JDK1.7和1.8 HashMap区别:
1.数组+链表改成了数组+链表或红黑树;
2.表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后;
3.在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容
4.扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
原因:
1.防止发生hash冲突,链表长度过长,将时间复杂度由O(n)降为O(logn);
2.因为1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环;
A线程在插入节点B,B线程也在插入,遇到容量不够开始扩容,重新hash,放置元素,采用头插法,后遍历到的B节点放入了头部,这样形成了环,如下图所示:

1.7的扩容调用transfer代码,如下所示:
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; //A线程如果执行到这一行挂起,B线程开始进行扩容 newTable[i] = e; e = next; } } }
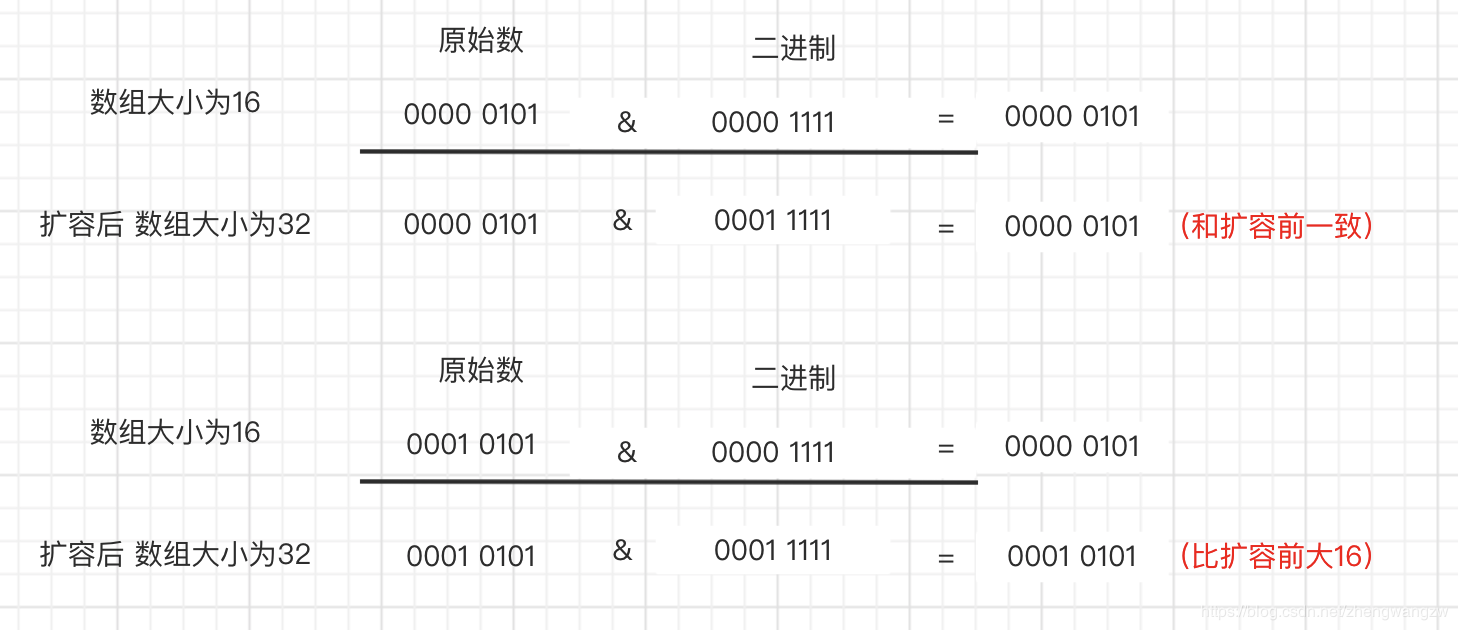
3.扩容的时候为什么1.8 不用重新hash就可以直接定位原节点在新数据的位置呢?
这是由于扩容是扩大为原数组大小的2倍,用于计算数组位置的掩码仅仅只是高位多了一个1,怎么理解呢?
扩容前长度为16,用于计算(n-1) & hash 的二进制n-1为0000 1111,扩容为32后的二进制就高位多了1,为0001 1111。
因为是& 运算,1和任何数 & 都是它本身,那就分二种情况,如下图:原数据hashcode高位第4位为0和高位为1的情况;
第四位高位为0,重新hash数值不变,第四位为1,重新hash数值比原来大16(旧数组的容量)
参考博客: