接下来,我们就来讲下嵌套路由。
这里,我们仍然用上一篇博客的 demo 继续做演示。
比如,我们现在需要有一个这样的层级关系:
/ 首页
/course 课程
/work 作品
/js
/node
/express
/koa
/react那么我们先把文件创建好:
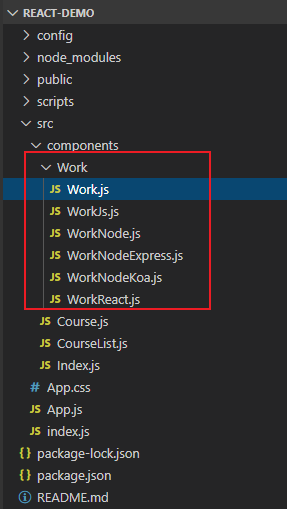
首先 Work.js 肯定是最主要的,其他都是它内部的东西。
接下来,就要在路由表里面做文章了,整个嵌套路由,它里面有一个最核心的事,这个你只要知道了,一切都没问题。
那就是 <Route /> 这个路由节点,它可以出现在任何地方,任何一个组件里面。
我们之前都放在 App.js 里面,就是为了看起来方便。
所以,在 Work.js 里面,我们也可以写:

然后我们就可以看到,二级导航OK了:
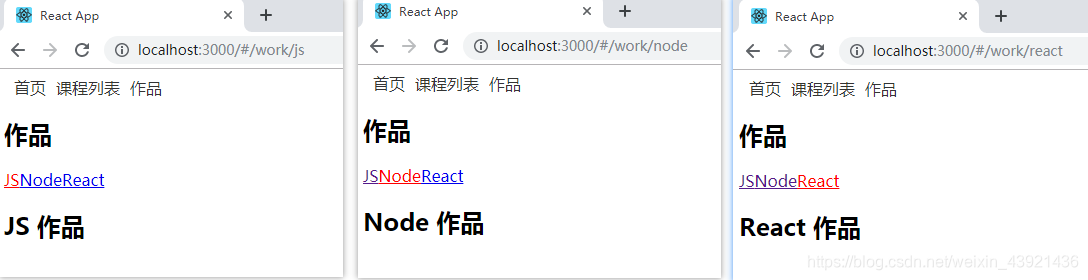
但是我们会发现,有个小问题,就是我们在代码中写了大量的 work:

那么,万一外面的路由,也就是 App.js 里面的地址改了,那里面是不是全得改?

而且如果你里面还有三级,四级路由嵌套,那改动量就大了。所以任何一个制造耦合的机会,都是不好的。
我们希望的是,如果你要改,就只改这个文件,其他的文件一律不动。
那怎么样才能做到,外面的改了,里面的自动变?
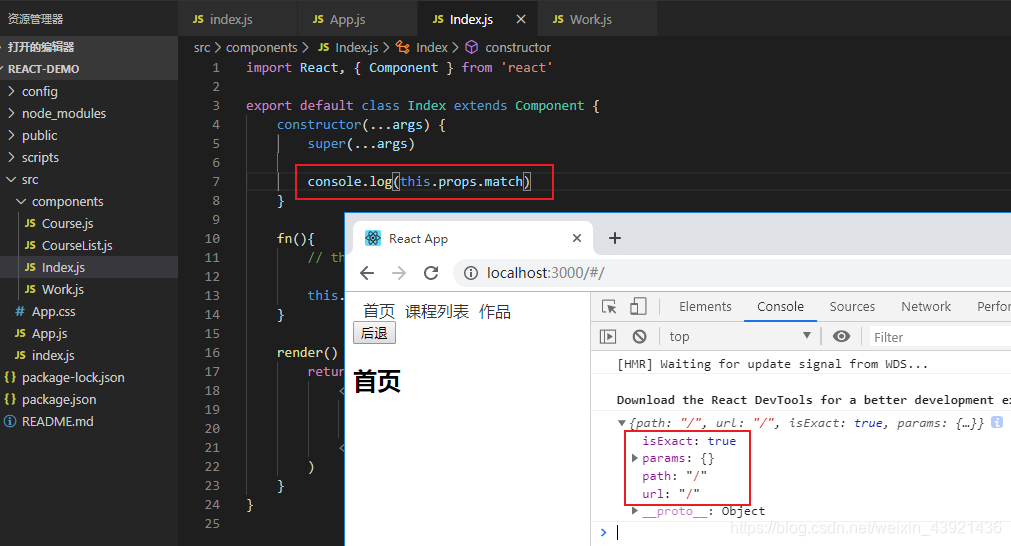
很简单,我们要做的是获取 this.props.match:


