一、前言
上一篇我们讲了关于数组的二分查找算法,数据结构与算法分析:(九)二分查找算法。二分查找的底层依赖的是数组随机访问的特性,所以只能用数组来实现。如果数据存储在链表中,就真的没法用二分查找算法了吗?
答案是有办法的,我们只需要对链表稍加改造,就可以支持二分查找算法,改造后的数据结构我们称之为跳表(Skip List)。
我们先说下跳表这个数据结构的优缺点后再来分析详细过程。
对于一个需要频繁插入、删除的线性有序结构,如何使插入、删除的速度提升?
1、优点:
- 对于单向链表,只能从头到尾遍历,时间复杂度为O(n)。
- 对于数组,删除、插入复杂度太高O(n),还会涉及数组的扩容操作。
- 平衡二叉树查询速度很快,但是需要平衡的操作开销很大。
- 红黑树的话,性能差不多,但是如果需要多进程同时访问修改的话,红黑树有个平衡的过程,争锁代价也比较大。
- 跳表的线程安全也是通过cas锁实现的,跳表的构建相对简单,同时支持范围查找。
2、缺点:
- 相对于红黑树,空间消耗增加。
我们后端经常用的 Redis 中的有序集合就是用跳表来实现的。如果你有一定基础,应该知道红黑树也可以实现快速的插入、删除和查找操作。那 Redis 为什么会选择用跳表来实现有序集合呢? 为什么不用红黑树呢?这篇讲完后,相信你心中会有一个答案了。
二、如何理解跳表
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。

那怎么来提高查找效率呢?请看我下面画的图,在该链表中,每隔一个节点就有一个附加的指向它在表中前两个位置上的节点的链,正因为如此,在最坏的情形下,最多考察 n/2 + 1 个节点。比如我们要查90这个节点,按照之前单链表的查找的话要8个节点,现在只需5个节点。

我们来将这种想法扩展一下,得到下面的图,这里每隔4个节点就有一个链接到该节点前方的下一个第4节点的链,只有 n/4 + 1 个节点被考察
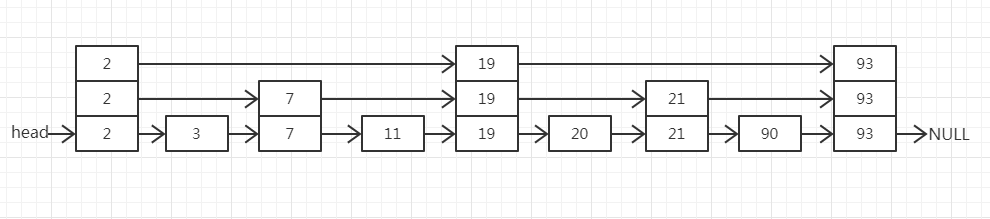
这里我们利用数学的思想,针对通用性做扩展。每隔第 2^i 个节点就有一个链接到这个节点前方下一个第 2 ^i 个节点链。链的总个数仅仅是加倍,但现在在一次查找中最多只考察 logn 个节点。不难看到一次查找的总时间消耗为 O(logn),这是因为查找由向前到一个新的节点或者在同一节点下降到低一级的链组成。在一次查找期间每一步总的时间消耗最对为 O(logn)。注意,在这种数据结构中的查找基本上是折半查找(Binary Search)。
我只举了两个例子,这里你可以自己想象下大量数据也就是链表长度为 n 的时候,查找的效率更加的凸显出来了。
这种链表加多级索引的的结构,就是跳表。接下来我们来定量的分析下,用跳表查询到底有多快。
三、跳表的时间复杂度分析
我们知道,在一个单链表中查询某个数据的时间复杂度是 O(n)。那在一个具有多级索引的跳表中,查询某个数据的时间复杂度是多少呢?
我把问题分解一下,先来看这样一个问题,如果链表里有 n 个结点,会有多少级索引呢?
