这里主要介绍一下R-CNN系列论文的大致思路。。包括训练的步骤,预测的步骤,以及每篇论文的新颖之处。
R-CNN
下面是r-cnn的流程图:
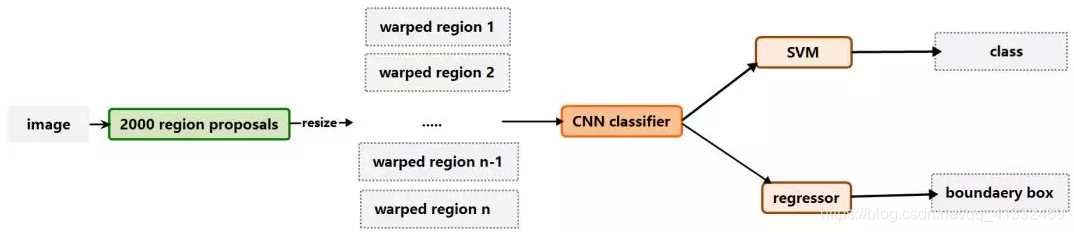
训练过程
1、输入一张带标签的图片,利用select-search方法,得到候选区域(region propossals,大约2000个)
2、对每一个region propossal ,利用仿射图像扭曲(affine image wraping),将这些候选区域转换为相同大小的图片(其实卷积层是不在意输入大小的,但是后边的全连接层是固定的,所以在这里要固定大小输入CNN中),然后丢入CNN中提取特征向量。
3、得到候选区域特征向量后,将他丢入SVM分类器中,得到预测的类别;然后再丢入回归器中,回归出预测的边框信息。。
4、得到预测结果后,与标签对比,计算损失函数,反向传播,更新模型参数。
细节
1、初始的CNN模型
利用分类图片进行有监督的模型预训练,这个模型主要用于提取输入图片的特征,用于后续的分类和回归
2、模型的微调
因为预训练模型是拿分类任务数据集训练的,但是现在要做的是检测任务,除了要分类,还要回归边框坐标,所以需要拿着检测任务的数据集进行模型微调,微调包括两部分,具体如下:
(1)CNN的微调:新来一张训练图片,得到2000左右的候选区域,要利用这些候选区域来微调模型,每个候选区域的预测类别和边框坐标可以由正向传播得到,但是目标值该如何确定呢?论文中的做法是,计算预测边框与目标边框(ground truth预先标记好的)的IOU,如果IOU>=0.5,就当做正类(标签与ground truth一致),否则当做负类(不计入类别的损失函数中,不用于训练模型),用这组训练数据来微调CNN
(2)训练SVM:这里用SVM做二分类,还是上述的方法,但是阈值改为了0.3(这个超参数是由实验得来的),大于0.3为1,小于0.3为0。分类为什么不用softmax呢?论文中说的是精度没有svm高。
预测过程
1、select-search方法,得到候选区域
2、每个候选区域卷积提取特征
3、拿着得到的特征,利用训练好的分类器和回归器进行预测
4、利用NMS得到最终的预测结果。
总结
R-CNN在具体的每一步算法中没有什么创新,都是借鉴已有论文中的方法,但是虽然方法不新颖,但是多个基本方法组合到一起,却得到了很好地效果。。
缺点:
1、select search 来挑选候选区,效率低,然后卷积又存在着大量重复计算
2、候选区域的尺度缩放问题,导致目标变形,影响识别准确率
fast R-CNN
主要是针对R_CNN的缺点做的改进
训练过程
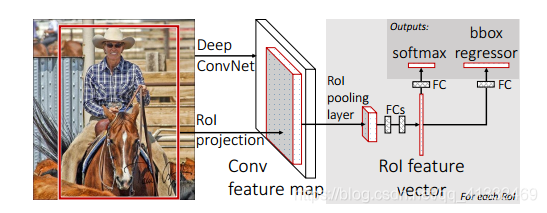
1、输入一张带标签的图片,利用select-search方法,得到候选区域;
2、ROI pooling:
- 正向卷积得到feature map,然后进行ROI projection(映射操作),具体就是将第一步的候选区域区域映射到feature map中,这样避免了对候选区域卷积时的重复计算);
- 然后ROI polling 将ROI转为相同大小的尺寸,这是 SPP( 空间金字塔池化) 的一个特例, SPP 采用多个尺度的池化层进行池化操作, 而RoI pooling 只采用单一尺度进行池化,之后全连接,得到每个ROI的特征向量;
3、计算损失,但开始使用多任务损失,不再单个训练svm分类器和边框回归器,并且这里分类开始用softmax,一次微调,同时对分类器和回归器进行优化(这样简化了操作,加快了速度)
4、反向传播更新模型参数
细节
1、ROI pooling
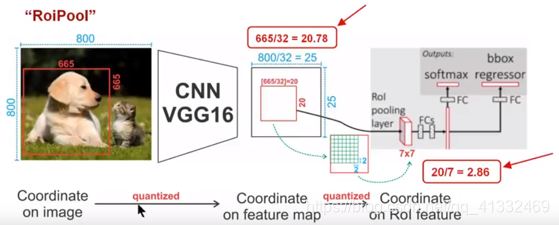 ROI pooling主要做了两件事:
ROI pooling主要做了两件事:
将原图feature map中的候选区域映射到feature map中;将不同大小的ROI用 max pooling转化为相同大小的特征向量。
如上图最后一步映射,从20×20的矩阵产生7×7的矩阵,将2.86取整为2,那么意味着需要从2×2的矩阵最大池化产生一个1×1的矩阵,所以实际上是由14×14的矩阵产生了7×7的矩阵。。
ROI pooling的问题所在:
从上图我们可以看到,从前到后做了多次映射,第一次从原图到feature map,第二次从feature map 到 ROI feature,上面每一次映射都会进行取整操作,多次取整操作,将边框映射到原图,将会有多个像素的偏差,从而导致边框越来越不准确。
2、多任务损失
fast R-CNN统一了类别输出任务和候选框回归任务。多任务损失函数的定义为:

总结
fast R-CNN主要的改进点是:
- 候选区域共享卷积操作,避免了单个候选区域的卷积而引起的重复操作加快了速度;
- 利用roi pooling,避免了剪裁而导致的变形问题;
- 多任务损失,统一了类别输出任务和候选框回归任务。
faster R-CNN
最主要的改进就是在候选区域的改进,提出RPN和anchor box,大幅增加速度。。
其中RPN网络将候选区域的选择从图像中移到了feature map,拿anchor box在feature map中滑动窗口,相比select search快了很多。
训练过程
1、cov layers:直接对有原图进行正向卷积,得到feature map;
2、RPN:
- 对feature map进行滑动窗口,同时利用anchor box,得到ROI,如果当前feature map大小为W×H,k = 9个anchor box,那么将会得到k×W×H个anchor;
- 利用ROI pooling将ROI转换为同样大小的特征向量;
- 将特征向量同时扔给分类器和回归器,cls分类器是一个two-class softmax layer,预测输出一个二维数据,用来预测当前这个ROI有无目标的概率(共2k个scores),回归器用来回归边框的坐标信息,是一个四维的输出(4k个坐标值)
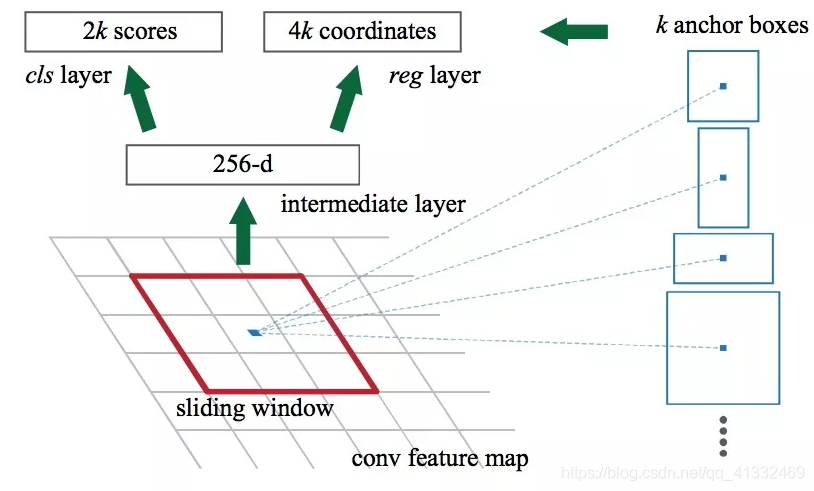
