1.介绍
论文:Conditional Generative Adversarial Nets
论文地址:https://arxiv.org/abs/1411.1784
针对原始GAN的缺点:生成的图像是随机的,不可预测的,无法控制网络输出特定的图片,生成目标不明确,可控性不强等问题。
改进方法:cGAN的中心思想是希望可以控制 GAN 生成的图片,而不是单纯的随机生成图片。 Conditional GAN 在生成器和判别器的输入中增加了额外的条件信息,生成器生成的图片只有足够真实且与条件相符,才能够通过判别器。其核心在于将属性信息融入生成器G和判别器D中,属性可以是任何标签信息, 例如图像的类别、人脸图像的面部表情等。
2.模型结构
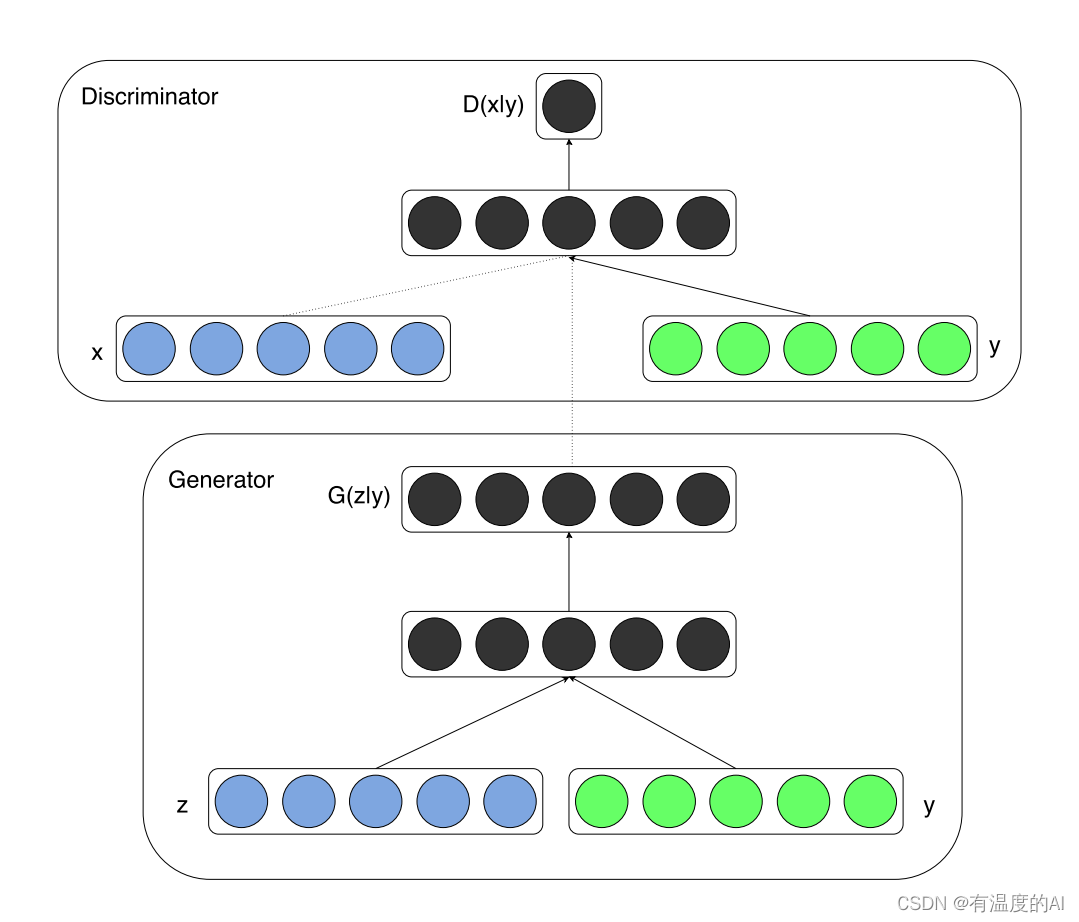
在判别器和生成器中都添加了额外信息y,y可以是类别标签或者是其他类型的数据,可以将y作为一个额外的输入层引入判别器和生成器。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, datasets, utils
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from torchvision.datasets import ImageFolder
import tqdm
ROOT_TRAIN = r'D:\CNN\AlexNet\data1\train'
def one_hot(x, num_class=2): #转化为独热标签
return torch.eye(num_class)[x, :]
train_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform, target_transform=one_hot) # 加载训练集
dataloader = torch.utils.data.DataLoader(train_dataset,
batch_size=64,
shuffle=True,
num_workers=0)
