翻译《The rise of deep learning in drug discovery》
摘要
过去的十年中,深度学习(DeepLearning,DL)在各种人工智能研究领域取得了显着的成功。从以前对人工神经网络的研究演变而来,该技术在诸如图像和语音识别,自然语言处理等领域表现出优于其他机器学习(Machine Learning,ML)算法的性能。近年来,深度学习在医药研究中的第一波应用出现了,它的用途超出了生物活性预测的范围,并且在解决药物发现中的各种问题方面显示出了前景。
一、介绍
各种形状和大小的数字数据呈指数级增长。据美国国家安全局称,互联网每天处理1826PB的数据。在2011年,数字信息在短短五年内增长了9倍;到2020年,其在全球的数量预计将达到35万亿千兆字节。探索和分析大数据的高需求鼓励使用像深度学习(DL)这样的数据挖掘的机器学习算法。DL在计算机游戏、语音识别、计算机视觉、自然语言处理和自动驾驶汽车等广泛的应用领域取得了巨大的成功。可以说,DL正在改变我们的日常生活。在Gartner选择的2018年前十大技术趋势中,DL代表的AI技术位居榜首。
过去的十年里,已经在可用的化合物的活性和生物医学数据的量显着增加。如何有效地挖掘大规模的化学数据成为药物发现的关键问题。更大的数据量与更多的自动化技术相结合促进了机器学习的进一步应用。除了支持向量机(SVM)、神经网络(NN)和随机森林(RF)等已建立的方法,这些方法已被用于开发QSAR模型很长一段时间,矩阵分解和DL等方法已经开始被使用。DL利用了数据量的增加和可用计算机功率的不断增加。大多数其他机器学习方法和DL之间的区别在于DL中NN体系结构的灵活性。将在本问中讨论的架构是卷积神经网络(CNN),递归神经网络(RNN)和完全连接的前馈网络。单层神经网络已经用于QSAR建模很长一段时间;随着数据尺寸和计算能力的增加,自然而然地应用多层前馈网络进行生物活性预测。随着高通量成像设备的采用,CNN在计算机视觉领域取得了显着的成功,并成为生物图像处理的自然选择。在药物研发领域应用DL的领域正在迅速发展,几乎每周都有新的文章发表。最近,有关计算化学和生命科学领域的DL应用的一些评论已经发表。这里,我们更关注药物开发中的DL应用,特别是化学信息学和生物图像分析领域,并强调目前在药物开发中使用的DL结构。
二、深度学习的原理
DL是一类机器学习算法,其使用具有用于学习数据表示的多层非线性处理单元的人工神经网络(ANN)。最早的ANN可以追溯到1943年,当时Warren McCulloch和Walter Pitts基于数学和算法为阈值逻辑开发了神经网络的计算模型。现代ANN的基本结构受到人脑结构的启发。ANN中有三个基本层:输入层、隐藏层和输出层。根据ANN的类型,相邻层中的节点(也称为神经元)可以完全连接或部分连接。输入变量由输入节点进行,变量通过隐藏节点进行变换,最终输出值在输出节点进行计算。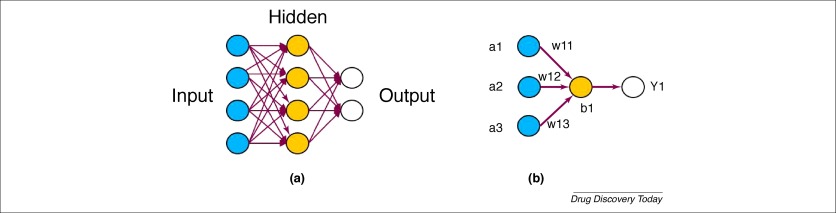
