author:DivinerShi
对抗网络是14年Goodfellow Ian在论文Generative Adversarial Nets中提出来的。
记录下自己的理解,日后忘记了也能用于复习。
本文地址:
http://blog.csdn.net/sxf1061926959/article/details/54630462
生成模型和判别模型
理解对抗网络,首先要了解生成模型和判别模型。判别模型比较好理解,就像分类一样,有一个判别界限,通过这个判别界限去区分样本。从概率角度分析就是获得样本x属于类别y的概率,是一个条件概率P(y|x).而生成模型是需要在整个条件内去产生数据的分布,就像高斯分布一样,他需要去拟合整个分布,从概率角度分析就是样本x在整个分布中的产生的概率,即联合概率P(xy)。具体可以参考博文http://blog.csdn.net/zouxy09/article/details/8195017
对抗网络思想
理解了生成模型和判别模型后,再来理解对抗网络就很直接了,对抗网络只是提出了一种网络结构,总体来说,整个框架还是很简单的。GANs简单的想法就是用两个模型,一个生成模型,一个判别模型。判别模型用于判断一个给定的图片是不是真实的图片(从数据集里获取的图片),生成模型的任务是去创造一个看起来像真的图片一样的图片,有点拗口,就是说模型自己去产生一个图片,可以和你想要的图片很像。而在开始的时候这两个模型都是没有经过训练的,这两个模型一起对抗训练,生成模型产生一张图片去欺骗判别模型,然后判别模型去判断这张图片是真是假,最终在这两个模型训练的过程中,两个模型的能力越来越强,最终达到稳态。(这里用图片举例,但是GANs的用途很广,不单单是图片,其他数据,或者就是简单的二维高斯也是可以的,用于拟合生成高斯分布。)
详细实现过程
下面我详细讲讲:
假设我们现在的数据集是手写体数字的数据集minst。
初始化生成模型G、判别模型D(假设生成模型是一个简单的RBF,判别模型是一个简单的全连接网络,后面连接一层softmax)这些都是假设,对抗网络的生成模型和判别模型没有任何限制。
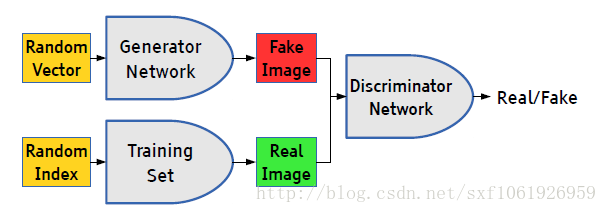
前向传播阶段
一、可以有两种输入
1、我们随机产生一个随机向量作为生成模型的数据,然后经过生成模型后产生一个新的向量,作为Fake Image,记作D(z)。
2、从数据集中随机选择一张图片,将图片转化成向量,作为Real Image,记作x。
二、将由1或者2产生的输出,作为判别网络的输入,经过判别网络后输入值为一个0到1之间的数,用于表示输入图片为Real Image的概率,real为1,fake为0。
使用得到的概率值计算损失函数,解释损失函数之前,我们先解释下判别模型的输入。根据输入的图片类型是Fake Image或Real Image将判别模型的输入数据的label标记为0或者1。即判别模型的输入类型为 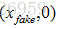