4、IOU>0.7视为正类,<0.3为反例,其余的不用于训练,损失函数如下,从损失函数可以看出,坐标的回归只对存在目标的边框计算损失(Lcls 和 Lreg 和fast R-CNN一样)
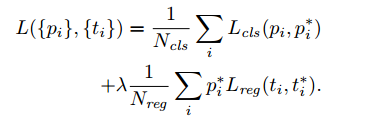


5、反向传播更新模型参数
测试过程
1、 把任意大小的图片输入 CNN 通过卷积层进行特征提取;
2、利用 RPN 网络产生高质量的建议框, 每张图片约产生 300 个建议框;
3、将建议框映射到 CNN 的最后一层卷积特征图上;
4、用 RoI pooling 层固定每个建议框的大小;
5、利用分类层和边框回归层对建议区域进行具体的类别判断和精确的边框回归;
6、NMS得到最终预测框;
总结
R-CNN系列论文主要就是在不断的加速,主要是针对候选框的加速,而采用的方法就是不断地将任务向feature map上迁移,尽量用网络解决问题,这样训练的更快。
Mask R-CNN
mask R-cnn是一种对象实例分割方法,基于faster R-cnn做了改进。
实例分割(instance segmentation):不仅区分类别,而且区分单个对象
语义分割(semantic segmentation):仅区分类别,不区分单个对象
相对于faster R-cnn的改变
(1)多分支输出
(2)binary mask
(3)ROI Align
多分支输出
在faster R-CNN中,到class box输出就结束了,但是,这里继续对ROI特征进行全卷积(FCN),从而得到ROI中对象的mask。
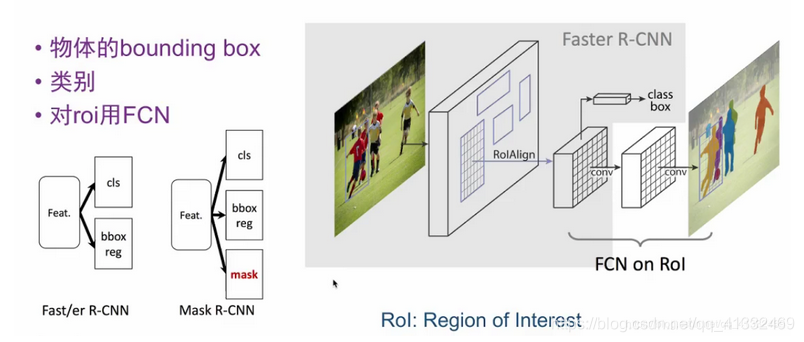
binary mask
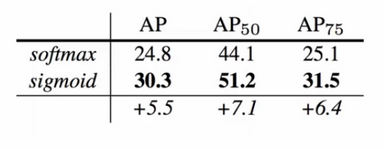
在FCN中,是对每个像素用softmax进行多分类,而mask R-CNN对ROI进行二分类,只需要判断每个像素是背景还是识别对象即可,二分类相对于多分类,难度下降,分类精度也提高了
ROI Align
Roi Align实际是Roi pooling的精确版;
feature map中的小的变化,映射到原图上可能是好几个像素的变化,因为分割任务边框的精确度要求要比检测任务要求更高,所以Align可以增加分割精度。
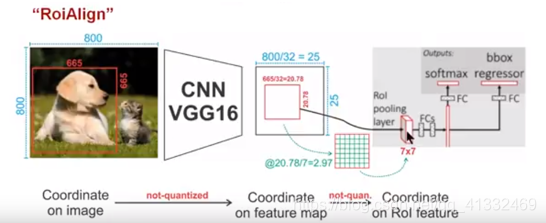 ROI Align在计算映射过程中,不进行取整操作;
ROI Align在计算映射过程中,不进行取整操作;
如上图,在最后一步映射中,从20.78×20.78的矩阵向7×7的矩阵映射时,需要从2.97×2.97的矩阵中最大池化产生一个1×1的代表值,怎么做呢?
采用双线性插值

如上图,假定采样点数为4,即表示,对于每个2.97*2.97的小区域,平分四份,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样,就会得到四个点的像素值,四个红色叉叉‘×’的像素值是通过双线性插值算法计算得到的,取四个像素值中最大值作为这个小区域(即:2.97×2.97大小的区域)的像素值(实现最大池化)