用过Gated PixelCNN来提取特征,跟别人说起我用过这个模型,不管这个模型在我的项目中达到了什么效果,别人想了解,就会先问:什么是Gated PixelCNN?撰写此文以记录,以便后期查阅。(虽然下文是英文,但都是自己写的,可能有语法和理解上的错误和偏差,欢迎指正)。作者的文章 在这。看过的代码中,这一份 代码最能体现这种模型的含义。
1. Definition of Gated PixelCNN
- Gated PixelCNN is an image generation model.
- It extracts and generates pixels in a sequential manner. Specifically, it generates the current pixel based on the previous(on the top and left)pixels.
- It consists of a prior network and a conditional network.

- When training,the LR images are sent to the conditional network,while the HR images are sent to the prior network.The conditional network is used to extract global information from low-resolution images.While the prior network is used to extract prior information from high-resolution images.In particular,the prior network extract pixels in a sequential manner,which forces the network to predict current pixel according to “previous(all pixels on the top and left)” pixels.After fusion of the prior and the global feature maps,a softmax_loss is applyed between this new feature map and label.Why softmax?As we know, softmax can be used as a classifier.In this case,softmax will determine what is the most likely pixel value(0-255) in each position.In bried, the current pixel is predicted based on the “previous” pixels.
- When testing,the LR images are sent to the conditional network,but pixels generated in a sequential manner at the end of the network are sent to the prior network.In brief,the current pixel is generated based on the “previous” pixels.
- It is a pixel-wise generation model, extracting from pixel to pixel,and generating from pixel to pixel.It is a kind of CNN.It has a “gate” structure.So,it is called “Gated PixelCNN”.
- The prediction of the joint distribution of all pixels on an image is transformed into the prediction of the conditional distribution.

2. Each layer of Gated PixelCNN
Note:some instructions on this article are different from original paper of the auther,especially the “mask”.The code at the beginning of this instruction use a different kind of “mask”,I will only intruduce this kind of “mask” rather than the one on original paper.Howerver the purpose of this two different forms of “mask” are the same:to force the model to learn informations on the top and left of current pixel.
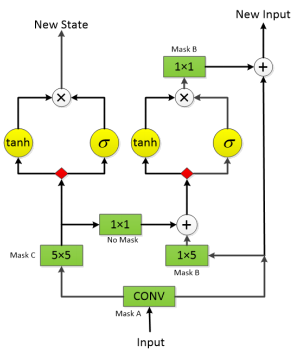
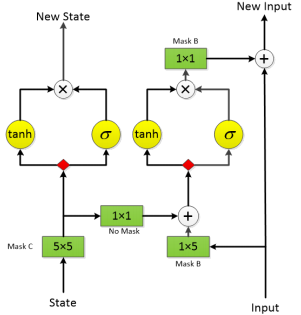
The model “Gated PixelCNN” consists of a “input layer”,many “mid layers” and a "output layer If there is a 32(h)×32(w)×64© feature map as input,you will get 32(h)×32(w)×64© feature map as output,so is the each layer.In each layer,the channel of the feature map will be doubled and splited into two parts(red rectangle in the picture) .One part of the feature map will go through “tanh” function ,while another will go through “sigmoid” function.The two output from two functions will be multiplied to get the “new state” on the left.On the right,througout the same operation,along with other operations,you will get “new input”.
 input layer input layer
|
 mid layer mid layer
|
 output layer output layer
|
There are three different kind of kernels in these CNNs:kernel with mask A,kerner with mask B,kernel with mask C.Take this 5×5 rectangle as an example of a kernel.Kernel with “mask C” refers to a kernel that can only “see” green area while extracting informations.Kernel with “mask A” refers to a kernel that can only “see” blue area while extracting informations.Kernal with “mask B” refers to a kernel that can only “see” yellow area.

So,lets move on to the " input/mid/output layers" picture.The numbers in green rectangle such as “5×5” refers to kernel size. The 5×5 convolution multiply number of channels by 2,so is the 1×5 convolution. The 5×5 convolution collect information of pixels on the top of current pixel and sents this information to fuse with informations of pixels on the left of current pixel. It’s clear that the “new state” contans information of all pixels on the top direction of current pixel.
Do you still remember " Resnet"? Its input and ouput feature maps dimensions are the same,so is the Gated PixelCNN.Resnet combines input maps with output maps of two convolutions,but the Gated PixelCNN combines input maps with output maps of one convolution.Resnet has relu activation function,while Gated PixelCNN has tanh+sigmoid as activation(also called “gate”) function.Resnet can make model deeper,so is Gated PixelCNN.Gate structure improve model performance.So,Gated PixelCNN can be deemed as enhanced Resnet in a sense.
3. Definition of “Gate”
- Gate is the name of a structure ,which consists of a “tanh” and a “sigmoid” activation function.The former process half of the feature maps and the latter also process half of the feature maps in each layer.
- Gate structure was proposed in “Long Short Term Memory” to solve the problem of gradient disappearance and gradient explosion. To sum up,the gate structure improves model performance.
- It has masked kernels to make “previous” pixels available to current predict,but make “subsequent” pixels unavailable
- It serves as an enhanced activation function as “relu” in normal CNN.