判别模型的损失函数:
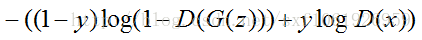
当输入的是从数据集中取出的real Iamge 数据时,我们只需要考虑第二部分,D(x)为判别模型的输出,表示输入x为real 数据的概率,我们的目的是让判别模型的输出D(x)的输出尽量靠近1。
当输入的为fake数据时,我们只计算第一部分,G(z)是生成模型的输出,输出的是一张Fake Image。我们要做的是让D(G(z))的输出尽可能趋向于0。这样才能表示判别模型是有区分力的。
相对判别模型来说,这个损失函数其实就是交叉熵损失函数。计算loss,进行梯度反传。这里的梯度反传可以使用任何一种梯度修正的方法。
当更新完判别模型的参数后,我们再去更新生成模型的参数。
给出生成模型的损失函数:
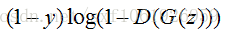
对于生成模型来说,我们要做的是让G(z)产生的数据尽可能的和数据集中的数据一样。就是所谓的同样的数据分布。那么我们要做的就是最小化生成模型的误差,即只将由G(z)产生的误差传给生成模型。
但是针对判别模型的预测结果,要对梯度变化的方向进行改变。当判别模型认为G(z)输出为真实数据集的时候和认为输出为噪声数据的时候,梯度更新方向要进行改变。
即最终的损失函数为: 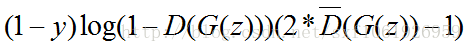
其中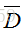
反向传播
我们已经得到了生成模型和判别模型的损失函数,这样分开看其实就是两个单独的模型,针对不同的模型可以按照自己的需要去是实现不同的误差修正,我们也可以选择最常用的BP做为误差修正算法,更新模型参数。
其实说了这么多,生成对抗网络的生成模型和判别模型是没有任何限制,生成对抗网络提出的只是一种网络结构,我们可以使用任何的生成模型和判别模型去实现一个生成对抗网络。当得到损失函数后就安装单个模型的更新方法进行修正即可。
原文给了这么一个优化函数: 
算法流程图
下图是原文给的算法流程,noise 就是随机输入生成模型的值。上面的解释加上这个图应该就能理解的差不多了。

noise输入的解释
上面那个noise也很好理解。如下图所示,假设我们现在的数据集是一个二维的高斯混合模型,那么这么noise就是x轴上我们随机输入的点,经过生成模型映射可以将x轴上的点映射到高斯混合模型上的点。当我们的数据集是图片的时候,那么我们输入的随机噪声其实就是相当于低维的数据,经过生成模型G的映射就变成了一张生成的图片G(x)。 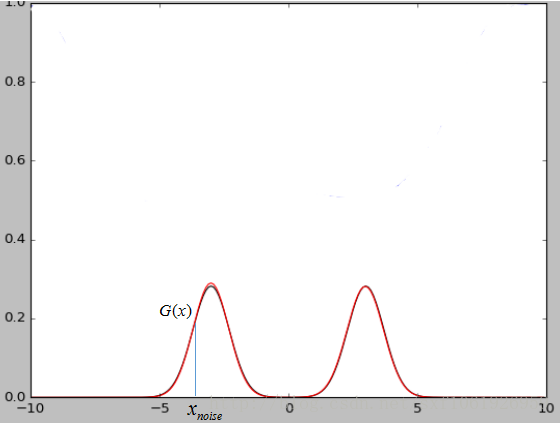
原文中也指出,最终两个模型达到稳态的时候判别模型D的输出接近1/2,也就是说判别器很难判断出图片是真是假,这也说明了网络是会达到收敛的。
GANs review
GANs一些新的应用在这篇博文中有所介绍,写的挺好:
https://adeshpande3.github.io/adeshpande3.github.io/Deep-Learning-Research-Review-Week-1-Generative-Adversarial-Nets
*####################################################
比如使用拉普拉斯金字塔做图片细化,将之前的单个输入,改成金字塔类型的多层序列输入,后一层在前一层的基础上进行上采样,使得图片的精细程度越来越高
*#####################################################
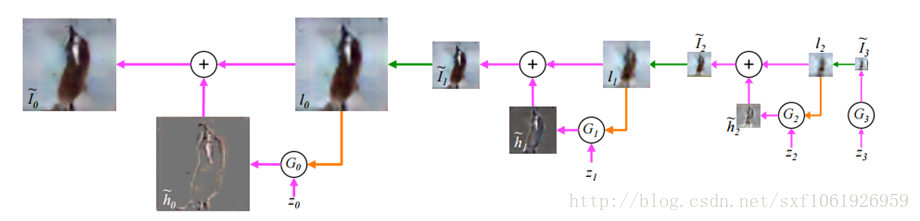
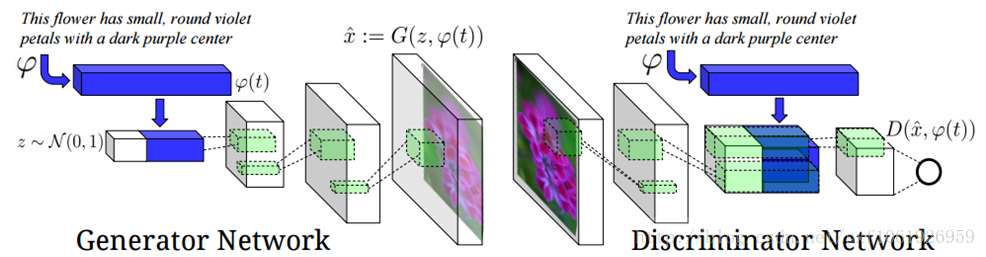
使用GANs实现将描述文本转化成图片,在模型中输入一段文本,用于表示一张图片,引入了一些NPL的概念,特别有意思的idea。网络结构如下图所示:
*#####################################################

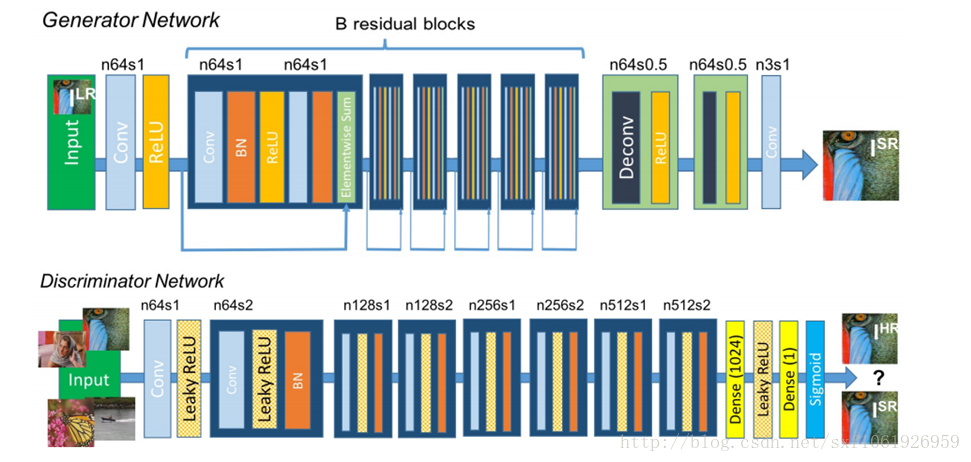
GANs做超像素,对模糊图片做去噪,和resnet做了结合,结构入选图
实验效果如下图所示:
*#####################################################

demo 代码
GANs的demo上github搜下,挺多的,可以参考一个比较简单的
https://github.com/Shicoder/DeepLearning_Demo/tree/master/AdversarialNetworks
Goodfellow自己原文的代码:
https://github.com/goodfeli/adversarial
优缺点,模型性能:
具体模型的优缺点以及模型的性能可以参考Ian Goodfellow的Quora答疑。
参考文献:
[1]https://adeshpande3.github.io/adeshpande3.github.io/Deep-Learning-Research-Review-Week-1-Generative-Adversarial-Nets
[2]https://github.com/MatthieuBizien/AdversarialNetworks
[3]Goodfellow Ian, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems. 2014: 2672-2680.
[4]https://github.com/goodfeli/adversarial
[5]http://chuansong.me/n/853959751260
[6]http://blog.csdn.net/solomon1558/article/details/52338052
感谢叶博的细心指导
完