之前写过一篇关于零样本学习的博客,当时写的比较浅。后来导师让我弄个ppt去给本科生做一个关于Zero Shot Learning 的报告,我重新总结了一下,添加了一些新的内容,讲课的效果应该还不错,这里就再写一篇作为相关内容的扩展
一、预备知识及问题陈述
1.1 预备知识-计算机视觉里的识别问题
为了方便介绍我们的零样本问题,这里先简单介绍一下计算机视觉里我们通常所指的识别问题

上图 (markdown好想出了点问题,不能居中了,难受…) 展示了我们熟悉的人脸识别问题,包括图片中人的身份,年龄,以及人脸在图片中的位置等。
解决这样的人脸识别问题,我们可以总结出一个简单的模式
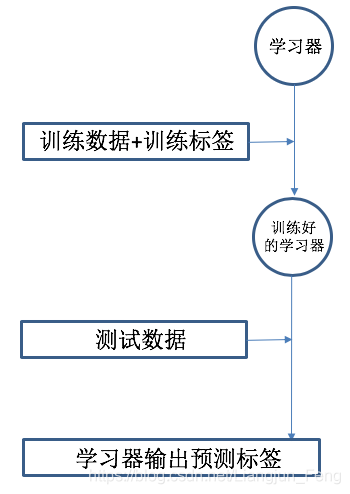
即,首先选择一个合适的学习器 (现在在视觉里通常都是CNN),为这个学习器准备充足的训练数据和对应的标签,利用训练数据训练该学习器。在实际使用时,将测试数据输入到训练好的学习器中,学习器就可以输出测试数据对应的标签。这里值得一提的是,这种一般的模式,在测试时,学习器只能预测训练集中已有的类别。
1.2 零样本学习的问题描述
我们通过例子来讲解零样本学习的问题
现在我们有了六组训练数据如下:

它们分别是马,驴,老虎,鬣狗,企鹅和熊猫,每一类别的数据都有成千上万张充足的图片作为训练数据
然而,现在在零样本学习任务中,我们的测试数据是这样的

我们已经知道测试时候会有斑马和犀牛两类图片,零样本学习要求在测试时对于输入的图片,辨别其是斑马还是犀牛。
这就是零样本学习的一个具体描述,与一般的识别问题的不同点在于,其 测试集的类别与训练集的类别不存在交集,按照之前总结的简单流程是没有办法解决零样本问题的,需要寻找新的方法。
二、ZSL的提出及若干模型
2.1 基于物体属性的预测
Lampert C H, Nickisch H, Harmeling S. Learning to detect unseen object classes by between-class attribute transfer[M]. IEEE, 2009. 这篇论文提出了零样本学习的概念并给出了最初的解决方法,称为类间属性迁移
我们用下图来说明该方法的主要思路
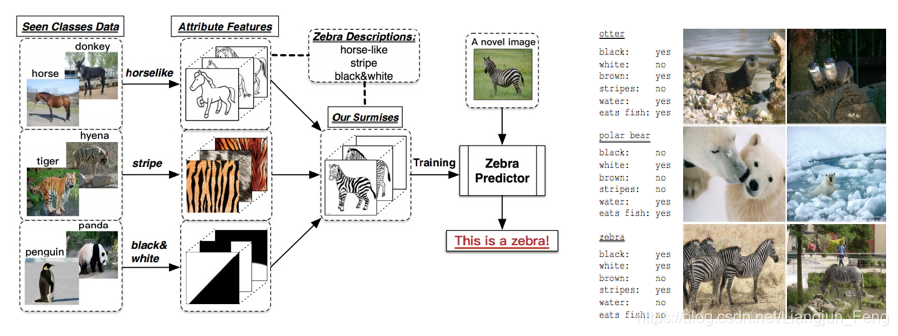
我们之前所给出的六类训练数据并不是胡乱给出的,根据上图我们可以看出,我们可以利用一个学习器,学习出一个动物是否具有马的外形,利用第二个学习器学习出一个动物是否具有斑纹,利用第三个学习器学习一个动物是否具有黑白间隔的颜色。
当一张斑马的图片分别输入到这三个学习器之后,我们可以得到这张图片里的动物具有马的外形,斑纹以及黑白间隔的颜色。如果此时我们有一张表,这张表里记录着每一种动物这三种属性的取值,我们就可以通过查表的方式,将这张图片对应到斑马这一类别
这里的属性表,是可以事先总结好的,因为收集大量的未知类别的图片是困难的,但是仅仅总结每一类别相应的属性却是可行的
类间属性迁移的核心思想在于:
虽然物体的类别不同,但是物体间存在相同的属性,提炼出每一类别对应的属性并利用若干个学习器学习。在测试时对测试数据的属性预测,再将预测出的属性组合,对应到类别,实现对测试数据的类别预测
2.2 词向量与语义输出编码模型
词向量(word2vec)是指将自然语言中的字词转为计算机可以理解的数字向量,并且其中意思相近的词将被映射到向量空间中相近的位置。我们来看一个简单的例子

如上图,如果我们把北京、上海、东京、华盛顿、纽约五个城市的单词转化为2维的词向量,我们可以发现它们在平面内的分布在距离上是和实际空间相似的,北京上海东京离的比较近,纽约和华盛顿离的比较近
回到我们的问题上,
驴和马谁离斑马比较近?