ANN的训练是通过迭代修改网络中的权重值来完成的,通常通过反向传播方法来优化预测值和真值之间的误差。现代人工神经网络算法是在20世纪60年代至80年代期间开发的,并且自那时起就出现了应用。但传统的人工神经网络方法存在诸如过拟合、递减梯度等问题,并且在很大程度上被其他机器学习算法取代。DL的最近发展使ANN得以复兴。DL与传统ANN之间的主要区别在于神经网络的规模和复杂性。由于计算机硬件在早期的局限性,DL使用大量的隐藏层,而传统的ANN通常只能提供一个或两个隐藏层。由于更强大的CPU和GPU硬件的出现,DL可以承担在每层中使用更多的节点。DL中还有许多算法改进,例如使用丢失和DropConnect方法来解决过度拟合问题,应用整型线性单元(ReLU)以避免消除梯度并将卷积层和池层引入新颖的网络体系结构,以便使用大量的输入变量。大多数DL软件包都是开源的。这里简要介绍DL中使用的几种流行的NN架构。首先是完全连接的深度神经网络(DNN),它包含多个隐藏层,每层包含数百个非线性处理单元。DNN可以采用大量的输入特征,并且DNN的不同层中的神经元可以自动提取不同层级的特征。
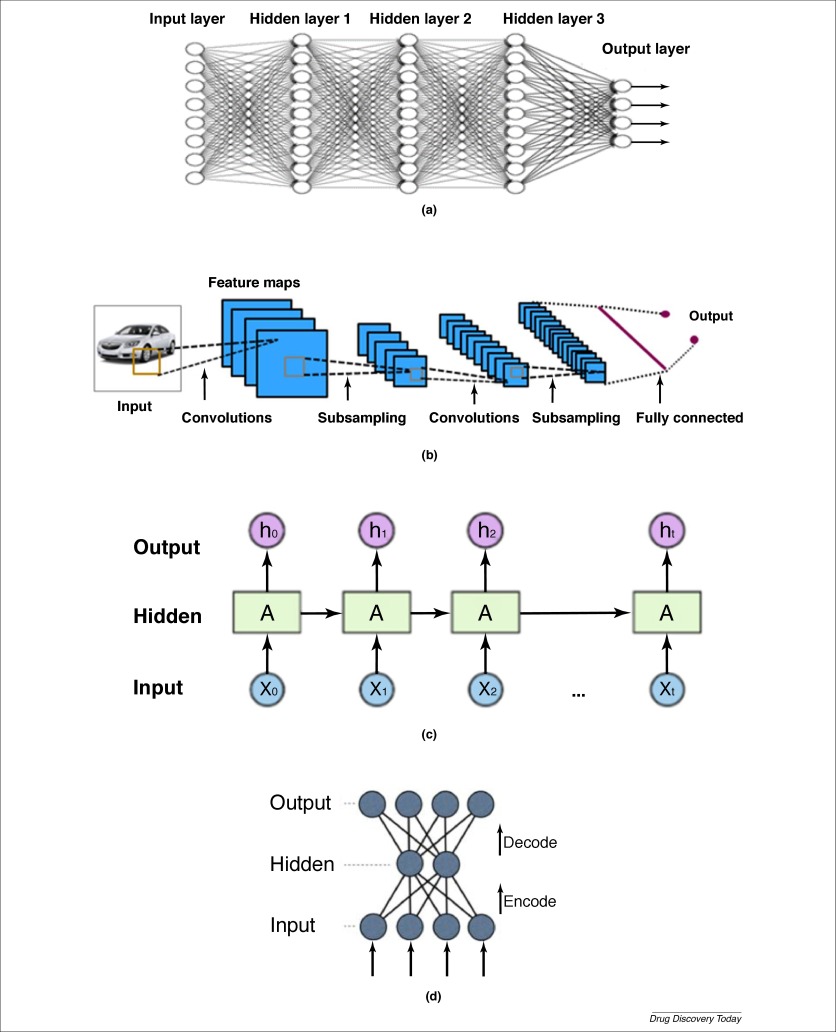
(a)完全连接的深度神经网络(DNN),(b)卷积神经网络(CNN),(c)递归神经网络(RNN)和(d)自动编码器(AE)
另一种非常流行的NN是CNN,它被广泛用于图像识别。它通常包含几个卷积层和子采样层。卷积层由一组具有较小感受域和可学习参数的过滤器组成。在正向过程中,每个过滤器在输入体积的宽度和高度上进行卷积,计算过滤器条目与输入体积中的接受域之间的点积,并生成该过滤器的2D特征映射,子采样层用于减小特征映射的大小。最后,特征映射被连接成完全连接的层,相邻层中的神经元全部连接,就像在传统的ANN中一样,以提供最终的输出值。由于每个滤波器共享相同的参数,CNN在很大程度上减少了所学习的自由参数的数量,从而降低了消耗的内存并提高了学习速度。它在图像识别中胜过了其他类型的机器学习算法。
ANN的另一个变体是RNN。与前馈神经网络不同,它允许同一隐藏层中的神经元之间的连接形成有向循环。RNN可以将顺序数据作为输入特征,这非常适合于时间相关的任务,如语言建模。使用称为长期短期记忆(LSTM)的技术,RNN可以减少消失梯度问题。
第四种ANN结构称为自动编码器(AE)。AE是用于无监督学习的NN。它包含一个编码器部分,它是一个NN,用于将从输入层接收的信息转换为有限数量的隐藏单元,然后将解码器NN与具有与输入层相同数量的节点的输出层耦合。代替预测输入实例的标签,解码器NN的目的是从较少数量的隐藏单元重建其自己的输入。通常,AE的目的是为了降低非线性维数。最近,AE概念已经越来越广泛地用于从数据学习生成模型。
三、深度学习在化合物性质和活性预测中的应用
包括ANN在内的机器学习方法已经应用于化合物活性预测中。DL方法被用来首先解决活性预测问题。当通过相同数量的分子描述符呈现化合物时,直接的方法是使用完全连接的DNN来构建模型。达尔等人使用大量的2D拓扑描述符在默克Kaggle挑战数据集上应用DNN;并且DNN在15个靶标中的13个中显示比标准RF方法略好的性能。这项研究的一些关键知识是:(i)DNN可以处理数千个描述符而不需要特征选择;(2)Dropout可以避免传统人工神经网络面临的过度拟合问题;(iii)超参数(层数、每层节点的数量、激活函数的类型等)优化可以最大化DNN性能;(iv)多任务DNN模型比单任务模型执行得更好。迈尔等人报告他们的多任务DNN模型在包含12的数据集上赢得了Tox21挑战12000种化合物用于12种高通量毒性分析。他们使用具有静态描述符(3D、2D描述符,预定义的毒素)的大型特征集以及动态生成的扩展连接指纹描述符(ECFP)来使DNN在训练过程中进行自我特征推导。更有意思的是,专门使用ECFP的 DNN模型进行统计学关联分析,并且与已知的毒性基因显着相关的子结构在每个隐藏层都可以被识别。这些基准测试结果证明了与单任务DNN和传统机器学习方法相比,多任务DNN的优势。
Ramsundar等进行了一项系统研究,以构建多任务DNN并将其性能与单任务DNN模型进行比较。他们的研究结果表明,多任务模型比单任务模型和射频模型表现更好。Koutsoukas 等将DNN模型与一些常用的机器学习方法(如SVM,RF等)相比较,选择了ChEMBL中的七个数据集。发现DNN在统计学上优于其他(基于Wilcoxon统计检验的P值<0.01)机器学习方法。Lenselink 等报道了另一项比较DNN与常规机器学习方法RF、SVM、朴素贝叶斯和逻辑回归方法考虑蛋白质描述符的基准研究。他们研究了包含314 767个靶标化合物相互作用的数据集上的各种分类模型的性能。DNN模型在BEDROC(Boltzmann增强的接收机工作特性鉴别)方面证明是最好的模型,并且多任务和PCM实现被证明可以提高单任务DNN的性能。
此外有人报告了使用DNN二维拓扑描述来制作预测研究BACE活性模型和实现0.82的分类精度和PIC的标准误差50 ~0.53所述验证集。Aliper 等人建立了DNN模型,用于预测药物的药理学特性以及利用来自LINCS项目的转录组数据的药物再利用,以及路径信息。已经表明,使用途径和基因水平的信息,DNN模型在预测药物适应症方面实现了高精度,因此它们可用于药物再利用。
即使NN能够直接从分子结构中学习,而不是使用预定义的分子描述符。这个想法最初是由Merkwirth等人探索的。2005年几年后,开发了两种不同的方法来解决这个问题。Lusci 等报道了一种采用称为UGRNN的RNN变体的方法,该方法首先将分子结构转换为与分子表示相同长度的矢量,然后将它们传递到完全连接的NN层以建立模型。向量中的位值是从数据集中学习的。显示UGRNN方法能够建立预测溶解度模型,其准确性与用分子描述符建立的模型相当。徐等人应用相同的方法模拟药物性肝损伤(DILI),DL模型是基于475种药物构建的,并在198种药物的外部数据集上进行验证。最好的模型达到了0.955的AUC,超过了先前报道的DILI模型的精确度。
