一、什么是大数据?
大数据是适应时代的产物,在我们的生活中应用也很广泛。首个提出大数据概念的是:麦肯锡。
大数据的数据计量单位已经越过了TB级别,发展到了PB、EB、ZB、YB、BB来衡量。
二、大数据的特征是什么?
大数据有四个方面的典型特征:大量(Volume)、多样(Varity)、高速(Velocity)、价值(Value)。
- 大数据处理的数据是大量的;
- 大数据处理的数据是多样的;
- 使用计算机处理数据是高速的;
- 通过大数据对大量的数据进行分析,可以得到有价值的信息。
- 大数据对数据的实时性要求较高,而且,大数据由于数据庞大,所以有很多没有价值的数据,因此,数据处理效率相对来说不高。
三、研究大数据的意义是什么?
研究大数据最重要的意义是预测。通过对大量数据的分析,建立数据思维模型,从而对未来进行推测和预测。
四、大数据有哪些应用场景?
医疗行业、金融行业、零售行业都可以很好的应用到大数据。
五、什么是hadoop?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
六、hadoop的优势是什么?
- 扩容能力强:内存可以进行横向扩展;
- 成本低:hadoop集群可以由一些廉价的计算机组成;
- 高效率:hadoop集群有很高的数据吞吐量和高效的数据处理能力;
- 可靠性:hadoop集群上的副本机制,可以很好的保证数据的安全;
- 高容错性:hadoop集群可以容忍错误的发生,少量的计算机出错不会影响整体运行,而且hadoop集群含有纠错机制。
七、hadoop的生态系统
随着hadoop的发展,hadoop现在有一个庞大的生态体系
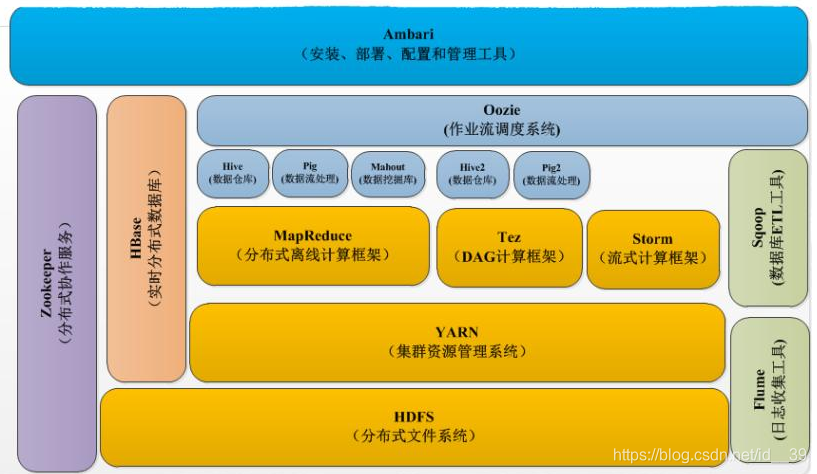
- HDFS(分布式文件系统):是hadoop生态系统核心项目之一,是分布式计算中数据存储管理基础;
- MapReduce(分布式计算框架):是一种计算模型,用于大规模数据集(大于1TB)的并行运算;
- Yarn(资源管理框架):是hadoop2.0中的资源管理器,可为上层应用提供统一的资源管理和调度;
- Sqoop(数据迁移工具):开源的数据导入导出工具,主要用于hadoop与传统数据库(mysql等)间进行数据的转换;
- Mahout(数据挖掘算法库):apache旗下的一个开源项目,提供了一些可扩展的机器学习领域经典算法的实现,帮助开发人员方便快捷地创建智能应用程序;
- HBase(分布式存储系统):是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库;
- Zookeeper(分布式协作服务):是一个分布式的,开放源码的分布式应用程序协调服务;
- Hive(基于Hadoop的数据仓库):Hive是基于Hadoop的一个分布式数据仓库工具,可以将结构化的数据文件映射为一张数据库表,将SQL语句转换为MapReduce任务进行运行;
- Flume(日志手机工具):是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集,聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据,同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