# print(train_dataset[0]) #返回数据和标签, 引入one_hot编码后,标签就为长度为num_class的tensor tensor([1., 0.]
# 定义生成器,输入是长度为100的噪声(正态分布随机数),和标签独热编码(condition)
# 输出为3*224*224的图片(tensor)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = nn.Linear(100, 128*56*56)
self.bn1 = nn.BatchNorm1d(128*56*56)
self.linear2 = nn.Linear(2, 128*56*56)
self.bn2 = nn.BatchNorm1d(128*56*56)
self.deconv1 = nn.ConvTranspose2d(256, 128,
kernel_size=(3, 3),
stride=1,
padding=1) #128*56*56
self.bn3 = nn.BatchNorm2d(128)
self.deconv2 = nn.ConvTranspose2d(128, 64,
kernel_size=(4, 4),
stride=2,
padding=1) # 64*112*112
self.bn4 = nn.BatchNorm2d(64)
self.deconv3 = nn.ConvTranspose2d(64, 3,
kernel_size=(4, 4),
stride=2,
padding=1) # 3*224*224
def forward(self, x1, x2): #x1为噪声输入,x2标签独热编码输入(condition)
x1 = F.relu(self.linear1(x1)) #100 -- 128*56*56
x1 = self.bn1(x1)
x2 = F.relu(self.linear2(x2)) #num_class -- 128*56*56
x2 = self.bn2(x2)
x1 = x1.view(-1, 128, 56, 56)
x2 = x2.view(-1, 128, 56, 56)
x = torch.cat([x1, x2], dim=1) #256*56*56
x = F.relu(self.deconv1(x)) #256*56*56 -- 128*56*56
x = self.bn3(x)
x = F.relu(self.deconv2(x)) #128*56*56 -- 64*112*112
x = self.bn4(x)
x = torch.tanh(self.deconv3(x)) #64*112*112 -- 3*224*224 生成器的输出不使用bn层
return x
# 定义判别器,输入为3*224*224的图片,输出为二分类概率值
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.linear = nn.Linear(2, 3*224*224)
self.conv1 = nn.Conv2d(6, 64, kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2)
self.bn = nn.BatchNorm2d(128)
self.fc = nn.Linear(128*55*55, 1)
def forward(self, x1, x2): #x1为真实图像输入,x2标签独热编码输入(condition)
x2 = self.linear(x2)
x2 = x2.view(-1, 3, 224, 224)
x = torch.cat([x1, x2], dim=1) #batchsize, 6, 224, 224
x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3) #64*111*111 判别器的输入不使用bn层
x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3) #128*55*55
x = self.bn(x)
x = x.view(-1, 128*55*55) #展平
x = torch.sigmoid(self.fc(x))
return x
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
gen = Generator().to(device)
dis = Discriminator().to(device)
# 判别器优化器
d_optim = torch.optim.Adam(dis.parameters(), lr=1e-4) #通过减小判别器的学习率降低其能力
# 生成器优化器
g_optim = torch.optim.Adam(gen.parameters(), lr=1e-3)
loss_fn = torch.nn.BCELoss() # 二元交叉熵损失
# 绘图函数,将每一个epoch中生成器生成的图片绘制
def gen_img_plot(model, epoch, noise_input, label_input): # model为Generator,test_input代表生成器输入的随机数,label_input为标签输入
# prediction = np.squeeze(model(test_input).detach().cpu().numpy()) #squeeze为去掉通道维度
prediction = model(noise_input, label_input).permute(0, 2, 3, 1).cpu().numpy() #将通道维度放在最后