另一种方法称为图形卷积模型,其基本思想类似于UGRNN方法,该方法使用NN来自动生成分子描述向量,并通过训练NN来学习向量值。由摩根圆形指纹法启发,Duvenaud 等提出了神经指纹方法作为创建图形卷积模型。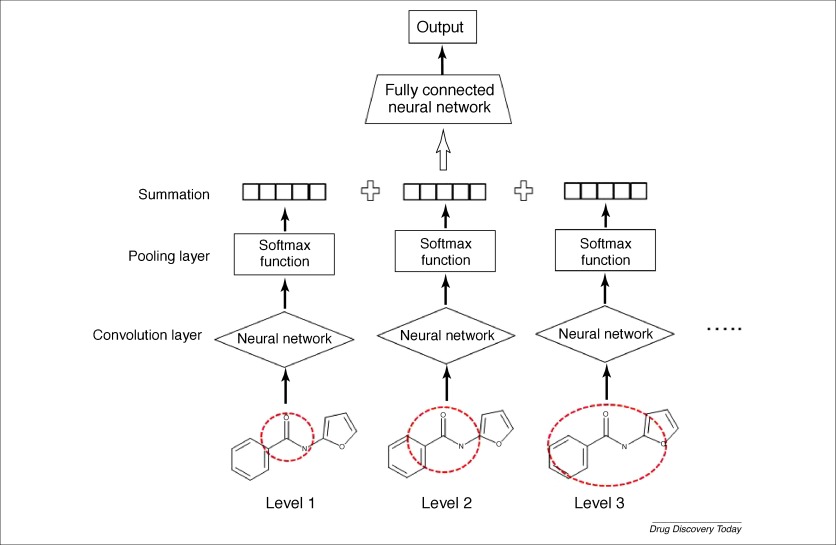
该方法的工作流程:首先,读取2D分子结构以形成状态矩阵,其包含每个原子的原子和键信息。状态矩阵然后通过单层神经网络进行卷积运算以生成固定长度的矢量作为分子表示。通过考虑相邻原子的贡献,卷积操作可以在不同的级别运行,这相当于不同邻近级别的圆形指纹。由不同卷积运算产生的载体首先经历softmax变换,然后被总结以形成化合物的最终载体,该化合物是编码分子水平信息的神经指纹。神经指纹通过另一个完全连接的NN层来生成最终输出。神经指纹中的比特值通过训练学习并且是可微分的。在Duvenaud的三个测试案例中,使用神经指纹获得比Morgan指纹更好的结果,更重要的是,图形卷积模型中的影响性子结构可以被可视化以解释模型。图卷积模型的优点是描述符在训练过程中自动生成,并且不需要任何预定义的分子描述符。这样的描述符不是一般的描述符,而是特定任务和完全可区分的,因此可以提供更好的预测。其他分子图卷积方法由Kearnes报道使用神经指纹比使用摩根指纹获得更好的结果,更重要的是,图形卷积模型中的影响性子结构可以被可视化以解释模型。
除了基于图的表示学习方法外,还探索了基于其他类型分子表示的DL方法。Bjerrum使用SMILES字符串作为LSTM RNN的输入来构建预测模型,而不需要生成分子描述符。更有趣的是,有人观察到通过使用多个SMILES字符串来表示相同的化合物来扩大数据集比使用规范的SMILES获得更好的结果。吴作栋等将CNN应用于分子2D图形的图像,并获得令人惊讶的与ECFP培训的DNN模型相当的结果。而且当图像增加了一些基本的化学信息时,模型性能得到进一步改善。直接从结构中学习表示的能力不需要使用任何预定义的结构描述符,这是将DL与其他机器学习方法区分开来的一个重要特征,它基本上不需要传统的特征选择和缩减过程。四、利用深度学习进行全新设计
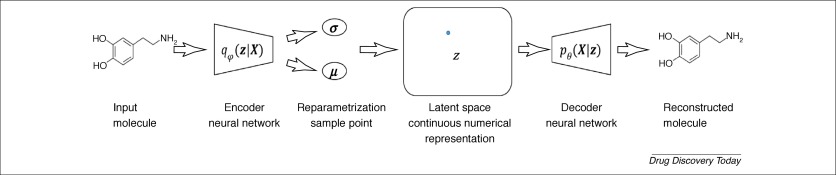