按照我们上面讲的,第一级索引的链节点个数大约就是 n/2 个,第二级索引的链节点个数大约就是 n/4 个,第三级索引的链节点个数大约就是 n/8 个,依次类推,也就是说,第 k 级索引的链节点个数是第 k-1 级索引的链节点个数的 1/2,那第 k 级索引节点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个节点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个节点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
那这个 m 的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3,为什么是 3 呢?我来解释一下。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到y节点之后,发现 x 大于 y,小于后面的节点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个节点(包含 y 和 z),所以,我们在 k-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个节点。
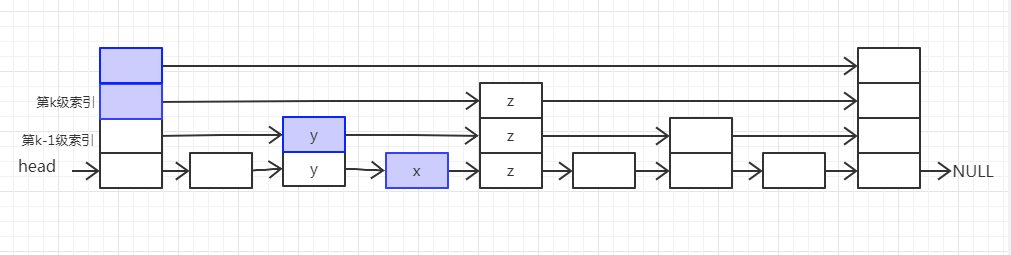
通过上面的分析,我们得到 m=3,所以在跳表中查询任意数据的时间复杂度就是 O(logn)。这个查找的时间复杂度跟二分查找是一样的。换句话说,我们其实是基于单链表实现了二分查找,前提是建立了很多级索引,也就是我们讲过的空间换时间的设计思路。
我们的时间复杂度很优秀,那跳表的空间复杂度是多少呢?
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
四、跳表的插入和删除
实际上,跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 O(logn)。我们就来看下,如何在跳表中插入一个数据,以及它是如何做到 O(logn) 的时间复杂度的?
我们知道,在单链表中,一旦定位好要插入的位置,插入节点的时间复杂度是很低的,就是 O(1)。但是,这里为了保证原始链表中数据的有序性,我们需要先找到要插入的位置,这个查找操作就会比较耗时。
对于纯粹的单链表,需要遍历每个结点,来找到插入的位置。但是,对于跳表来说,我们讲过查找某个节点的的时间复杂度是 O(logn),所以这里查找某个数据应该插入的位置,方法也是类似的,时间复杂度也是 O(logn)。
我们再来看删除操作。
如果这个节点在索引中也有出现,我们除了要删除原始链表中的节点,还要删除索引中的。因为单链表中的删除操作需要拿到要删除节点的前驱节点,然后通过指针操作完成删除。所以在查找要删除的节点的时候,一定要获取前驱节点。当然,如果我们用的是双向链表,就不需要考虑这个问题了。
五、跳表的代码实现
/**
* 跳表代码实现
* 跳表中存储的是正整数,并且存储的是不重复的。
*/
public class SkipList {
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
// 带头链表
private Node head = new Node(MAX_LEVEL);
private Random random = new Random();
public Node find(int value) {
Node cur = head;
// 从最大层开始查找,找到前一节点,通过--i,移动到下层再开始查找
for (int i = levelCount - 1; i >= 0; i--) {
while (cur.forwards[i] != null && cur.forwards[i].data < value) {
// 找到前一节点
cur = cur.forwards[i];
}
}
if (cur.forwards[0] != null && cur.forwards[0].data == value) {
return cur.forwards[0];
} else {
return null;
}
}
/**
* 优化插入版本
* @param value
*/
public void insert(int value) {
int level = head.forwards[0] == null ? 1 : randomLevel();
// 每次只增加一层,如果条件满足
if (level > levelCount) {
level = ++levelCount;
}
Node newNode = new Node(level);
newNode.data = value;
Node cur = head;
// 从最大层开始查找,找到前一节点,通过--i,移动到下层再开始查找
for (int i = levelCount - 1; i >= 0; --i) {
while (cur.forwards[i] != null && cur.forwards[i].data < value) {
// 找到前一节点
cur = cur.forwards[i];
}
// levelCount 会 > level,所以加上判断
if (level > i) {
if (cur.forwards[i] == null) {
cur.forwards[i] = newNode;
} else {
Node next = cur.forwards[i];
cur.forwards[i] = newNode;
newNode.forwards[i] = next;
}
}
}
}
public void delete(int value) {