老虎和老鹰谁离家猫比较近?
如果我们将原先的表示类别的词(马、驴、老虎等)编码为词向量,那么我们就可以用距离来衡量一个未知的词向量的归属
语义输出编码的核心思想在于:
将训练标签编码为词向量,基于训练数据和词向量训练学习器。测试时输入测试数据,输出为预测的词向量,计算预测结果与未知类别词向量的距离,数据距离最近的类别
由以上两个模型,我们可以总结出一个零样本学习的简单模式
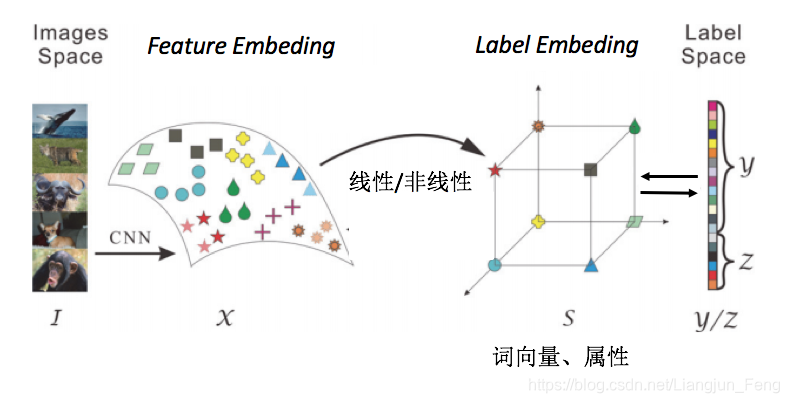
上图中,images space和label space分别为初始的图像空间和标签空间,在零样本学习中,一般会通过一些方法将图片映射到特征空间中,这个空间称为feature embeding;同样的标签也会被映射到一个label embeding当中,学习feature embeding和label embeding中的线性或非线性关系用于测试时的预测转化取代之前的直接由images space 到 label space的学习
2.3 Discriminative learning of latent feature
之前我们讲了两种比较基础的方法并总结了零样本学习的一般模式,现在再来讲一个相对复杂的模型,这一模型称为 Discriminative learning of latent feature,源于论文
Li Y, Zhang J, Zhang J, et al. Discriminative Learning of Latent Features for Zero-Shot Recognition[J]. 2018.
相比于类间属性迁移方法,它主要增加了两个思路:
(1)设计了专门的网络找到图片中目标的主体部分
(2)出了利用人工标注的属性,还从原始图片中搜索潜在属性加入label embeding
模型示意图如下:
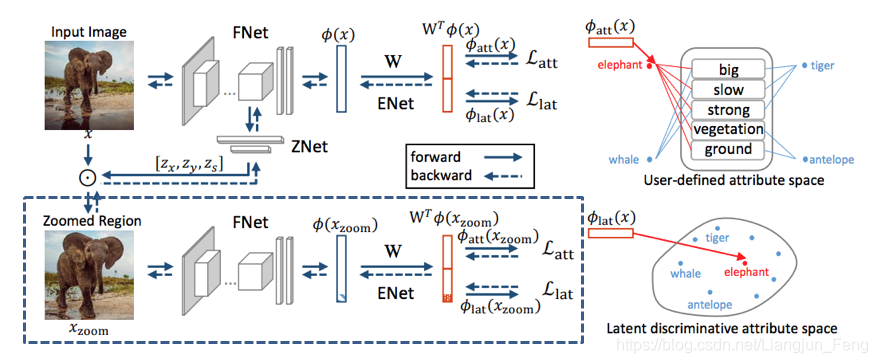
模型看似复杂,其实还是基于之前总结的模式的
-
首先看左下角被蓝色虚线框出的模块,首先大象表示的是被圈出的图像主体部分(我们先不考虑怎样圈出的,后续会介绍),该原始图像通过一个特征提取网络FNet提取出特征,该特征通过一个ENet对右边的label embeding进行学习。这一模式和我们之前总结的是一样的,只是这里除了我们之前提到的 (人工标注的特征) 还有 (学习得到的潜在特征,之后会介绍如何得到)
-
蓝色虚线框出了一个通道,该通道上面还有一个相似的通道,不同点在于,上面的通道输入的是原始图片而不是主体放大后的图片
-
两通道之间通过一个ZNet相连,这里的ZNet是找到主体的全链接网络,它从原始图片找到主体后将其作为下面通道的输入,两个通道同时进行训练,训练目标是使得同时在四个label( 两组 )上的损失达到最小
该模型的主要思路就是这样,接下来我们看两个问题:
-
图片中的主体部分是如何找到的?