可以看到,这个 match 的 path 就是我们所需要的。
那么,如果我们继续点到 JS,Node,React 里面去:

注意,这时候,path 还是 /work。
因为我现在获取的是我这层所匹配的东西,而不是在往里一层。

所以你不用担心,尽管地址真的已经变成了 /work/js,但是 match 打印出来的 path 还是 work。
因为这个 match 的本意就是,符合我这级要求的路由信息。别的级别,里面的我都不管。
所以我们最好是能做到这种解耦合的状态,你别的组件想怎么改随便改,跟我没关系,我这里面的东西不用变:

所以三级路由导航我们也就知道怎么写了:

那么如果结构是从数据库里面读出来的,怎么办?
因为 <Route /> 它跟普通的节点一样,所以它也是可以循环出来的,并不是说它就一定得写死在里面。
所以,我们还可以做成无限层级嵌套路由。
首先,我们先还原到之前的一级菜单,只将 Work.js 保留下来,然后假设 courseData 里面的多层级数据来自数据库:

接下来,就是获取路径和数据,并渲染:

这样,一个无限层级的嵌套路由就OK了:

所以嵌套路由的原理其实很简单:在任何组件中,都能使用 Route,因为整个 App 包含在 Router 中。
然后用 path 存储当前的路由路径,向后追加更多级别即可。
接下来,我们再来说下路由跳转。
其实不管是 React 还是其他框架里面,绝大多数的路由其实都是通过 history 来实现的。
history 本质上是一个栈。它的特点,就是后放进去的,最先出来。
类似于我们拿盘子,一叠盘子,我们都是从最上面开始拿,没人从底下抽。而最上面的盘子,就是我们最后放进去的。
我们浏览器里面的历史记录也是如此。
那么当我们使用 Link 的时候,就需要用户去点,因为它是个按钮,你要不点,就没事发生。
而除了 Link,还有一个标签 Redirect,它的意思就是重定向,它不需要用户点,只要你在标签里面放了 Redirect,那么这个页面会自动跳走。
我们先将作品页 Work.js 还原:

然后在 Index.js 里面放上一个 Redirect 标签,让它自动跳转到 /work:

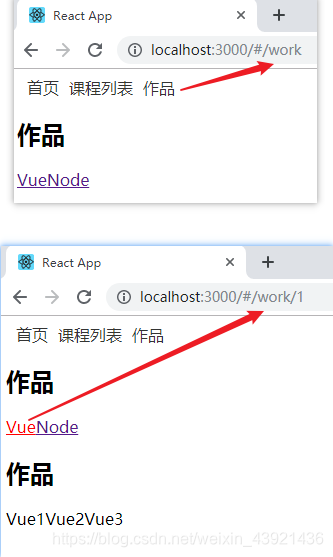
然后我们刷新页面,就可以看到,直接就进入了 /work 的路由:

可以看到,首页点不进去。而且是直接跳转到 /work 页面的。你用尽一切办法都进不了首页的 /。
即使我们在地址栏上手动的删掉 /work,在按回车,它还是会直接跳转到 /work。

那么 Redirect 它一般用在哪呢?比如用户登录:

只有登录了,login 为 true,才可以进到首页。
所以 Redirect 就是无条件跳转。
然后我们虽然能用 Link,但其实我们平常用的 Link 并不是最完整的一个状态,如果需要的话,其实是改它里面的东西的。
我们平常在 Link 里面用的 to,它后面的值就是一个字符串,其实这是个简写,它里面还可以写个 json。

这个 json 里面可以带几个东西:
1,pathname。
2,search,就是问号后面那个东西
3,hash。
因为我们现在用的就是 HashRouter 路由,所以 hash 测不出来,我们可以换成 BrowserRouter:

然后我们加上 pathname,search,hash 后,点击首页:

那么如果我们就用 HashRouter,和 hash 配起来会怎么样呢?

