SparkStreaming的核心思路:
把无边界的数据流抽象成DStream,在时间方向上,按照某个指定的时间间隔,把DStream切割成一个离散的RDD的序列,然后每一个都交给spark执行引擎进行处理。
SparkStreaming在内部的处理机制是,接收实时流的数据,并根据一定时间间隔拆分成一批批的数据,然后通过SparkEngine处理这些数据,最终得到处理后的一批批结果数据。对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。
总结:SparkStreaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据。
SparkStreaming的核心概念:
1、DStream
2、Operation(transformation,output,updateStateByKey,transform,window,foreachRDD)
3、StreamingContext
4、InputDStream & Receiver
SparkStream核心术语
1、离散流(discretized stream)或DStream:这是sparkstreaming对内部持续的实时数据流的抽象描述,即我们处理的一个实时数据流,在sparkStreaming中对应于一个DStream实例
2、批数据(batch data):这是化整为零的第一步,将实时流数据以时间片为单位进行分批,将流处理转化为时间片数据的批处理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流。
3、时间片或批处理时间间隔(batch interval):这是人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个RDD实例。
4、窗口长度(window length):一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数。
5、滑动时间间隔:前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。
6、Input DStream:一个InputDStream是一个特殊的DStream,将SparkSteaming连接到一个外部数据源来读取数据。
SparkStreaming的编程套路:
1、获取编程入口:StreamingContext
2、通过StreamingContext构建第一个DStream
3、对于DStream进行各种transformation操作
4、对于结果数据进行output操作
5、提交SparkStreaming应用程序:StreamingContext.start()和StreamingContext.awaitTermiantion()
当创建完成StreamingContext之后,再按照下列步骤进行:
(1)通过输入源创建InputDStream
(2)对DStream进行transformation和output操作,这样操作构成了后期流式计算的逻辑
(3)通过streamingContext.start()方法启动接收和处理数据的流程
(4)使用streamingContext.awaitTermination()方法等待程序结束(手动停止或出错停止)
(5)也可以调用streamingContext.stop()方法结束程序的运行(一般不这么干)
SparkStreaming数据源
1、Basic Sources(基础数据源)
直接通过StreamingContext API创建,例如文件系统(本地文件系统即分布式文件系统)。Socket连接及Akka的Actor
2、Advanced Sources(高级流数据源)
如Kafka,flume,kinesis,Twitter等,需要借助外部工具类,在运行时需要外部依赖
3、Custom Sources(自定义流数据源)
SparkStreaming还支持用户自定义数据源,需要用户自定义receiver
checkpoint
1、checkpoint的数据的类型:元数据;RDD数据
2、合适启用checkpoint:
(1)有状态计算:updateStateByKey,window计算
(2)如果有需要对driver进行HA
3、如何配置checkpoint
(1)streamingContext.checkpoint(hdfspath)
(2)def functionToCreateStreamingContext:StreamingContext
StreamingContext.getOrCreate(chkDir,functionToCreateStreamingContext _)
window
黑名单;白名单
checkpoint有两种类型的数据:
1、Metadata checkpoint
将定义streaming计算的信息保存到容错存储(hdfs)中,用于从运行streaming应用程序的driver的节点的故障中恢复。
元数据包括:
Configuration -用于创建流应用程序的配置
DStream operations -定义streaming应用程序的DStream操作集
Incomplete batches -批量的job排队但尚未完成
2、Data checkpoint
将生成的RDD保存到可靠的存储,在一些多个批次之间的数据进行组合的状态变换中是必需的。
何时启用checkpoint:
1、使用状态转换-如果应用程序中使用updateStateByKey或reduceByKeyAndWindow(具有反向功能),必须checkpoint
2、从运行应用程序的driver的故障中恢复-元数据checkpoint用于使用进度信息进行恢复
总结
第一部分
1、sparkstreaming
mapreduce:基于离线数据进行设计
storm:基于流式数据进行设计
spark streaming:基于一个离线处理编程模型进行再次抽象设计,spark core。
把离线看作是所有任务的通用类型,把流式处理看着是所有数据处理的特例。
flink:底层设计思想根据storm是类似的。也可以进行批处理(流批处理)。
把流式看做是所有任务的通用类型,把离线处理看做是所有数据处理的特例。
2、sql + stream
3、spark streaming的核心设计思路:
(1)把无边界的数据流看做是一个整体,抽象成为一个DStream。把DStream在时间片方向上进行按照某个时间进行切分,让无边界的DStream数据流可以变成一个离散的RDD序列。这样就可以把流式处理的任务变成是一批连续的离散的离线处理任务。
(2)sparkstreaming的核心概念:
DStream
StreamingContext
Operator
transformation:
updateStateByKey
window
foreachRDD
transform
output:
println
saveAsTextFile
InputDStream和Receiver
数据接收器
4、spark的application(driver + 多个executor组成)
所有的流式处理,都有相同的业务难题:
对于数据消费有三种语义:
(1)at most once:最多一次,有可能会漏消费
(2)at least once:最少一次,有可能会重复消费
(3)exactly once:有且仅一次,效率低
5、sparkStreaming + kafka
https://blog.csdn.net/zhongqi2513/article/details/81356402

-1、基于接收者的方式
算子:KafkaUtils.createStream
方法:PUSH,从topic中去推送数据,将数据推送过来
API:调用的Kafka高级API
效果:SparkStreamng中的Receivers,恰好Kafka有发布/订阅,然而,此种方式企业不常用。因为,接收到的数据存储在Executor的内存,会出现数据漏处理状况。
Receive原理:接收数据先形成buffer,然后构建成block,最后形成RDD,默认情况下这些数据都是保存在内存中的。
rdd的分区数:task的个数
sparkCore应用程序中每次处理的就是一个原始RDD,经过多次转换操作之后就会形成一个DAG
DAGScheduler会对这个DAG进行stage划分
每一个stage中的task的数量,都是由这个stage中的最后一个RDD的分区数来决定
Kafka的分区数 — 基于Receiver中的方式 — rdd的分区数不一致,没有对应关系
缺点:必须用户要了解数据规模和Kafka的分区信息,才能决定到底应该启动多少个task的任务去执行才合适
解释:这种方式使用Receiver来接收数据。Receiver是使用Kafka高级消费者API来实现的。与所有的接收者一样,通过Receiver从Kafka接收的数据存储在Spark执行程序executor中,然后由Spark Streaming启动的作业处理数据。但是,在默认配置下,这种方法可能会在失败是丢失数据。为了确保零数据丢失,必须在Spark Streaming(Spark1.2引入)中额外启用写入日志(WAL),同时保存所有接收到的Kafka数据写入分布式文件系统(HDFS)的预先写入日志,以便所有数据都可以在失败时恢复。
缺点:
(1)Kafka中的主题分区与Spark Streaming中生成的RDD的分区不相关。因此,增加主题特定分区KafkaUtils.createStream()的数量只会增加在单个接收器中使用哪些主题消耗的线程的数量。在处理数据时不会增加Spark的并行性
(2)多个Kafka输入到DStream会创建多个group和topic,用于使用多个接收器并行接收数据
(3)如果已经使用HDFS等分布式文件系统启用写入日志,则接收到的数据已经在日志中复制。因此,输入流的存储级别为StorageLevel.MEMORY_AND_DISK_SER
(4)Kafka的分区数和SparkSteaming应用程序中生成的RDD的分区数据不是对应的。所以增加Kafka的topic的分区数,仅仅只能给每个接收数据的Receiver的消费者增加线程,并没有增加SparkStreaming消费数据的并行度
-2、直接方式(无接收者)
算子:KafkaUtils.createDirectStream
方式:PULL,到topic中去拉取数据
API:Kafka低级API
效果:每次到topic的每个分区依据偏移量进行获取数据,拉取数据以后进行处理,可以实现高可用
解释:在Spark1.3中引入了这种新的无接收器"直接"方法,以确保更强大的端到端保证。这种方法不是使用接收器来接收数据,而是定期查询Kafka在每个topic + 分区中的最新偏移量,并相应地定义要在每个批次中处理的偏移量范围。当处理数据的作业启动时,Kafka简单的客户API用于读取Kafka中定义的偏移量范围(类似于从文件系统读取文件)。注意,此功能在Spark1.3中为Scala和Java API引入,在Spark1.4中针对Python API引入。
优势:
(1)简化并行性:不需要创建多个输入Kafka流并将其合并。与此同时directStream,SparkStreaming将创建与使用Kafka分区一样多的RDD分区,这些分区全部从Kafka并行读取数据。所以在Kafka和RDD分区之间有一对一的映射关系,这更容易理解和调整。
(2)效率:在第一种方式中实现零数据丢失需要将数据存储在预写日志中,这会进一步复制数据。实际上效率是低下的,因为数据被有效复制了两次,一次由Kafka,另一次是由预写日志(Write Ahead Log)复制。此方法消除了这个问题,因为没有接收器,因此不需要预先写入日志。只要有足够的Kafka保留,消息可以从Kafka恢复。
(3)精确语义:第一种方法是使用Kafka的高级API在Zookeeper中存储消耗的偏移量。传统上是从Kafka消费数据的方式。虽然这种方法(合并日志)可以确保零数据丢失,但在某些失败情况下,很小的概率两次数据都同时丢失,发生这种情况是因为SparkStreaming可靠接收到的数据与Zookeeper跟踪的偏移量之间的不一致。因此,在第二种方法中,我们使用不使用Zookeeper的简单Kafka API。在其检查点内,SparkStreaming跟踪偏移量。这消除了SparkStreaming和Zookeeper/Kafka之间的不一致性,因此,SparkStreaming每次记录都会在发生故障时有效的接收一次。
注意,这种方法(direct)的一个缺点时它不会更新zookeeper中的偏移量,因此基于zookeeper的Kafka监控工具将不会显示进度。但是,可以在每个批次中访问由此方法处理的偏移量,并自己更新zookeeper。
为了实现输出结果的exactly once的语义,将数据保存到外部数据存储的输出操作必须是幂等性的,或者保存结果和offset的原子事务。
Direct方式:
没有Recevier,没有必要去启用WAL机制,任务的处理性能有提升
SparkStreaming的task数量刚好和Kafka的分区数一样
Kafka有多少分区,对应的消费者sparkStreaming程序就会创建对应数量的task数
刚好sparkStreaming程序中一个线程对应一个Kafka的分区
Kafka一个分区的最新数据,就是追加在一个文件的末尾
一个消费者线程也刚好对应一个磁盘文件(一个分区)
SparkStreaming的调优:
发现下游的SparkStreaming的性能过剩,可以调高Kafka的分区数
6、问题
(1)重复消费,至少保证不丢失数据,如何解决重复问题?
