论文地址:https://arxiv.org/abs/1411.1784
关于生成式对抗网络(GAN)在先前的文章中已经提到了。请看我的前两篇博文。
https://blog.csdn.net/qq_21210467/article/details/81836976
https://blog.csdn.net/qq_21210467/article/details/81942447
现在来说说条件生成式对抗网络CGAN。
一、背景:
GAN的优势是直接可以对数据分布进行采样,不需要假设数据分布,从而理论上可以完全逼近真实数据。但是这中间膜的方式全点是过于自由,对于较大的图片和复杂的数据,简单的GAN变得非常不可控,于是研究人员提出了条件生成式对抗网络理论Conditional Generative Adversarial Nets(CGAN)【Mirza M, Osindero S. Conditional】,对原始的GAN附加了约束,在生成模型和判别模型中引入了条件变量y(Conditional variable y),为模型引入了额外的信息,可指导性的生成数据。理论上y可以使有意义的各种信息,比如类标签,可以将GAN这种无监督学习的方法变成若监督或者是有监督的。并且在MNIST数据集上取得了不错的效果:

同时,作者还探索了CGAN在用于图像自动标注的多模态学习上的应用,并且在MIR Flickr25000数据集上,以图像特征为条件变量生成了图像的tag词向量。

二、GAN和CGAN
GAN优化函数:
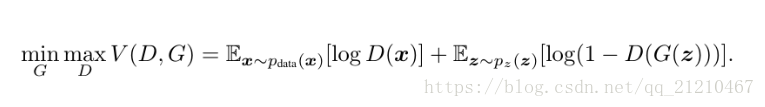
CGAN优化函数:
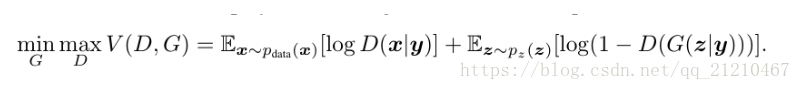
从上面可以看到,GAN和CGAN的区别只是多了一个约束条件y。y可以是其他任意的辅助信息,比如类型标签和其他的数据类型,我们可以通过将y作为附加输入层馈入鉴别器和发生器来执行调节。
三、实验部分
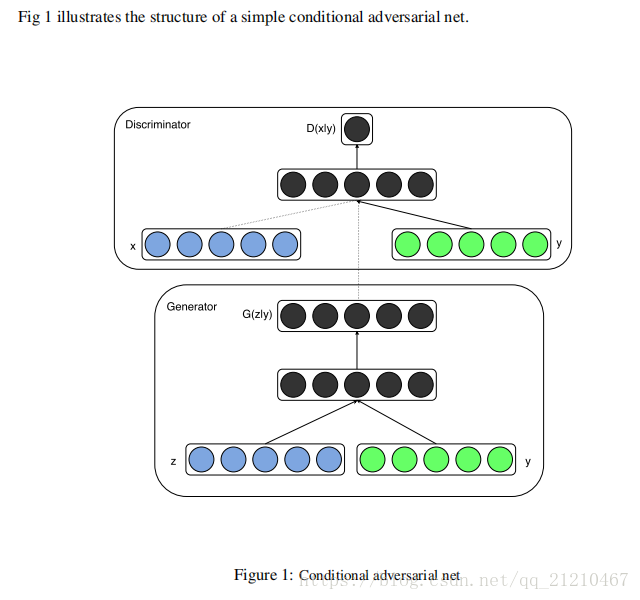
1、MNIST数据集实验
y:类别标签,转换为one-hot编码。如【0,0,0,1,0,0,0,0,0,0】。
生成器G:输入是100维的噪声z和one-hot的标签y,噪声来源于均匀分布的采样。都以ReLU函数作为激活函数,噪声z和标签y分别映射到200个单元和1000个单元的隐层。然后拼接成一个1200维的特征向量经过ReLU作为下一层输入,最后用了一个sigmoid函数作为输出层的的激活函数用于分类,产生了一个784维的MNIST样本(28*28)。
判别器D:输入是784维数据和one-hot编码的条件y,输出是该样本来自于训练集的概率。使用了maxout处理(Maxout Networks )效果非常好。
2、MIR Flickr 25000数据集
这个数据集用于论文中的多模态实验。MIR Flickr 25000是一个图像有着丰富标签的数据集,这些标签有很多user-generated- matadata/user-tag ,user-tag的优点很多标签是由多个人来描述,因此,标签有很大的关联性,不同的人来描述一张图片会得到很多同义词,对数据起到了不错的效果。
这个实验里面,作者的目的是实现图像的自动标注(多标签预测)。使用了整个ImageNet(21000个标签)数据预训练了一个卷积模型,利用了最后的一个全连接层的4096个单元作为图像特征。在word representation上从YFCC100M数据集中收集了一些列的user-tag,标题和描述并且聚合成了一个语料库,在进行了预处理和数据清洗之后训练了一个词向量是200的gram-skip 模型。实验中使用了上述两个模型来提取Flicks数据集中的图片和tag特征,然后用来训练CGAN,最终的结果表明有不错的结果。
结构:因为没做实验,所以略过。
四、代码分析
repository请移步至我的github:https://github.com/MrRenQIANG/GANs 文件名为my_cgan_tensorflow.py就是今天的内容。
首先是数据和超参,根据自己的实际路径做修改即可:

然后是,初始化权重

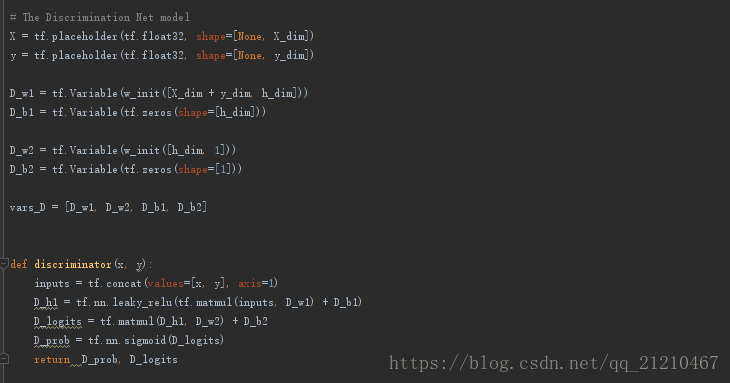
定义判别器的结构
生成器的结构
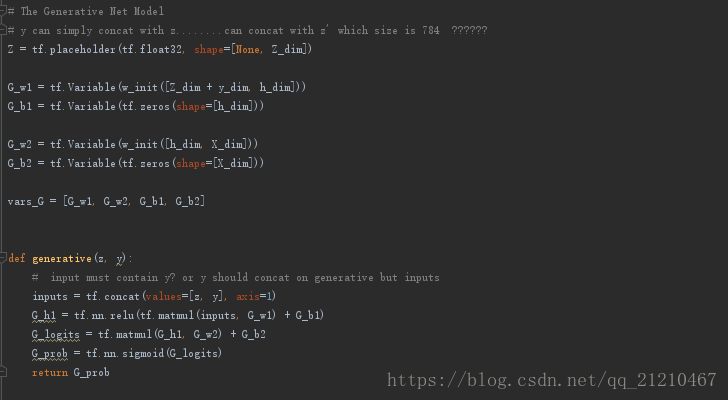
采样以及可视化
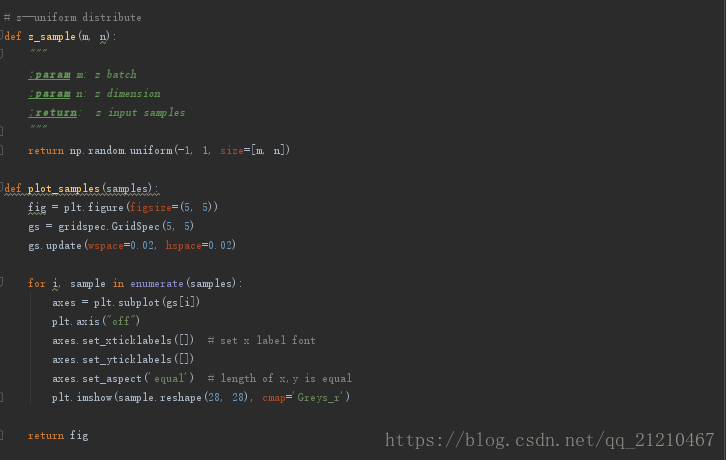
判别器和生成器的损失函数,以及tensorboard可视化
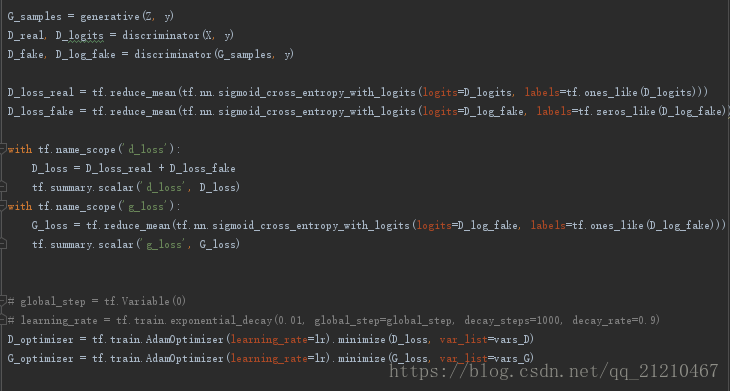
生成路径
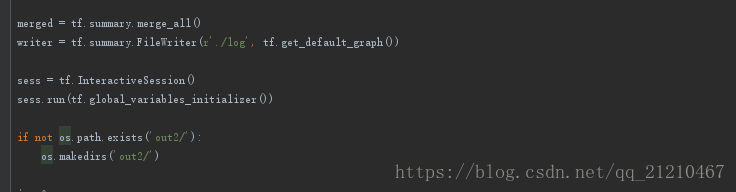
训练:
执行结果:指定生成标签维5的数据(效果不太好)

判别器和生成器的loss变化:
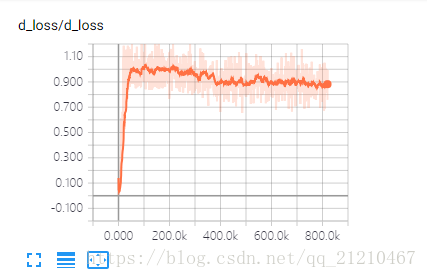
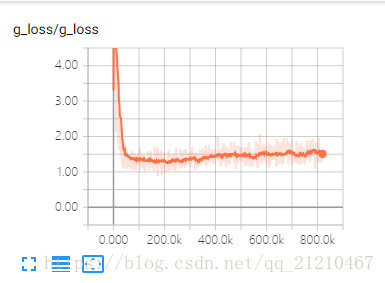
训练的结果是判别器和生成器的loss都不在有大的变化,训练前期两者相互对抗,所以会出现d_oss上升的同时g_loss在下降。最终二者区域平缓。但是我还是想说:图中的效果不是特别理想,归结于超参数的设置问题。
版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/qq_21210467/article/details/82077862