主体部分可以被一个方框圈出,使用三个参数 表示这个方框。随机初始化三个参数,训练一个网络ZNet,当上述提到的四个label的loss达到最小的时候,找到的三个参数自然是最优的,对应到图片的主体部分
这里, 表示特征提取网络FNet的最后一个卷积层的输出,W则表示的是ZNet训练出的权重 -
怎样找到潜在的有差异性的特征
寻找的方式类似于费舍尔判别分析,即类间差异最大,类内差异最小,其目标函数可以立为
这里 表示的是欧式距离, 表示的是寻找潜在特征的函数, 是同类样本, 是不同类样本
三、General Zero Shot Learning 通用零样本学习
通用零样本学习要求准确预测 见过的和没见过的类别(ZSL只要求预测没有见过的类别)
这里介绍一个可以用于通用零样本学习的模型
Wang X, Ye Y, Gupta A. Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs[J]. 2018.
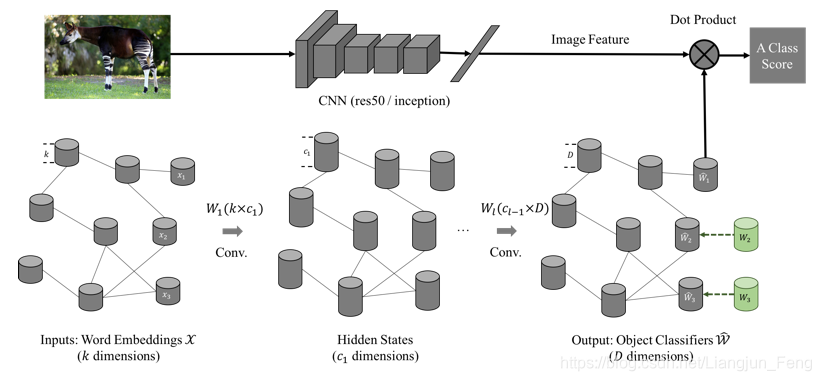
该方法的主要思路是:
首先利用训练数据和训练类别训练一个
。 再利用词向量作为输入,
作为标签,训练一个图卷积网络,利用该图卷积网络输入测试类别的词向量得到
。
和
一起组成学习器
实现对所有类别的预测
四、ZSL的发展现状
这里主要参考18年TPAMI上的的综述
Xian Y, Lampert C H, Schiele B, et al. Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
对于普通零样本识别(只要求预测未知类别)目前的方法有如下精度
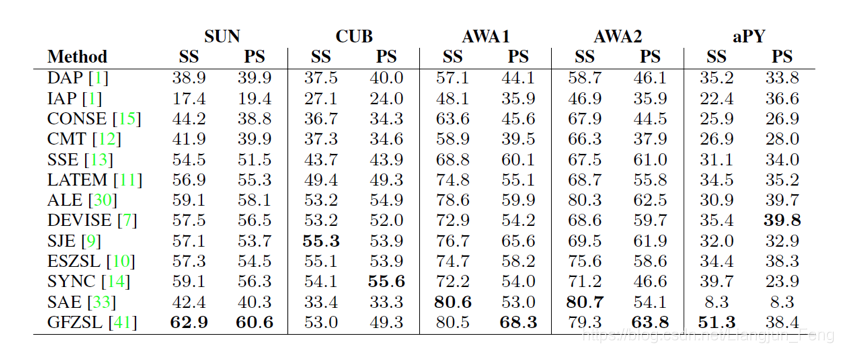
这里SUN、CUB、AWA1、AWA2、aPY表示5个数据集
SS、PS表示两种不同的已知、未知类别划分方式
对于通用零样本识别
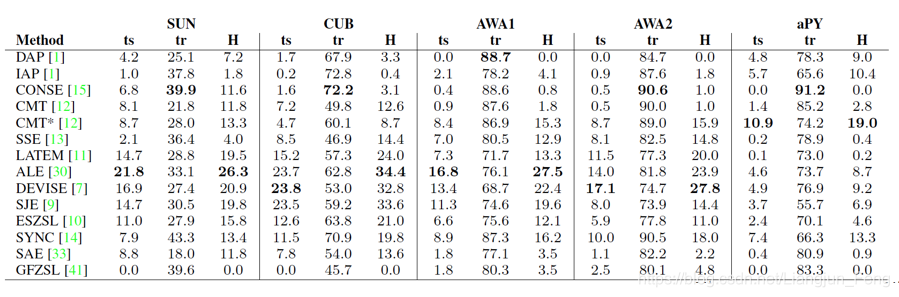
这里ts表示在未知类别上的精度,tr表示在已知类别上的精度,H是两者的综合指标
比较两表可以发现,通用零样本识别的难度远远高于普通的零样本识别,也是未来的重要工作方向之一
五、附数据集下载地址
AwA: http://pan.baidu.com/s/1nvPzsXb
CUB: http://pan.baidu.com/s/1nv3KCYH
aPaY: http://pan.baidu.com/s/1hseSzVe
SUN: http://pan.baidu.com/s/1gfAc33X
ImageNet2: http://pan.baidu.com/s/1pLfZYQ3
