两者简介:
HashMap简介:
HashMap是基于哈希表实现的,每一个元素是一个key(数据类型必须一致)-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
HashMap 实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
HashMap存数据的过程是:
HashMap内部维护了一个存储数据的Entry数组,HashMap采用链表解决冲突,每一个Entry本质上是一个单向链表。当准备添加一个key-value对时,首先通过hash(key)方法计算hash值,然后通过indexFor(hash,length)求该key-value对的存储位置,计算方法是先用hash&0x7FFFFFFF后,再对length取模,这就保证每一个key-value对都能存入HashMap中,当计算出的位置相同时,由于存入位置是一个链表,则把这个key-value对插入链表头。
HashMap中key和value都允许为null。key为null的键值对永远都放在以table[0]为头结点的链表中。
了解了数据的存储,那么数据的读取也就很容易就明白了。
HashMap内存储数据的Entry数组默认是16,如果没有对Entry扩容机制的话,当存储的数据一多,Entry内部的链表会很长,这就失去了HashMap的存储意义了。所以HasnMap内部有自己的扩容机制。HashMap内部有:
变量size,它记录HashMap的底层数组中已用槽的数量;
变量threshold,它是HashMap的阈值,用于判断是否需要调整HashMap的容量 (threshold = 容量*加载因子)
变量DEFAULT_LOAD_FACTOR = 0.75f,默认加载因子为0.75
HashMap扩容的条件是:当size大于threshold时,对HashMap进行扩容

HashTable简介:
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
两者区别:
1.继承性有所不同:


前者是继承于AbstractMap,而后者则是继承于Dictionary,两者均属于java.util工具包,且二者都能实现了Map接口,对于什么时候用HashMap和什么时候用HashTable就得考虑多个方面的问题
比如存储扩容,以及线程安全问题!
2.线程安全问题:
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的如下图所示:
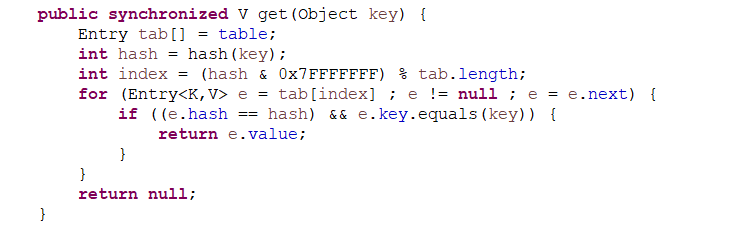

在看源码的过程当中,大部分都是用Synchronize修饰的,在使用多线程的时候就不需要自己写代码实现这个过程,只需要调用HashTable即可,省去很大部分的时间!
3Hash值不同


HashTable是使用 对象的Hash值,而HashMap则是重新进行计算获取!
4扩容方式的不同
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
5 key和value值是否初始值允许为空
hashMap是允许为空而hashTable必须要有初始化值存在才能得以运行否则会出行错误!
两者涵盖的方法这里我就不说了,看底层源码提供的方法则一目了然如下图:
hashTable hashMap
hashMap