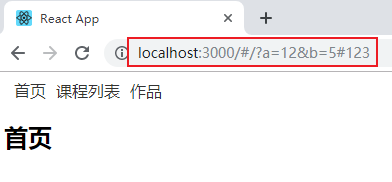
其实并不会起冲突,只是会在后面又添了一个而已。
接下来,我们会了解一个比较重要的东西,如何通过 JS 来进行跳转?
首先,我们需要一个 history 对象。

length:50,代表的是我的 history 里面已经堆了 50 个了。
push(xxx),字符串和 json 都可以。和 Link 里面的 to 一样。
go(num),代表的是前进或者后退多少级。
repleace(xxx),把当前的级别抹掉。和 push 里面的参数是完全一致的。
比如现在,我想跳转到某一个地方去,就需要 push 方法:
push 方法接收的参数是什么?你在 Link 里面的 to 怎么写,它里面就怎么写。

然后,go,你给它的是个数字,比如 go(-1),那就是往回退一个。
goBack,就是 go(-1) 的简称。
goForward,就是 go(1) 的简称。

所以我们直接用 history 就行了。它里面有各种各样的方法。
然后,history 里面有个 listen( function(){} ),就是监听。如果你需要的话,就可以加个函数在里面。只要它这个路由跳转了,它就都会通知你,告知你用户从哪来,到哪去。
当然在现在的 index.js 里面不适用,因为在 index.js 里面,只要你一跳转,你当前的这个组件就没了,消失了。
那么在哪个地方合适呢?在 Work.js,Course.js 里面都合适,因为在它跳转的时候,主组件并不会消失,它还会在那,所以就可以用 listen。当然大部分情况下,我们也是用不到 listen 的。
然后我们来说下路由的 search 参数:
可以看到,match 里面它是没有 search 参数的。
search 你是不能直接的通过 match 来获取的。因为实际上来说,它这个参数并不是我们 Router 的一部分,相反,它是 location 的一部分。而 location 对象是 window 里面自带的。

因为,我们现在用的是 hash 的模式。
在 hash 里面,你的 search 其实不是一个真正的 search,它是仍在 hash 里面的,所以 location 里面的 search 是解析不出来的。
所以你要真想用 search 的话,我们是需要换成 BrowserRouter 的:

现在 search 里面的参数,是需要我们自己去处理的,有一个方法,是原生 JS 里面带的:new URLSearchParams。
从它的名字就可以看出来,它是一个专门用来获取你地址里面 search 参数的东西。
它接收的是一个字符串,然后我们可以通过它的 get 方法来获取:

所以标准的 Router,是不认你的 search 参数的。它认的是它自己那套。
路由的跳转并不难,但是你要如何在真实的项目当中,把它给用起来,这就是一个重要的事了。
最后,我们总结一下关于路由跳转的问题:
本质上,路由都是通过 history 实现的,而 history 本质上是一个栈,所以,总共有两套方法来操作:
1,push、pop:向栈尾添加 / 从栈尾取出。
2,replace:直接替换掉当前级别。
Link 标签,相当于 push 操作,类似于 a 链接。如:
<Link to="xxx">文字</Link>
或者更复杂的
<Link to={{
pathname: '/work',
search: '?a=12&b=5',
hash: '#123'
}}>文字</Link>Redirect 标签,相当于 replace 操作,类似于 302。如:
<Redirect to="xxx">文字</Redirect>
或者更复杂的
<Redirect to={{
pathname: '/work',
search: '?a=12&b=5',
hash: '#123'
}}>文字</Redirect>