plt.figure(figsize=(10, 10))
for i in range(prediction.shape[0]): #prediction.shape[0]=noise_input的batchsize
plt.subplot(2, 2, i + 1)
plt.imshow((prediction[i]+1)/2) #从-1~1 --> 0~1
plt.axis('off')
plt.savefig('./CGAN_img/image_CGAN_{}.png'.format(epoch))
# if epoch == 99:
# plt.show()
# 设置生成绘图图片的随机张量,这里可视化4张图片
noise_input = torch.randn(4, 100, device=device) #测试输入:16个长度为100的随机数
# print(noise_input)
label_input0 = torch.randint(0, 1, size=(4, )) #生成4个从0到1的随机整数
# print(label_input)
label_input_onehot = one_hot(label_input0).to(device) #将tensor转化为独热编码形式
# print(label_input_onehot)
# CGAN训练
D_loss = []
G_loss = []
for epoch in range(500):
d_epoch_loss = 0 #判别器损失
g_epoch_loss = 0 #生成器损失
count = len(dataloader) #len(dataloader)返回批次数
count1 = len(train_dataset) #len(train_dataset)返回样本数
for step, (img, label) in enumerate(tqdm.tqdm(dataloader)): #此时返回的label已经是独热标签
img = img.to(device)
label = label.to(device)
size = img.size(0) #该批次包含多少张图片
random_noise = torch.randn(size, 100, device=device) #创建生成器的噪声输入
d_optim.zero_grad() #判别器梯度清0
real_output = dis(img, label) #将真实图像放到判别器上进行判断,得到对真实图像的预测结果
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) #real_output应该被判定为1(真),得到判别器在真实图像上的损失
d_real_loss.backward() #计算梯度
gen_img = gen(random_noise, label) #得到生成图像
fake_output = dis(gen_img.detach(), label) #将生成图像和对应的标签同时放到判别器上进行判断,得到对生成图像的预测结果,detach()为截断梯度
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) #fake_output应该被判定为0(假),得到判别器在生成图像上的损失
d_fake_loss.backward() # 计算梯度
d_loss = d_real_loss + d_fake_loss #判别器的损失包含两部分
d_optim.step() #判别器优化
# 生成器
g_optim.zero_grad() #生成器梯度清零
fake_output = dis(gen_img, label) #将生成图像放到判别器上进行判断
g_loss = loss_fn(fake_output, torch.ones_like(fake_output)) #此处希望生成的图像能被判定为1
g_loss.backward() # 计算梯度
g_optim.step() #生成器优化
with torch.no_grad(): # loss累加的过程不需要计算梯度
d_epoch_loss += d_loss.item() #将每一个批次的损失累加
g_epoch_loss += g_loss.item() #将每一个批次的损失累加
with torch.no_grad(): # loss累加的过程不需要计算梯度
g_epoch_loss /= count
d_epoch_loss /= count
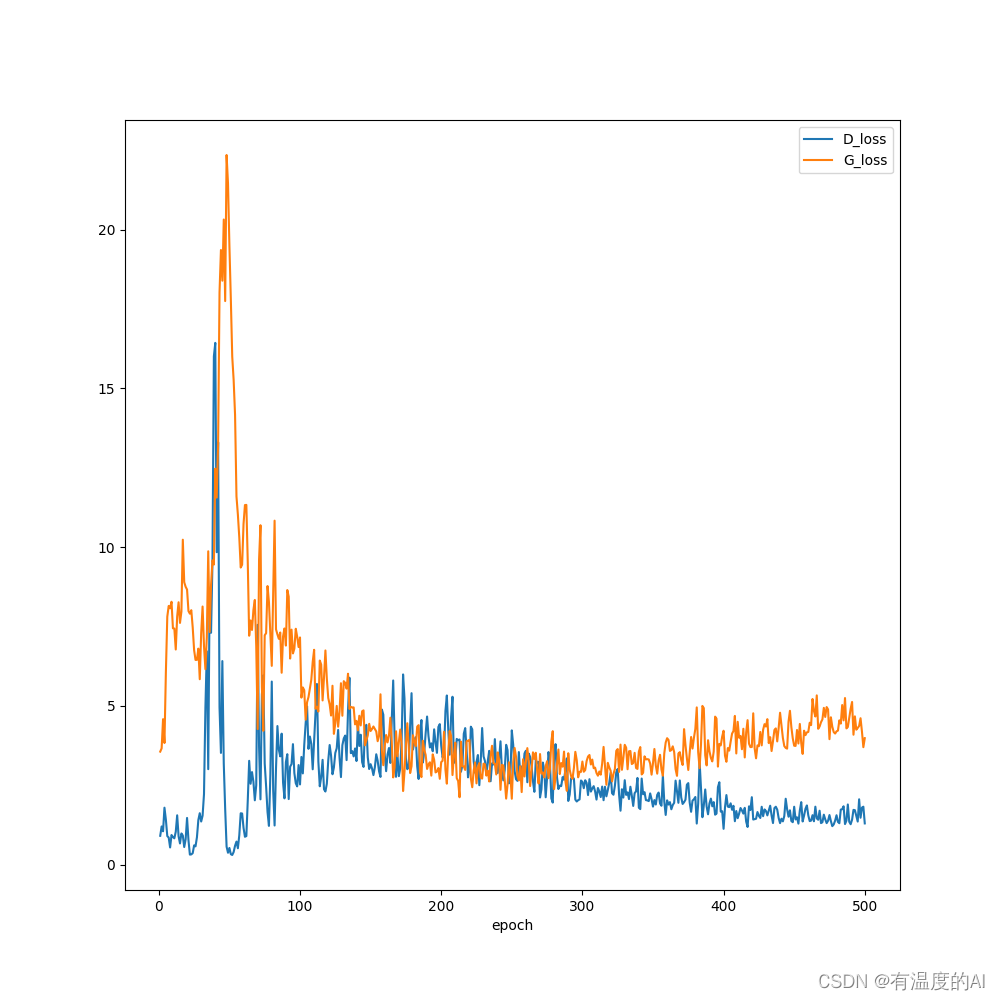
D_loss.append(d_epoch_loss) #保存每一个epoch的平均loss
G_loss.append(g_epoch_loss) #保存每一个epoch的平均loss
print('Epoch:', epoch)
gen_img_plot(gen, epoch, noise_input, label_input_onehot) #每个epoch会生成一张图
plt.figure(figsize=(10, 10))
plt.plot(range(1, len(D_loss) + 1), D_loss, label='D_loss')
plt.plot(range(1, len(G_loss) + 1), G_loss, label='G_loss')
plt.xlabel('epoch') # 横轴名称
plt.legend()
plt.savefig('loss.png') # 保存图片
cGAN生成的图像虽有很多缺陷,如图像边缘模糊,生成的图像分辨率太低等,但是它为后面的pix2pixGAN和CycleGAN开拓了道路!!!
最后放上我训练的结果(数据量不大,只有四百张狗的图片,效果不太明显!!!)