Node[] update = new Node[levelCount];
Node cur = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (cur.forwards[i] != null && cur.forwards[i].data < value) {
cur = cur.forwards[i];
}
update[i] = cur;
}
if (cur.forwards[0] != null && cur.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null && update[i].forwards[i].data == value) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
}
/**
* 随机 level 次,如果是奇数层数 +1,防止伪随机
*/
private int randomLevel() {
int level = 1;
for (int i = 1; i < MAX_LEVEL; ++i) {
if (random.nextInt() % 2 == 1) {
level++;
}
}
return level;
}
/**
* 打印每个节点数据和最大层数
*/
public void printAll() {
Node cur = head;
while (cur.forwards[0] != null) {
System.out.print(cur.forwards[0] + " ");
cur = cur.forwards[0];
}
System.out.println();
}
/**
* 打印所有数据
*/
public void printAll_beautiful() {
Node p = head;
Node[] c = p.forwards;
Node[] d = c;
int maxLevel = c.length;
for (int i = maxLevel - 1; i >= 0; i--) {
do {
System.out.print((d[i] != null ? d[i].data : null) + ":" + i + "-------");
} while (d[i] != null && (d = d[i].forwards)[i] != null);
System.out.println();
d = c;
}
}
/**
* 跳表的节点,每个节点记录了当前节点数据和所在层数数据
*/
public class Node {
private int data = -1;
/**
* 表示当前节点位置的下一个节点所有层的数据,从上层切换到下层,就是数组下标-1,
* forwards[3]表示当前节点在第三层的下一个节点。
*/
private Node forwards[];
/**
* 这个值其实可以不用,看优化insert()
*/
private int maxLevel = 0;
public Node(int level) {
forwards = new Node[level];
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
public static void main(String[] args) {
SkipList list = new SkipList();
list.insert(1);
list.insert(2);
list.insert(6);
list.insert(7);
list.insert(8);
list.insert(3);
list.insert(4);
list.insert(5);
System.out.println();
list.printAll_beautiful();
}
}
输出结果:
null:15-------
null:14-------
null:13-------
null:12-------
null:11-------
null:10-------
null:9-------
null:8-------
null:7-------
null:6-------
null:5-------
3:4-------
3:3-------4:3-------5:3-------7:3-------
3:2-------4:2-------5:2-------6:2-------7:2-------8:2-------
2:1-------3:1-------4:1-------5:1-------6:1-------7:1-------8:1-------
1:0-------2:0-------3:0-------4:0-------5:0-------6:0-------7:0-------8:0-------
Github代码地址:
六、知识拓展
为什么 Redis 要用跳表来实现有序集合,而不是红黑树?
性能:
- 插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
- 对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。这样做非常高效。
- 跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
内存占用:跳表的空间利用率还是很高的,加上Redis并非使用普通的跳表结构,协调相关参数,比如层数,节点元素数等。
不过,跳表也不能完全替代红黑树。因为红黑树比跳表的出现要早一些,很多编程语言中的 Map 类型都是通过红黑树来实现的。我们做业务开发的时候,直接拿来用就可以了,不用费劲自己去实现一个红黑树,但是跳表并没有一个现成的实现,所以在开发中,如果你想使用跳表,必须要自己手动实现。
