SVM补充
上一篇文章 机器学习复习8-SVM 描述的内容主要是硬间隔线性可分SVM,但是现实世界中往往并不是完美的,在实际环境中接触到的数据即便是线性可分也往往是找不到硬间隔的,还有线性不可分的情况,那么此时应该怎么办,SVM如何解决这种问题,本次就对SVM进行补充来说一说这些问题。
1.软间隔线性可分SVM



C值越大,分类器就越不愿意允许分类错误(“离群点”)。如果C值太大,分类器就会竭尽全力地在训练数据上少犯错误,而实际上这是不可能/没有意义的,于是就造成过拟合。而C值过小时,分类器就会过于“不在乎”分类错误,于是分类性能就会较差。



得到:

然后得到:
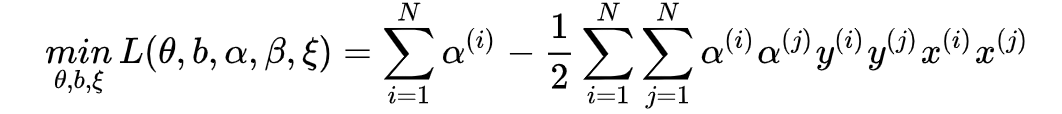

从对偶问题的形式也可以看出来,相较于硬间隔SVM来说,只是对拉格朗日乘子的上限做了限制,上限就是
。
后续再使用SMO等方法即可。
2.核方法


线性核、高斯核、多项式核:

表示内积

可以看出来,核函数
可以避免在高维空间中做内积这种复杂的运算是因为核函数巧妙的避免了映射之后再做内积,而是直接给替代了,相对应的SVM的原始问题、对偶问题、超平面模型都会有所变化,皆是将内积转变为其核函数:
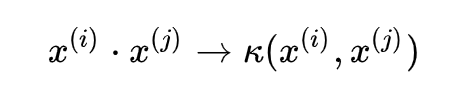
如对应的软间隔对偶问题变为:

3.SVM的优缺点


4.SVM 核函数之间的区别
一般选择线性核和高斯核,也就是线性核与 RBF 核。
线性核:主要用于线性可分的情形,参数少,速度快,对于一般数据,分类效果已经很理想了。
高斯核:主要用于线性不可分的情形,参数多,分类结果非常依赖于参数。
有很多人是通过训练数据的交叉验证来寻找合适的参数,不过这个过程比较耗时。
如果 Feature 的数量很大,跟样本数量差不多,这时候选用线性核的 SVM。
如果 Feature 的数量比较小,样本数量一般,不算大也不算小,选用高斯核的 SVM。


5.为什么SVM对缺失数据敏感
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM 没有处理缺失值的策略。而 SVM 希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
SVM 全部KO~
