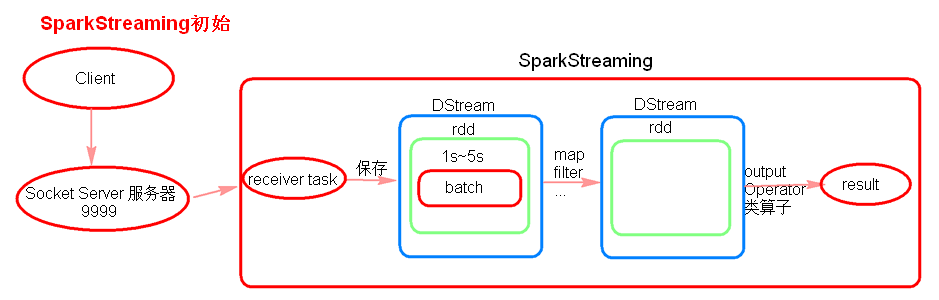
注意:
--receiver task是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中,RDD最终封装到一个DStream中。
例如:假设batchInterval为5秒,每隔5秒通过SparkStreamin将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6~9秒一边在接收数据,一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作。
SparkSream操作基于的是DStream,DStream也有Transformation类算子,也是懒加载;要使用DStream中的Output Operator类算子去触发执行。
-- 如果job执行的时间大于batchInterval会有什么样的问题?
如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟 )。Sparkstreaming的最优方案就是job的执行时间等于batchinternal。
示例:
/**
* 模拟在线统计每次输入的单词个数
*
*/
public class WordCountOnline {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline");//local[2]
//JavaSparkContext sc=new JavaSparkContext(conf);
/**
* 在创建streaminContext的时候 设置batch Interval
*/
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));//JavaStreamingContext创建的两种方式 1、SparkConf 2、JavaSaprkContext
//JavaStreamingContext jsc = new JavaStreamingContext(sc, Durations.seconds(5));
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("weekend10",9999);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public Iterable<String> call(String lines) throws Exception {
return Arrays.asList(lines.split(" "));
}});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}});
JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}});
counts.print();
jsc.start();
jsc.awaitTermination();
/**
* JavaStreamingContext.stop()无参的stop方法会将sparkContext一同关闭,stop(false)
*/
jsc.stop(false);
jsc.close();
}
}
1)如果要运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象,它是Spark Streaming程序的主入口。因此,在定义输入之前,我们首先介绍如何创建StreamingContext对象。我们可以从一个SparkConf对象创建一个StreamingContext对象。
2)setAppName("TestDStream")是用来设置应用程序名称,这里我们取名为“WordCountOnline”。setMaster("local[2]")括号里的参数"local[2]'字符串表示运行在本地模式下,并且启动2个工作线程。

在weekend0节点上启动scoketServer
nc -lk 9999 如果nc命令不识别;需要通过yum安装nc
运行程序后在weekend10节点上启动ScoketServer 输入数据Enter查看UI界面
