linux之零拷贝(ZeroCopy)
传统的数据传输方式:
像这种在文件读取数据然后将数据通过网络传输给其他的程序的方式(大部分应用服务器都是这种方式,包括web服务器处理静态内容时,ftp服务器,邮件服务器等等)其核心操作就是如下两个调用:
File.read(fileDesc,buf,len);
File.send(socket,buf,len);其上操作看上去只有两个简单的调用,但是其内部过程却要经历四次用户态和内核态的切换以及四次的数据复制操作。
图一展示了数据从文件到socket的内部过程:

图二是用户态和内核态的切换过程:
这些步骤涉及到如下过程:
- read()的调用引起了从用户态到内核态的切换(看图二),内部是通过sys_read()(或者类似的方法)发起对文件数据的读取。数据的第一次复制是通过DMA(直接内存访问)将磁盘上的数据复制到内核空间的缓冲区中。
- 数据从内核空间的缓冲区复制到用户空间的缓冲区后,read()方法也就返回了。此时内核态又切换回用户态,现在数据也已经复制到了用户地址空间的缓冲区中。
- socket的send()方法的调用又引起了用户态到内核态的切换,第三次数据复制有将数据从用户空间缓冲区复制到了内核空间的缓冲区,这次数据被放在了不同于之前的内核缓冲区中,这个缓冲区与数据将要被传输到socket关联。
- send()系统调用返回后,就产生了第四次用户态和内核态的切换。随着DMA单独异步的将数据从内核态的缓冲区中传输到协议引擎发送到网络上,有了第四次数据的复制。
使用内核空间的缓冲区做中介(而不是直接将数据传输到用户空间)或许看上去是低效的,然而内核缓冲区做中介的引入就是为了改善进程的性能,从当前 应用程序读取文件数据这方面来说,如果读取的数据小于这个中介的缓冲区的容量,那么中介缓冲区可以用来实现异步功能(当数据缓冲区数据满了之后再写上去,较少的系统调用次数)。
不幸的是,这种方式也有它自己的瓶颈。当应用程序读取的数据比这个中介缓冲区的容量大很多的时候,数据就会在磁盘、内核空间、用户空间之间复制多次后才最终被传给应用程序。
零拷贝技术就是通过消除这种多余的数据拷贝来改善性能的。
使用Zero Copy的数据传输方式
如果你再看一下传统的方式,你会发现实际上第二次和第三次数据拷贝是没有必要的。应用程序除了缓存一下数据然后传回到socket的缓冲区中啥也没干。我们可以通过直接从内核缓冲区把数据传输到socket关联的缓冲区来替代传统的方式。transferTo()方法可以帮你实现。下面是这个方法的定义:
public void transferTo(long position, long count, WritableByteChannel target);transferTo()方法将数据从一个channel传输到另一个可写的channel上,其内部实现依赖于操作系统对zero copy技术的支持。在unix操作系统和各种linux发行版本中,这种功能最终是通过sendfile()系统调用实现。下面就是这个方法的定义:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);可以通过调用transferTo()方法来替代上面的File.read() Socket.send()
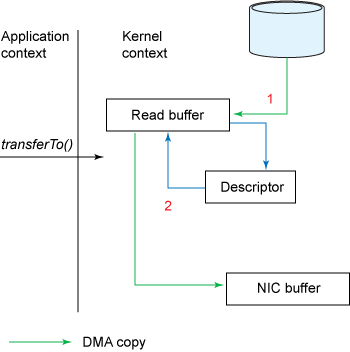
transferTo(position,count,WritableChannel);下图展示了通过transferTo实现数据传输的路径:

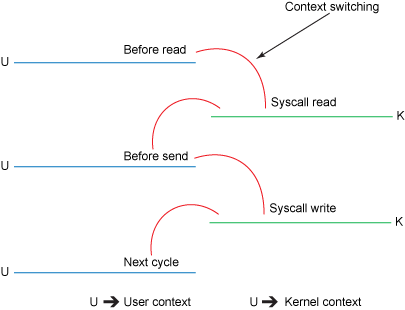
下图展示了内核态、用户态的切换情况:

使用transferTo()方式所经历的步骤:
- transferTo调用会引起DMA将文件内容 复制到缓冲区(内核空间的缓冲区),然后数据从这个缓冲区复制到另一个与socket输出相关的内核缓冲区中。
- 第三次数据复制就是DMA把socket关联的缓冲区中的数据复制到协议引擎上发送到网络上。
这次改善,我们是通过将内核、用户态切换的次数从四次减少到两次,将数据的复制次数从四次减少到三次(只有一次用到cpu资源)。但这并没有达到我们零复制的目标。如果底层网络适配器支持收集操作的话,我们可以进一步减少内核对数据的复制次数,在内核为2.4或者以上版本的linux系统上,socket缓冲区描述符将被用来满足这个需求。这个方式不仅减少了内核态与用户态之间的切换,而且省去了那次需要cpu参与的复制过程。从用户的角度来看依旧是调用transferTo方法,但是本质发生了变化:
1. 调用transferTo方法后数据被DMA从文件复制到了内核的一个缓冲区中。
2. 数据不再被复制到socket关联的缓冲区中了,仅仅是将一个描述符(包含了数据的位置和长度等信息)追加到socket关联的缓冲区中。DMA直接将内核中的缓冲区中的数据传输给协议引擎,消除了仅剩的一次需要cpu周期的数据复制。
下图展示了transferTo的工作流程