DL在化学信息学中另一个有趣的应用是通过神经网络产生新的化学结构。Gómez-Bombarelli等提出了一种使用变分自动编码器(VAE)生成化学结构的新方法。第一步是使用VAE进行无监督学习,将ZINC数据库中的化学结构(SMILES字符串)映射到潜在空间。一旦VAE训练完成,潜在空间中的潜在载体就成为分子结构的连续表示,并且可以通过训练好的VAE可逆地转化为SMILES字符串。通过任何优化方法搜索连续潜在空间中的最优潜在解,然后将搜索到的潜在解解码为SMILES,可以实现具有期望特性的新结构的生成。继Gómez-Bombarelli的作品之后,Kadurin 等人使用VAE作为分子描述符发生器与生成敌对网络(GAN)耦合,一种特殊的神经网络架构以产生新的结构。布拉施克等利用VAE产生具有预测的抗多巴胺受体 2型活性的新型结构。
RNN在自然语言处理领域一直非常成功。Segler 等人报道他们的研究使用RNNs来产生新的化学结构。在大量SMILES字符串上训练RNN之后,RNN方法在生成未包含在训练集中的新有效SMILES字符串方面出人意料地发挥了非常好的作用。RNN通过学习SMILES字符串中字符的潜在概率分布来写结构上有效的SMILES ,在这种情况下,RNN可以被看作是分子结构的生成模型。Segler 等还探讨了使用RNN生成特定目标文库的可能性,方法是首先通过对一小部分特定目标活性化合物进行转移学习,首先训练一般先验模型,然后进行精细调整的重点模型。在对两种抗生素靶标进行回顾性分析的研究中,他们的重点模型能够产生金黄色葡萄球菌 18%看不见的真正活性物和恶性疟原虫28%。
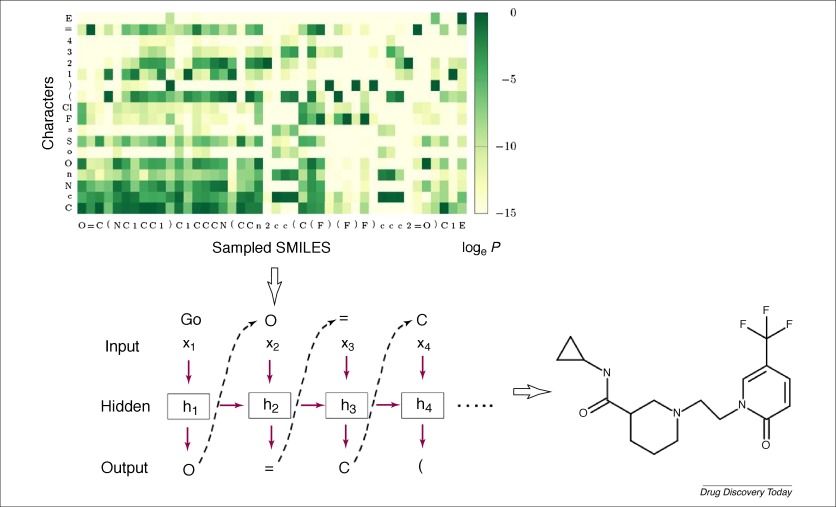
Jaques等人将一种名为Deep Q-learning的强化学习技术与RNN一起应用,生成具有理想分子特性的SMILES。然而,他们的方法需要一种奖励功能,其结合手写规则来惩罚不良类型的结构,否则将导致对奖励的利用,从而导致不现实的简单分子。为了克服这个缺点,Olivecrona等提出了一种基于策略的强化学习方法来调整预先训练的RNN,以产生具有给定用户定义属性的分子。在一个测试实例中,将模型调整为产生预测对多巴胺受体2型有活性的化合物,该模型产生的结构中> 95%被预测为活性的。
五、深度学习在预测反应和逆合成分析中的应用
综合预测的历史可以追溯到20世纪60年代的基于规则的方法。最近在使用DL方法的反应预测中报告了一些有希望的结果。尽管没有与其他机器学习方法进行明确比较,但结果表明,DL可以实现与基于规则的方法相媲美的性能或优于基于规则的方法。概括地说,机器学习可以解决两类问题:一种类型是正向反应预测,其中产物预测给定一组反应物,而另一种类型是反向合成预测,其中给出最终产物,预测产物的反应步骤。Coley 等人根据美国专利的15 000个反应的训练集,利用NN对一组反应的候选产品进行排序。将反应分类为模板,并且训练后的模型正确地将主要产品等级为1 分配为71.8%,等级≤3分别为86.7%和等级≤5分别为90.8%。为了克服基于模板的反应预测方法所面临的覆盖率和效率问题,在同一研究组的后续研究中提出了无模板方法。他们使用Weisfeiler-Lehman差异网络对生成的候选反应进行评分,并且与基于反应模板的方法相比,实现了卓越的性能。Segler 等人使用350万个反应作为DNN的训练集。反应预测的前十位准确率为97%,逆合成分析的准确率为95%。另一项研究中,他们将策略网络和蒙特卡罗树搜索结合起来,利用由科学文献中的1200万反应组成的训练集进行逆合成预测。他们的系统可以像基于规则的方法那样解决两倍于分子的重新合成计划。
六、卷积神经网络在预测配体-蛋白质相互作用中的应用
评估蛋白质和配体之间的相互作用是分子对接计划的关键部分,并且基于力场或现有蛋白质-配体复合物结构的知识开发了许多评分函数。受到CNN在图像分析中成功的启发,最近发表了几篇关于应用CNN评分蛋白质-配体相互作用的研究。一个典型的例子是由Ragoza等人进行的研究蛋白质-配体结构被离散成分辨率为0.5的网格。栅格的每边都是24 埃,并以结合位点为中心。用一个函数描述每个原子,并且生成网格上的原子密度以形成输入矩阵。使用Caffe DL框架定义和训练多层CNN模型。CNN评分在CSAR靶标间姿势预测数据集 上优于AutoDock Vina,但对姿势的靶标内部排名表现更差。虽然卷积网络已经取得了一些令人鼓舞的结果,但与目前使用的评分函数相比,他们是否能持续改进结果还不清楚。
七、化学信息学中的基准数据集
图像识别领域的快速发展不仅可以归因于新算法的出现,而且可以归因于典型和大型数据集的存在。标准化数据集将使社区能够方便地对开发的机器学习方法进行基准测试或评估。每年ImageNet大规模视觉识别竞赛(ILSVRC)已经见证了许多有影响力的CNN体系结构的诞生。
虽然有几个开源的化学信息学数据集可用,但由于这些数据集的规模有限,缺乏多种分离培训和测试集的方式,它们对机器学习方法开发的影响仍然有限,更重要的是,缺乏提议的新算法的标准评估平台。通过WordNet的启发和ImageNet 等人通过策划许多不同的集合,包括量子力学、物理化学、生物物理学和生理数据集,并开发一套实现许多已知分子表示和机器学习算法的软件,推出了MoleculeNet数据集。MoleculeNet建立在开源软件包DeepChem上,可以轻松访问DeepChem中现有的一些流行的DL算法。这将在很大程度上促进未来新型机器学习算法的比较和开发。
八、深度学习在生物成像分析中的应用
药物发现过程中,生物成像和图像分析广泛应用于从临床前研发到临床试验的各个阶段。成像使科学家能够看到宿主(人或动物)、器官、组织、细胞和亚细胞组分的表型和行为。通过数字图像分析,揭示了隐藏的生物学和病理学以及药物作用机制。成像模式的实例是荧光标记的或未标记的显微图像、计算机断层扫描(CT)、MRI、正电子发射断层扫描(PET)、组织病理学成像和质谱成像(MSI)。DL也在生物图像分析方面取得成功,许多研究报告与经典分类器相比具有优越的性能。
对于显微图像,已使用CNNs对单个荧光标记细胞进行分割和亚型分型,以及来自相位缩小显微镜的未标记图像。临床前设置的其他传统艰巨任务,如细胞追踪和菌落计数,也可以使用DL自动进行。由于组织形态丰富,与荧光标记图像相比,来自组织病理学的图像本质上通常是复杂的。尽管如此,在细胞水平上,用苏木精和曙红(H&E)染色染色的乳腺和结肠组织可以实现单个细胞的分割和分类。在组织区域水平,通过DL鉴定来自H&E染色的乳房组织的肿瘤区域,而白细胞和脂肪组织的额外类别也可以被识别。除了基本的图像分割,DL已经被用于H&E和免疫组织化学染色组织的组织病理学诊断。
DL的应用也用于CT、MRI和PET成像的分析。除了图像分割和分类的流行应用外,其实程序还在基于内容的图像检索中,并且据报道DL方法胜过了流行的ISOMAP和弹性网方法。
对于新兴的MSI,类似于DL在组织病理学中的应用,肿瘤亚型可以通过高分辨率基质辅助激光解吸/电离(MALDI)MSI进行。鉴于MSI可以将组织的代谢信息可视化,已经可以通过DL检测到具有解吸电喷雾电离(DESI)MSI 代谢异质性的肿瘤的亚区域。最后,在一个不寻常的成像领域:流式细胞术,DL使细胞分类实时用于高通量应用。用于成像的DNN训练非常耗时且需要专门的GPU处理。此外,在高通量成像筛查的情况下,高质量的训练集很少见。
九、未来药物发现深度学习的发展
机器学习方法和DL通常需要大数据集来训练;然而,人脑只有几个例子才有学习的能力。如何只用少量的可用数据进行学习是机器学习中最热门的话题之一。利用辅助数据改进仅有少数数据点的模型的DL示例是匹配网络,其被提出作为单次学习的变体。当包括辅助数据时获得改进的结果。像一次性学习这样的方法与药物发现有关,药物化学家通常在可用数据有限的情况下开展新靶点研究。Altae-Tran等在化学信息学数据集上使用LSTM方法来构建具有非常小的训练集的模型,并且报告了有希望的结果。最近,DL在记忆增广神经网络中使用了一种新型架构,用可微分神经计算机(DNC)显着改善了这种结构。已经将DNCs应用于几个问题,如问答系统和查找图表中的最短路径。然而,这些更先进的架构迄今尚未应用于药物研发。
结语
机器学习自20世纪90年代后期以来一直用于药物研发,并已成为药物发现的有用工具。机器学习工具最近的一个扩展是DL;与其他方法相比,DL具有更灵活的架构,因此可以创建针对特定问题量身定制的NN架构。缺点是DL通常需要非常大的训练集。一个相关的问题是:DL是否优于其他机器学习方法?我们认为现在得出任何确定的结论还为时尚早,迄今为止的结果表明,DL对于图像分析等特定任务来说是优越的,对于de novo分子设计和反应预测非常有用。对于具有结构化输入描述符的任务,DL似乎至少与其他方法一样。最相关的例子是生物活性预测,DL似乎通过多任务学习实现了更好的整体表现。但是,其他机器学习方法也在不断改进。因此,实际上用于生物活性预测的方法的选择可能取决于建模者最熟悉的方法。如果不同的机器学习方法达到大致相同的精度,那么使用机器学习模型可以实现的限制可能取决于数据和数据集大小的实验不确定性,而不是所使用的具体算法。
参考资料