(2)Kafka的topic有p0,p1,p2三个分区,key = null,数据并没有打散,如何将数据打散?
(3)业务逻辑顺序:insert;update;delete。SparkStreaming是并行的,如何保证消费有序?
(4)offset存起来,存哪里?
http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
Storing Offsets
Checkpoints—>HDFS:小文件合并
http://spark.apache.org/docs/latest/streaming-programming-guide.html#checkpointing
Your own data store
业务维护太麻烦:Zookeeper或者HBase
(github搜索spark streaming kafka offset hbase)
https://github.com/wangliangbd/SparkStreaming_Store_KafkaTopicOffset_To_HBase
Kafka itself
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
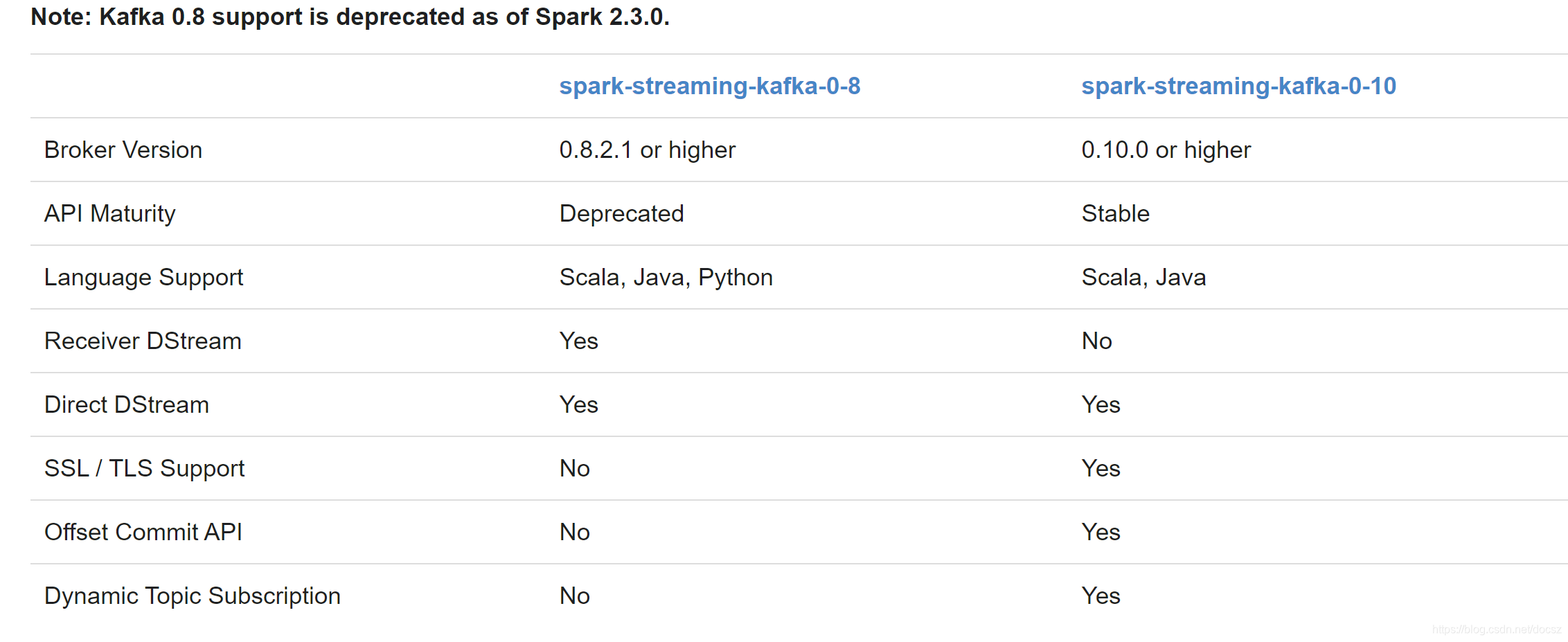
7、Spark-Streaming-Kafka版本区别
http://spark.apache.org/docs/latest/streaming-kafka-integration.html